手写体识别与Tensorflow
如同所有语言的hello world一样,手写体识别就相当于深度学习里的hello world。
TensorFlow是当前最流行的机器学习框架,有了它,开发人工智能程序就像Java编程一样简单。
MNIST
MNIST 数据集已经是一个被”嚼烂”了的数据集, 很多教程都会对它”下手”, 几乎成为一个 “典范”. 不过有些人可能对它还不是很了解, 下面来介绍一下.
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
tensorflow提供一个input_data.py文件,专门用于下载mnist数据,我们直接调用就可以了,代码如下:
import tensorflow.examples.tutorials.mnist.input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
执行完成后,会在当前目录下新建一个文件夹MNIST_data
input_data文件会调用一个maybe_download函数,确保数据下载成功。这个函数还会判断数据是否已经下载,如果已经下载好了,就不再重复下载。
思路
把图片当成一枚枚像素来看,下图为手写体数字1的图片,它在计算机中的存储其实是一个二维矩阵,每个元素都是0~1之间的数字,0代表白色,1代表黑色,小数代表某种程度的灰色。

现在,对于MNIST数据集中的图片来说,我们只要把它当成长度为784的向量就可以了(忽略它的二维结构,28×28=784)。我们的任务就是让这个向量经过一个函数后输出一个类别。就是下边这个函数,称为Softmax分类器。

这个式子里的图片向量的长度只有3,用x表示。乘上一个系数矩阵W,再加上一个列向量b,然后输入softmax函数,输出就是分类结果y。W是一个权重矩阵,W的每一行与整个图片像素相乘的结果是一个分数score,分数越高表示图片越接近该行代表的类别。因此,W x + b 的结果其实是一个列向量,每一行代表图片属于该类的评分。通常分类的结果并非评分,而是概率,表示有多大的概率属于此类别。因此,Softmax函数的作用就是把评分转换成概率,并使总的概率为1。
CNN
卷积神经网络(Convolutional Neural Networks / CNNs / ConvNets)与普通神经网络非常相似,它们都由具有可学习的权重和偏置常量(biases)的神经元组成。每个神经元都接收一些输入,并做一些点积计算,输出是每个分类的分数,普通神经网络里的一些计算技巧到这里依旧适用。
卷积神经网络利用输入是图片的特点,把神经元设计成三个维度 : width, height, depth(注意这个depth不是神经网络的深度,而是用来描述神经元的) 。比如输入的图片大小是 32 × 32 × 3 (rgb),那么输入神经元就也具有 32×32×3 的维度。下面是图解:

一个卷积神经网络由很多层组成,它们的输入是三维的,输出也是三维的,有的层有参数,有的层不需要参数。
卷积神经网络通常包含以下几种层:
数据输入层:
该层要做的处理主要是对原始图像数据进行预处理,其中包括:
• 去均值:把输入数据各个维度都中心化为0,如下图所示,其目的就是把样本的中心拉回到坐标系原点上。
• 归一化:幅度归一化到同样的范围,如下所示,即减少各维度数据取值范围的差异而带来的干扰,比如,我们有两个维度的特征A和B,A范围是0到10,而B范围是0到10000,如果直接使用这两个特征是有问题的,好的做法就是归一化,即A和B的数据都变为0到1的范围。
• PCA/白化:用PCA降维;白化是对数据各个特征轴上的幅度归一化
卷积层
卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
下面的动态图形象地展示了卷积层的计算过程:
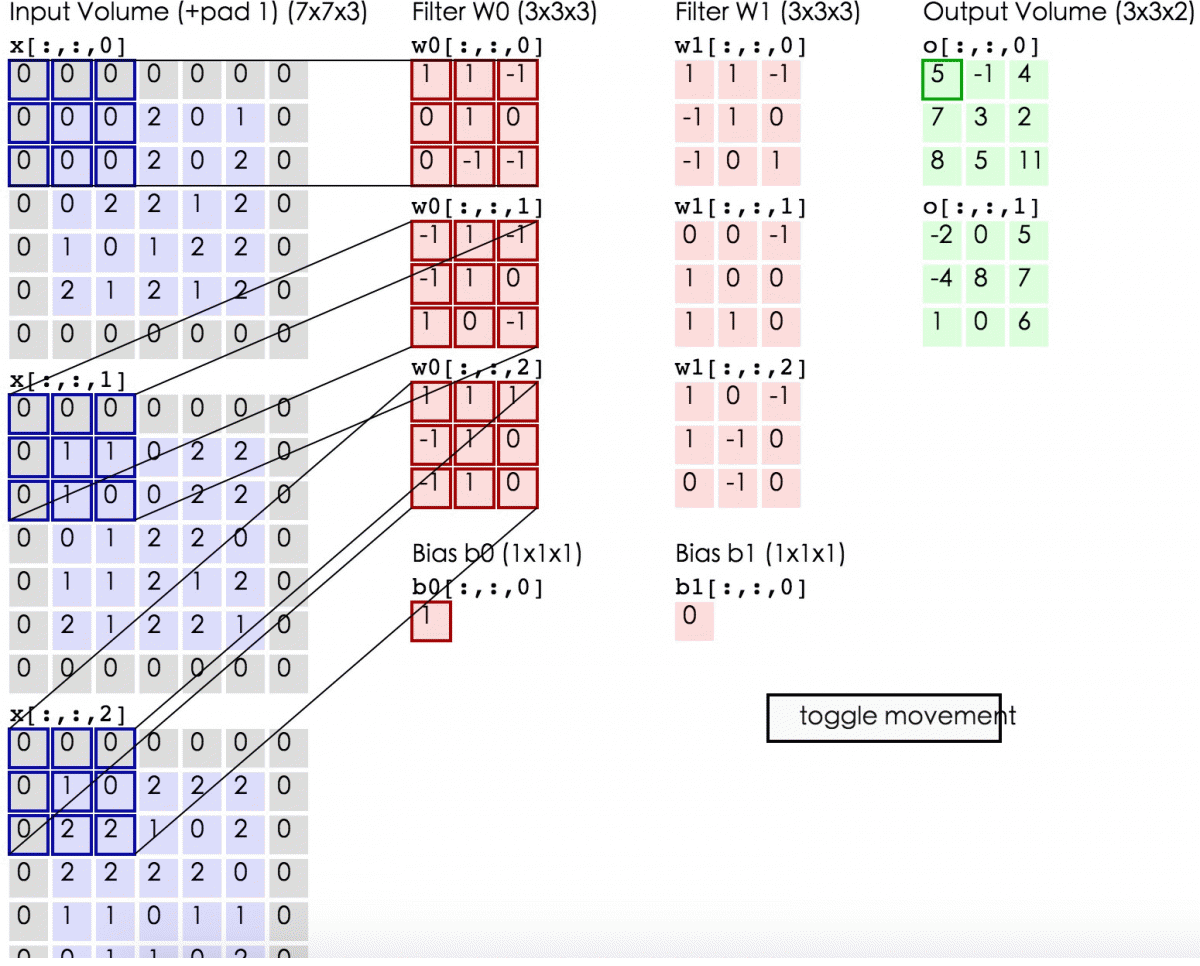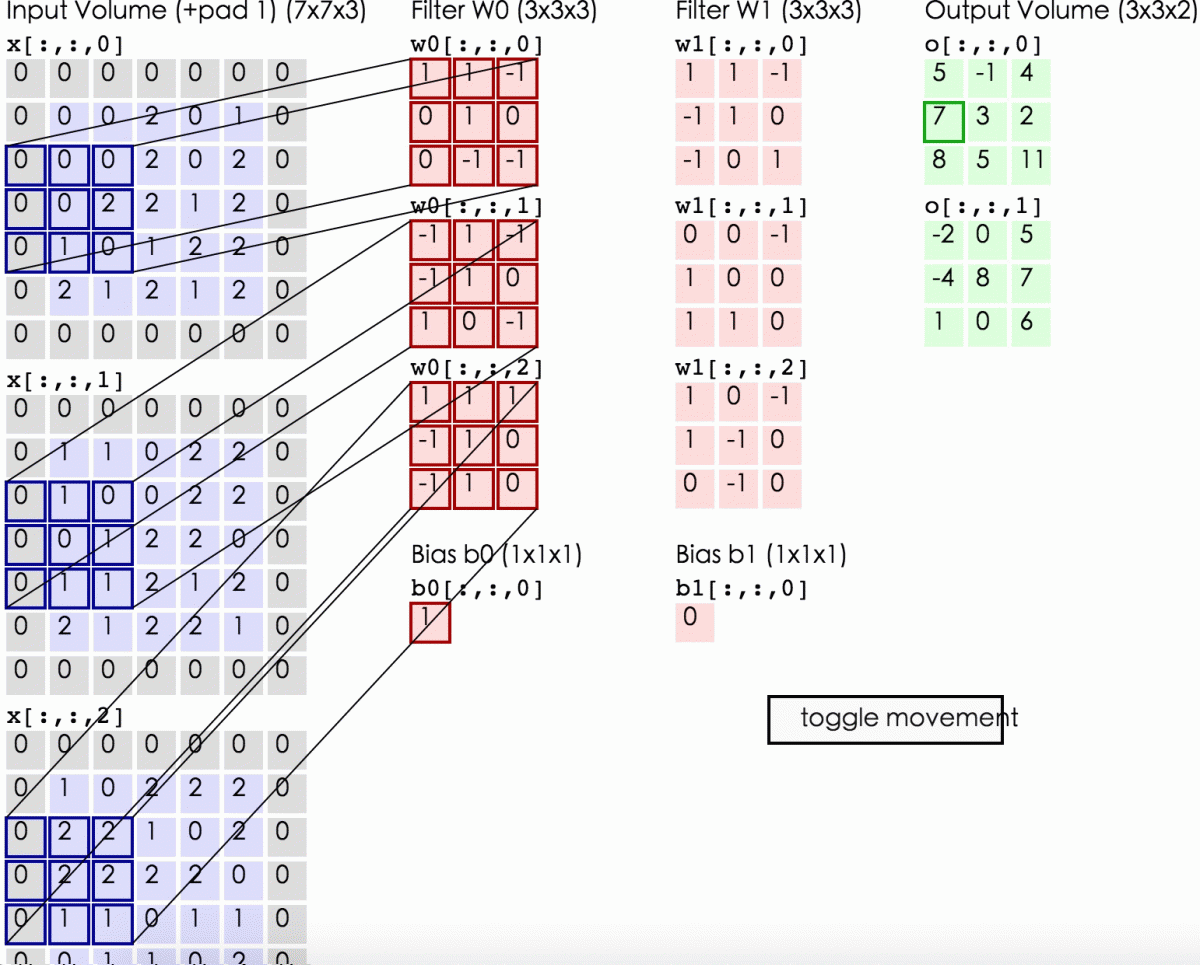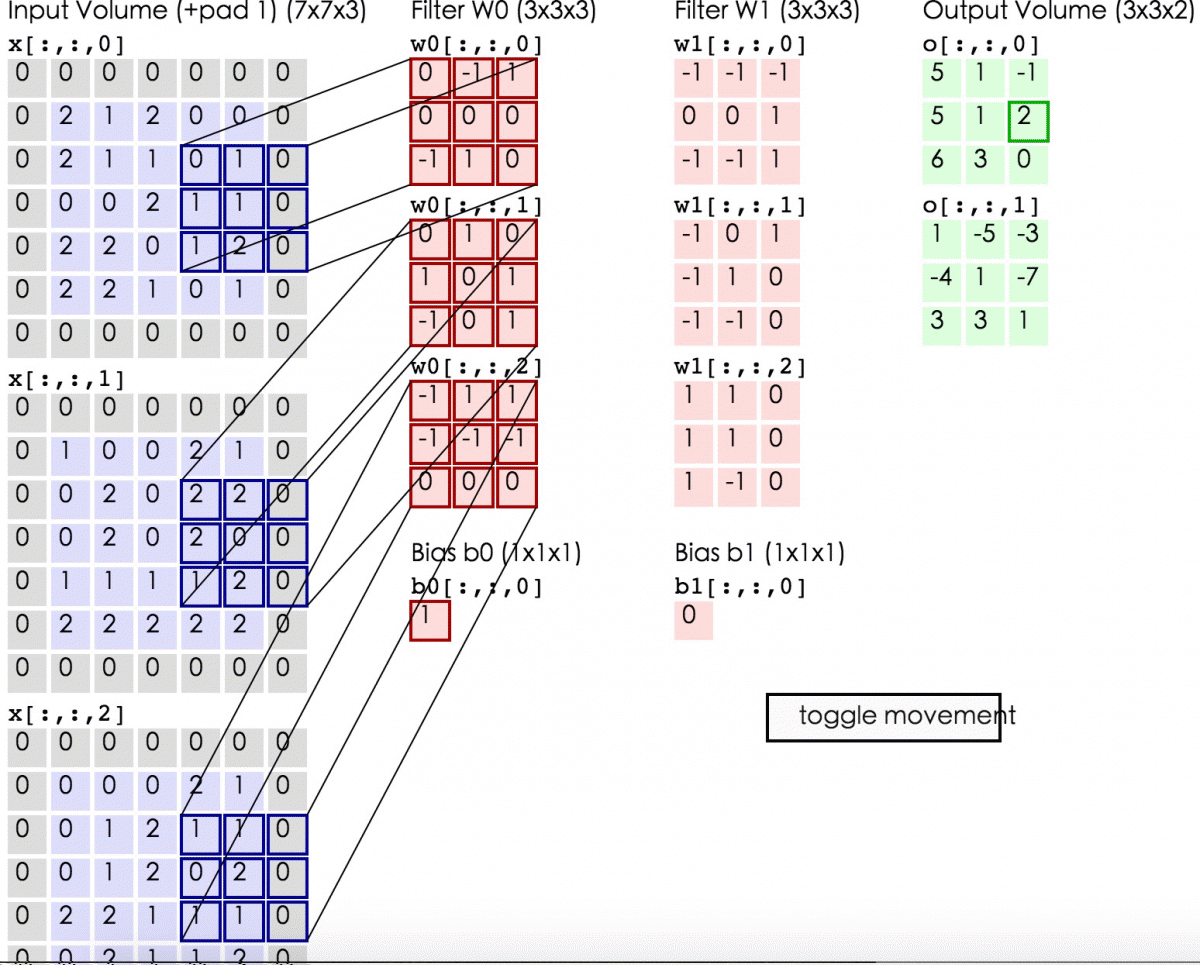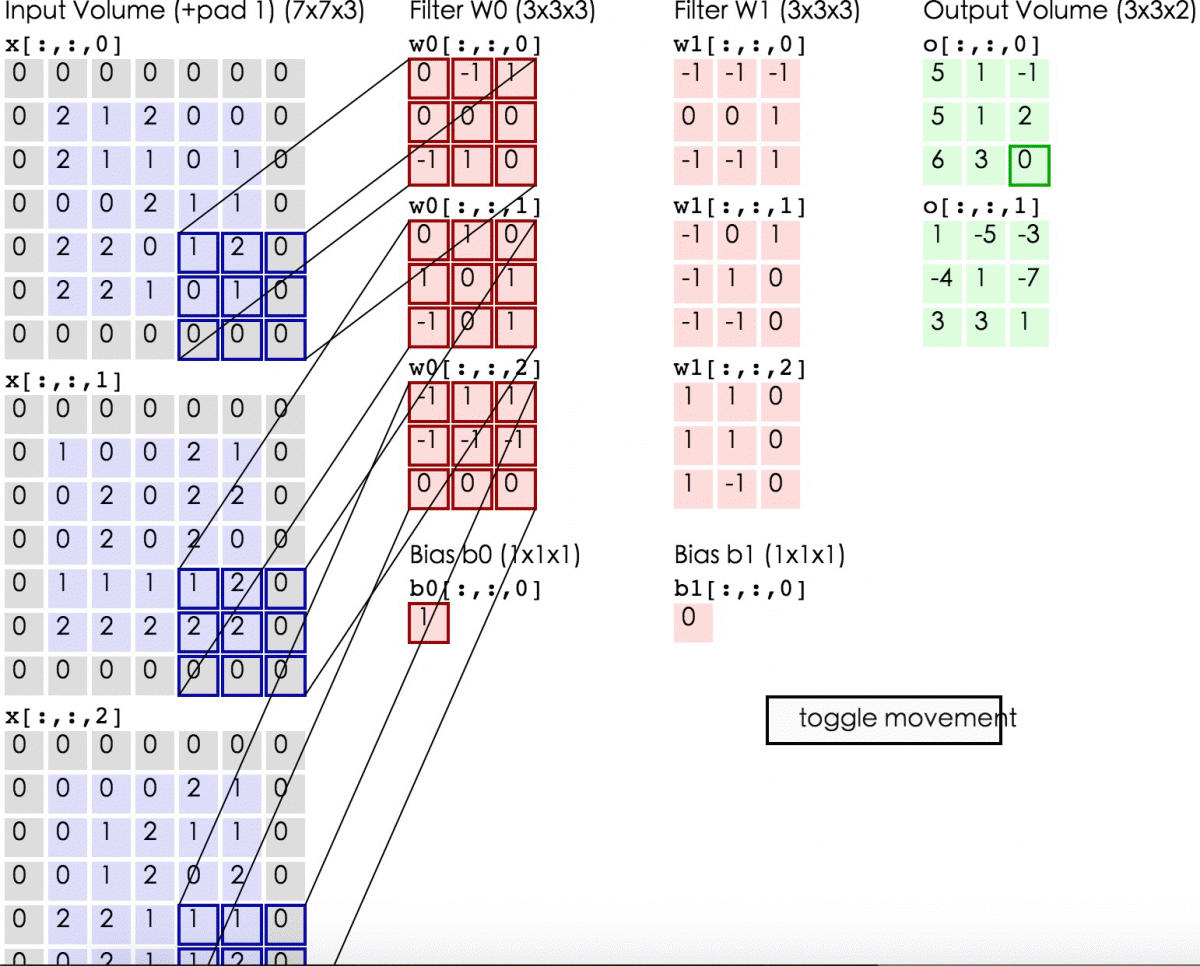
线性整流层(Rectified Linear Units layer, ReLU layer),这一层神经的活性化函数(Activation function)使用线性整流(Rectified Linear Units, ReLU)f(x)=max(0,x)
把卷积层输出结果做非线性映射。 
池化层(Pooling layer),通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
池化层的具体作用。
1.特征不变性,也就是我们在图像处理中经常提到的特征的尺度不变性,池化操作就是图像的resize,平时一张狗的图像被缩小了一倍我们还能认出这是一张狗的照片,这说明这张图像中仍保留着狗最重要的特征,我们一看就能判断图像中画的是一只狗,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
2.特征降维,我们知道一幅图像含有的信息是很大的,特征也很多,但是有些信息对于我们做图像任务时没有太多用途或者有重复,我们可以把这类冗余信息去除,把最重要的特征抽取出来,这也是池化操作的一大作用。
3.在一定程度上防止过拟合,更方便优化。
池化层用的方法有Max pooling 和 average pooling,而实际用的较多的是Max pooling。
全连接层( Fully-Connected layer), 把所有局部特征结合变成全局特征,用来计算最后每一类的得分。CNN的常用框架
Caffe
• 源于Berkeley的主流CV工具包,支持C++,python,matlab
• Model Zoo中有大量预训练好的模型供使用
Torch
• Facebook用的卷积神经网络工具包
• 通过时域卷积的本地接口,使用非常直观
• 定义新网络层简单
TensorFlow
• Google的深度学习框架
• TensorBoard可视化很方便
• 数据和模型并行化好,速度快

实现代码
代码如下:
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
# -*- coding:utf-8 -*-
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#number from 0 to 9:
mnist=input_data.read_data_sets('MNIST_data/',one_hot=True)
def add_layer(inputs,in_size,out_size,activation_function=None):
Weights=tf.Variable(tf.random_normal([in_size,out_size]))
bises=tf.Variable(tf.zeros([1,out_size])+0.1)
Wx_plus_b=tf.matmul(inputs,Weights)+bises
if activation_function is None:
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
return outputs
#计算准确度
def compute_accuracy(x,y):
global prediction
y_pre=sess.run(prediction,feed_dict={xs:x})
correct_prediction=tf.equal(tf.argmax(y_pre,1),tf.argmax(y,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
result=sess.run(accuracy,feed_dict={xs:x,ys:y})
return result
#def placeholder for inputs
xs=tf.placeholder(tf.float32,[None,784]) #28*28
ys=tf.placeholder(tf.float32,[None,10]) #10个输出
#add output layer
prediction=add_layer(xs,784,10,tf.nn.softmax) #softmax常用于分类
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))
train=tf.train.GradientDescentOptimizer(0.3).minimize(cross_entropy)
sess=tf.Session()
sess.run(tf.initialize_all_variables())
for i in range(2000):
batch_xs,batch_ys=mnist.train.next_batch(100)
sess.run(train,feed_dict={xs:batch_xs,ys:batch_ys})
if i%100==0:
print(compute_accuracy(mnist.test.images,mnist.test.labels))
执行看输出,准确度为:
Extracting MNIST_data/train-images-idx3-ubyte.gz Extracting MNIST_data/train-labels-idx1-ubyte.gz Extracting MNIST_data/t10k-images-idx3-ubyte.gz Extracting MNIST_data/t10k-labels-idx1-ubyte.gz 0.1007 0.6668 0.7603 0.7946 0.8198 0.8324 0.8416 0.8473 0.8544 0.8565 0.8634 0.8661 0.8654 0.8692 0.8725 0.8727 0.8748 0.8753 0.8771 0.8781
准确率为87%。
总结
上面的例子使用的是TensorFlow提供的数据集,我们可以自己手写一个数字,然后通过opencv对数字进行剪裁,然后输入模型看识别的结果。
深度学习和nlp的可以加微信群交流,目前,我们正在参加nlp方面的比赛。