初识WebMagic
用Java爬虫的话就不得不提Webmagic这个框架,这次来用Webmagic爬取自己的博客所有文章标题
WebMagic是一个简单方便的Java爬虫框架,其主要结构有下面四个部分组成:
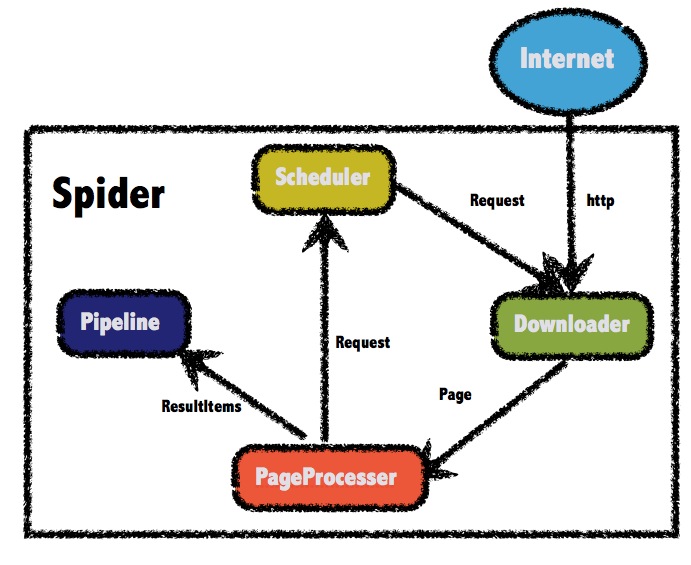
-
Downloader:Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。 -
PageProcessor:PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。 在这四个组件中,PageProcessor是我们需要实现的部分。 -
Scheduler:Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。 -
Pipeline:Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
爬取博主所有博客的标题
当然想爬取内容也是可以的
使用框架的第一步是引入依赖,本文使用maven:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
这里不得不提一下,作者貌似不再维护了,从17年到现在一直是0.7.3版本
既然是爬虫,我们就需要告诉爬虫爬哪、爬那些数据?因此创建一个MyProcessor类,实现PageProcessor接口:
package fun.psgame.demo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
public class MyProcessor implements PageProcessor {
@Override
public void process(Page page) {
}
@Override
public Site getSite() {
return null;
}
}
有两个方法需要实现:
第一个process(Page page)是我们得到目标页面之后要做的事,这里一般是进行信息筛选。
第二个是设置爬取行为,比如每隔多长时间访问一次网站(太快会出验证码甚至ban IP)、访问时UserAgent、Cookie是什么之类的。
首先,我们需要找到要爬取的数据所在的位置,进入博客首页,按F12,通过选择元素找到文章标题所在的位置:
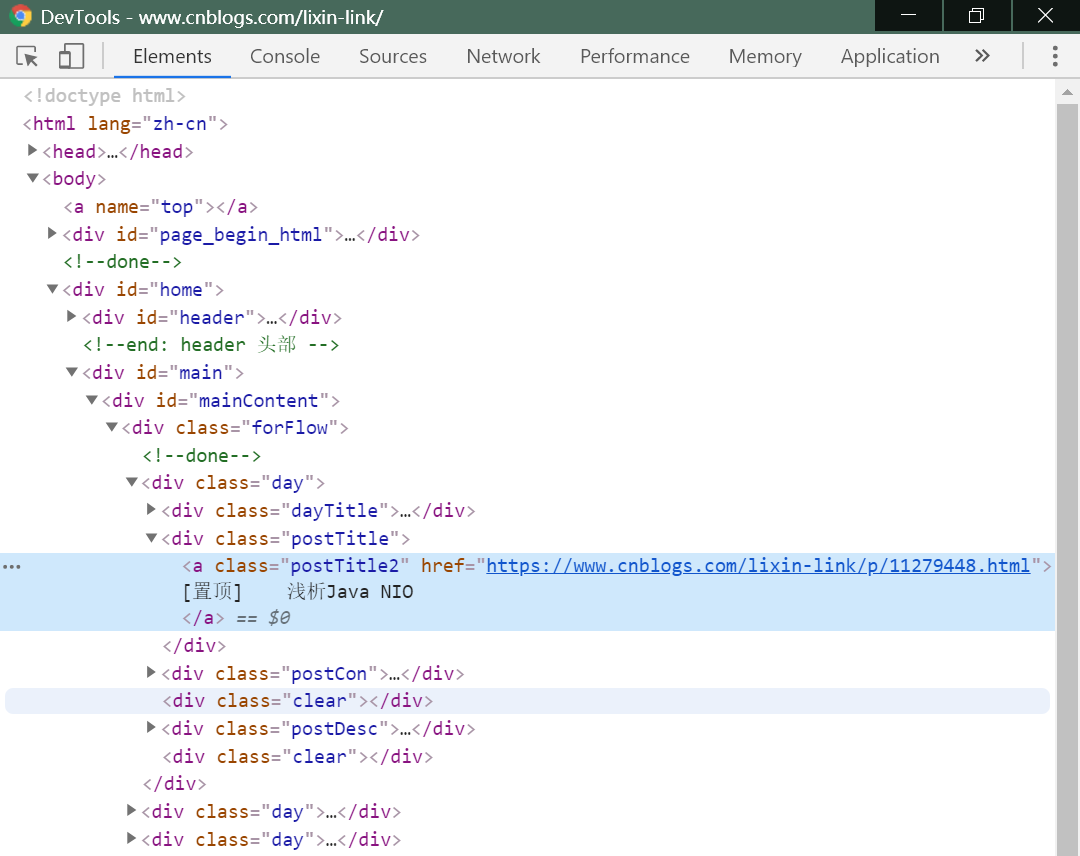
可以看到标题在postTitle属性div下的a标签里。
接着我们点击最下面的下一页,可以看到网页地址栏从https://www.cnblogs.com/lixin-link/变成了https://www.cnblogs.com/lixin-link/default.html?page=2,这个网址就是我们的目标URL。
因此开始实现MyProcessor类:
package fun.psgame.demo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.List;
public class MyProcessor implements PageProcessor {
//目标网址,信息都在这样的网址上,使用正则匹配
// .和?在正则里是保留字符,因此转义处理
public static final String TARGET_URL = "https://www\.cnblogs\.com/lixin-link/default\.html\?page=\d+";
//定义一个UA,模拟浏览器
public static final String USER_AGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31";
@Override
public void process(Page page) {
//找到页面里类似“下一页”这种符合的url,加入到要队列进行爬取
page.addTargetRequests(page.getHtml().links().regex(TARGET_URL).all());
//对每个爬取到的页面进行数据筛选
//这里使用了xpath语法,意思是找到class属性为forFlow的div标签的,下面的class属性为day的div标签的,下面的class属性为postTitle的div标签的,下的a标签的,文本内容,也就是标题所在的位置(也可以使用css语法进行筛选)
List<String> list = page.getHtml().xpath("//div[@class="forFlow"]/div[@class="day"]/div[@class="postTitle"]/a/text()").all();
//可以把标题打印出来
