一、介绍
注:本文所指版本Kafka 1.1
Kafka是由Apache开发的一款发布订阅消息系统,是分布式的,分区的重复的日志服务。
1、为什么要用kafka?
①、解耦
允许两方修改处理过程,只要遵循共同的接口约束。
②、灵活性和峰值处理能力
面对突然增加的吞吐量有很好应对,发送信息量50M,消费信息量100M。
③、消息冗余
消息队列把数据持久化直到已经完全被处理。与以往消息“插入 - 获取 - 删除”不同,在删除消息时,必须确定消息已被处理完毕。
④、扩展性
扩展性较好,只要增加入队和消费处理过程即可。
⑤、顺序保证
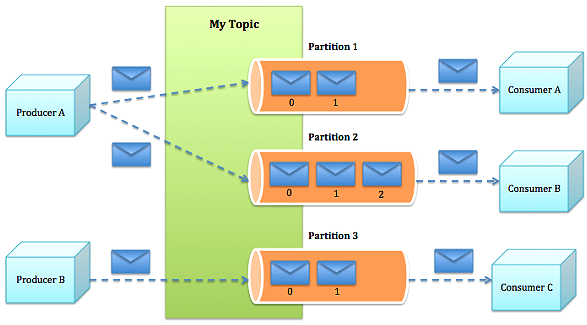
针对消息顺序的重要性,kafka保证一个partition内的消息有序性。
2、应用场景
①、日志收集
ELK日志采集框架中,利用kafka同Logstash来收集服务端日志。
②、消息系统
解耦生产者与消费者,缓存消息,实现异步处理。
③、实现消息 “发布-订阅模式“
对于不同消费者消费同一消息,利用Kafka实现:同一个topic中的消息只能被同一个Consumer Group中的一个消费者消费,但可以被多个Consumer Group消费这一消息。
④、用户活动跟踪
Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到Hadoop、数据仓库中做离线分析和挖掘。
⑤、运营指标
Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
二、Kafka分析
大概介绍些知识点,作为一个后端开发,了解如何用及基本原理就可以了。
kafka官网给出的交互流程
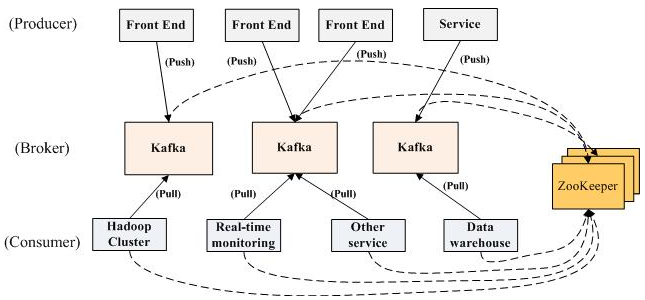
消息处理流程
producer.send(ProducerRecord<K,V> record); 生产者在发送消息时,没有找到topic,会自动创建???
Broker Configs
auto.create.topics.enable = true (默认为true,若没找到topic则自动创建)
三、具体应用
注意我这里有些值写的是伪代码,还需封装到一个公共类中调取。如kafka地址等。
另外,下列代码全手打,有错误的地方请指正。
1、pom依赖
producer和consumer均依赖 kafka-clients.
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>1.1.0</version> </dependency>
2、Producer
2.1、producer configs
Properties properties = new Properties(); properties.put("bootstrap.servers", "ipAndPort"); //指定kafka服务地址,集群的情况用逗号分隔,如:host1:port1,host2:port2 ... properties.put("acks", "all");//表示完成Requests前需要承认的数量。 0:无需承认直接发送到socket 1:需要leader承认 all/-1:需要全部承认后发送 properties.put("retries", 0);//发生错误时,重传次数。当开启重传时,需要将`max.in.flight.requests.per.connection`设置为1,否则可能导致失序 properties.put("batch.size", 16384); properties.put("linger.ms", 1); //1毫秒,简单讲,就是延时1ms,把期间收集到的所有Requests聚合到一起发送,以此提高吞吐量 properties.put("buffer.memory", 33554432);//默认值就是 33554443,缓存数据的内存大小;若生产速度大于Producer向Broker发送速度,会阻塞超时抛出异常 properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //指定扔到kafka的键值对中键的类型,实例包下还有Long、Double、Short等等 properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //指定键值对的值类型,具体同上
2.2、KafkaProducerUtil.java
这里定义一个Producer的工具类,封装了producer的初始化及发送消息到指定topic。
public class KafkaProducerUtil { private static Logger logger = Logger.getLogger(KafkaProducerUtil.class); private static Producer<String, String> producer;
/** 做一个简单的单例模式,实例化producer对象 **/ private static Producer<String, String> getProducer() { if (producer == null) { synchronized (KafkaProducerUtil.class) { if (producer == null) { Properties properties = new Properties(); //写入配置信息供初始化Producer producer = new KafkaProducer<String, String>(properties); } } } return producer; }
/**
* send record to topic
*/
public static void sendToKafka(String topic, String message, Long timeOut) throws InterruptedException, ExecutionException, TimeoutException { producer = getProducer(); producer.send(new ProducerRecord<String, String>(topic, message)).get(timeOut, TimeUnit.SECONDS); logger.info("sendToKafka:" + message); } }
2.3、KafkaProducerService.java
提供工业务层调用的接口,这里做了http请求方式的兼容处理。
public interface KafkaProducerService {
/**
* @param httpUrl 通过http发送请求的方式调用地址
* @param code 生成topic
* @param request 请求数据
* @param version 加签
* @param timeOut 超时时间
*/
void send(String httpUrl, String code, Object request, String version, Long timeout);
}
@Service public class KafkaProducerServiceImpl implements KafkaProducerService { private static Logger logger = LoggerFactory.getLogger(KafkaProducerServiceImpl.class); public void send(String httpUrl, String code, Object request, String version, Long timeout) { String isOpenFlag = "可以作为系统参数,不同环境有不同的启用程度,开启走kafka,关闭走http方式"; if ("open" == isOpenFlag) { sendByKafka(httpUrl, code, request, version, timeout); } else { sendByHttp(...); } } private void sendByKafka(String httpUrl, String code, Object request, String version, Long timeout) { // 按一定规则拼接topic String topic = "XXX可以依环境决定,也可以依系统决定" + "_" + code; // 取加签私钥 String privateKey = "自行封装"; logger.info("topic:" + topic + "请求报文:" + JSON.toJSONOString(request, SerializerFeature,WriteMapNullValue)); // 报文加签 Object producerObject = SecurityUtil.digest(request, privateKey, version); String producerRecord = JSON.toJSONString(producerObject, SerializerFeature.WriteNullStringAsEmpty, SerializerFeature.WriteMapNullValue); try { KafkaProducerUtil.sendToKafka(topic, producerRecord, timeout); } catch (RuntimeException e) { //出现异常,改用http调用 logger.error(e.getMessage()); sendByHttp(httpUrl, request, version); } } private void sendByHttp(String httpUrl, Strign request, String version) { //TODO 自行封装,通常情况加验签,把请求报文打印日志,转成json格式发送至api接口,此处不过多赘述。 } }
以上基本满足Producer方使用。
3、Consumer
3.1、consumer configs
Properties props = new Properties(); props.put("bootstrap.servers", "IpAndPort"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000");//自动提交时间间隔,前提是 enable.auto.commit设置为true props.put("session.timeout.ms", "30000"); props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");//指定接受到数据的键值对类型 props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); props.put("group.id", "unique group id");//指定consumer的唯一group
3.2、KafkaConsumerInit.java
consumer方初始化类,封装参数配置、线程定义,业务接口调用等。
public class KafkaConsumerInit extends Thread { private static final Logger logger = LoggerFactory.getLogger(KafkaConsumerInit.class); private final AtomicBoolean closed = new AtomicBoolean(false); KafkaConsumer consumer; //此处格式<topic对应code,对应业务bean名> private Map<String, String> topicsAndBeans; public KafkaConsumerInit(Map<String, String> topicsAndBeans) { super(); // 做转换,根据部署环境,topic加环境的前缀 Set<String> codes= topicsAndBeans.keySet(); Map<String, String> realTopicsAndBeans = new HashMap<String, String>(); for (String code : codes) { String topic = "XXX可以依环境决定,也可以依系统决定" + "_" + code; realTopicsAndBeans.put(topic, topicsAndBeans.get(code)); } this.topicsAndBeans = realTopicsAndBeans; } @Override public void run() { String isOpenFlag = "XXX"; if (!"open".equals(isOpenFlag)) { logger.info("===============配置文件设置 KafkaConsumer 不启动==============="); return; } logger.info("===============启动KafkaConsumer==============="); try { Properties props = new Properties(); //TODO 添加consumer configs consumer = new KafkaConsumer<>(props); //给consumer注册topics 类型Collection<String> consumer.subscribe(topicsAndBeans.keySet()); logger.info("初始化consumer参数"); while (!closed.get()) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { try { logger.info("offset = " + record.offset() + ", value = " + record.value()); logger.info(record.value());
//定义一个统一接口,不同业务实现同一接口。 CommunicationConsumerService communicationHandleService = (CommunicationConsumerService) ApplicationContext.getContext() .getBean(topicsAndBeans.get(record.topic())); communicationHandleService.doHandle(record.value()); } catch (Exception e) { logger.error("数据处理异常:" + record.value()); logger.error(e.getMessage(), e); } } sleep(1000); } } catch (WakeupException e) { logger.error(e.getMessage(), e); if (!closed.get()) { throw e; } } catch (InterruptedException e) { logger.error(e.getMessage(), e); } finally { consumer.close(); } } }
3.3、KafkaConsumerListener.java
服务启动后初始化kafka,这里是利用基于Spring的ApplicationListener接口实现的,若果这方面知识还不清楚,先请点这里。
@Component public class KafkaConsumerListener implements ApplicationListener<ApplicationEvent> { private static final Logger logger = LogManager.getLogger(KafkaConsumerListener.class); @Override public void onApplicationEvent(ApplicationEvent event) { logger.info("==============添加订阅的topic和对应的处理方法==============="); Map<String, String> topicAndBeans = new HashMap<String, String>(); topicAndBeans.put("codeForTopic1", "beanImpl1"); topicAndBeans.put("codeForTopic2", "beanImpl2"); topicAndBeans.put("codeForTopic3", "beanImpl3"); //实例化consumer new KafkaConsumerInit(topicAndBeans).start(); } }
2.3.4、ComsumerService.java
具体业务层实现及封装调用
public interface ConsumerService { /** * @param message */ void doHandle(String message); }
@Serivce public class BeanImpl1 implements ConsumerService { public void doHandle(String message) { //TODO 集体业务实现 } }
以上基本满足consumer方使用。