// list.forEach(System.out::println);
//也可以使用把结果放入page中,然后在入口方法中使用Pipeline处理
page.putField("标题列表", list);
}
@Override
public Site getSite() {
return Site.me()
.setSleepTime(1000)//间隔信息
.setUserAgent(USER_AGENT);//设置UA
}
public static void main(String[] args) {
//程序入口
Spider.create(new MyBlogProcessor())//要执行的Processor类
.addUrl("https://www.cnblogs.com/lixin-link/default.html?page=1")//目标url
.addPipeline(new ConsolePipeline())//通过Pipeline来对爬取到的数据进行处理,比如保存成文件,或者输出在控制台
.run();//开始方法
}
}
如果遇到javax.net.ssl.SSLException: Received fatal alert: protocol_version错误,请参照文末错误处理
还可以使用注解方式来简化代码:
package fun.psgame.demo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.model.AfterExtractor;
import us.codecraft.webmagic.model.OOSpider;
import us.codecraft.webmagic.model.annotation.ExtractBy;
import us.codecraft.webmagic.model.annotation.TargetUrl;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import java.util.List;
//目标url,这里.和*进行了默认替换处理,.替换成了.,*替换成了.*
@TargetUrl("https://www.cnblogs.com/lixin-link/default.html\?page=\d")
//HelpUrl是为了发现目标url而需要访问的网页
//@HelpUrl("https://www.cnblogs.com/lixin-link")
public class MyBlogAnnoProcessor implements AfterExtractor {
//这个注解会根据规则自动设置属性
@ExtractBy("//div[@class="forFlow"]/div/div[@class="postTitle"]/a/text()")
List<String> titles;
//这里可以实现AfterExtractor,来做一些注解无法完成的工作
@Override
public void afterProcess(Page page) {
// titles.forEach(System.out::println);
}
public static void main(String[] args) {
//注解方式入口
OOSpider.create(Site.me().setSleepTime(1500)
, MyBlogAnnoProcessor.class)//第二个参数是dto类型,这里使用了同一个类,一般来说分开更好
.addUrl("https://www.cnblogs.com/lixin-link/default.html?page=1")
.addPipeline(new ConsolePipeline())
.run();
}
}
错误处理
WebMagic默认的HttpClient只会用TLSv1去请求,对于某些只支持TLS1.2的站点,会出现如下错误:
javax.net.ssl.SSLException: Received fatal alert: protocol_version
at sun.security.ssl.Alerts.getSSLException(Alerts.java:208)
at sun.security.ssl.Alerts.getSSLException(Alerts.java:154)
at sun.security.ssl.SSLSocketImpl.recvAlert(SSLSocketImpl.java:2023)
...
作者已经给出解决方法,参照Issues
说下怎么做,下载源码(最新版已修改,但是maven中的还有这个问题),编译webmagic-core,然后替换本地maven仓库中的webmagic-core-0.7.3.jar,如果嫌麻烦可以使用我编译过的jar包:蓝奏云,密码:8voj
参照: