Tabert模型
论文题目: TABERT: Pretraining for Joint Understanding of Textual and Tabular Data
摘要
近年来,基于文本的自然语言理解任务的预训练语言模型蓬勃发展。这种模型通常是在自由形式的自然语言文本上训练的,因此可能不适合像结构化数据上的语义解析这样的任务,这些任务需要对自由形式的自然语言问题和结构化表格数据(例如,数据库表)进行推理。论文提出的TaBert是一种联合学习自然语言问句与结构化表格的预训练模型,该模型实在bert的基础上进行建立的,能够将表格结构线性化以适配基于Transformer的BERT模型。
引言
非结构化数据: 指没有按照预定义的方式组织或缺少特定数据模型的数据,比如我们常见的文章、对话等。
*结构化数据: * 结构化数据则是指数据点之间具有清晰的、可定义的关系,并包含一个预定义的模型的数据.
非结构化数据通常是不能用结构化数据的常规方法以传统方式进行分析或处理的,所以这也成为 AI 领域一个常见的难题,要理解非结构化数据通常需要输入整段文字,以识别其潜在的特征。
结构化的数据,一般会使用树结构或表格对其进行存储。当我们使用神经网络去处理结构化的数据时,也需要对其进行编码,比如数值编码、one-hot编码。当使用这样的编码方式对数据进行编码时我们就要假设各个层次之间都分别有相等和任意的距离 / 差别,而体现距离本质上就是在寻找这些结构化数据的语义。
-
对于结构化数据存在的问题
异构数据: 处理结构化数据的其中一大挑战在于,结构化数据可能是异构的,同时组合了不同类型的数据结构,例如文本数据、定类数据、数字甚至图像数据。其次,数据表有可能非常稀疏。想象一个 100 列的表格,每列都有 10 到 1000 个可能值(例如制造商的类型,大小,价格等),行则有几百万行。由于只有一小部分列值的组合有意义,可以想象,这个表格可能的组合空间有多么「空」。
语义理解: 处理结构化数据并不仅仅依赖于数据本身的特征 (稀疏,异构,丰富的语义和领域知识),数据表集合 (列名,字段类型,域和各种完整性约束等)可以解码各数据块之间的语义和可能存在的交互的重要信息。也就是说,存储在数据库表中的信息具有强大的底层结构,而现有的语言模型(例如 BERT)仅受过训练以编码自由格式的文本。 -
结构化数据表证
为了能够在结构化数据中更好地应用神经网络,我们需要把结构化数据嵌入到一个新的空间中去,以实现结构化数据的表征。在这方面,非结构化数据的处理中已经做了很好地表率,也就是文本的预训练。
文本和表格数据的联合表示学习
TaBert在BERT之上进行构建,能够将表格结构线性化以适配基于Transformer的BERT模型

上图给出了TaBert的原理概览,给定自然语言描述u和表格T,模型首先从表中选取与描述最相关的几行作为数据库内容的快照,之后对其中的每一行进行线性化,并将线性化的表格和自然语言描述输入到Transformer中,输出编码后的单词向量和列值向量。随后编码后的每一所有行被送入垂直自注意力编码层(Vertical Self-Attention),一个列值(一个单词)通过计算同一列的值(同一单词)的垂直排列向量的自注意力得到。最终经过池化层得到单词和列的表示。
-
数据库内容的快照
由于表格可能包含大量的行,但是只有少数的几行与输入描述相关,对所有的行进行编码是没必要的同时也是难以计算的。因此TaBert使用只包含几行预描述最相关的“内容快照”,它提供了一个有效的方法,能够从列值计算出列的表示。
TaBert使用一个简单的策略来得到一个K行的内容快照。如果K>1,对表中的每一行与输入描述计算n-gram覆盖率,选取前K行作为快照。如果K=1,为了尽可能多的获得表中的信息,TaBert构建了一个合成行,每一列都是从对应列选取n-gram覆盖率最高的一个值,作为合成行这一列的值。这样做的动机是,与描述相关的值可能存在于多行中。 -
行的线性化
TaBert对内容快照中的每一行进行线性化,作为Transformer的输入。每一个值表示成三部分:列名、类型和单元值,中间使用“|”分割。如上图的B,R2行的2005就可以表示为:

对于一行来说,其线性化即为将所有的值进行连接,中间使用”[SEP]“进行分割。之后在前面链接自然语言描述,作为Transformer的输入序列。
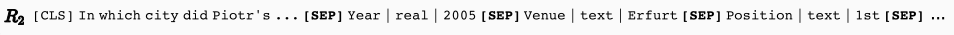
-
垂直自注意力机制(Vertical Self-Attention)
TaBert中Transformer输出了每一行的编码结果,但是每一行是单独计算的,因此是相互独立的。为了使信息在不同行的表示中流动,TaBert给出了垂直自注意力,可以在不同行的相互对齐的向量中进行计算。
如图2(C)所示,TaBert有V个垂直堆叠的自注意力层。为了生成垂直注意力的对齐输入,首先对每个单元值计算固定长度的初始向量(对Transformer的输出向量进行平均池化)。接下来将自然语言描述的向量序列与初始化后的单元值向量进行连接。
垂直注意力与Transformer拥有相同的参数,但是是对垂直对齐的元素(自然语言描述中的同一个单词,同一列中的单元值)进行操作。这种垂直注意力机制能够聚合不同行中的信息,允许模型捕获单元值的跨行依赖关系。 -
自然语言描述和列的表示
每一列的表示:在最后一个垂直层中,将对齐的单元值向量进行平均池化,得到该列的表示。描述中每一个单词的表示也采用类似的方式进行计算。
-
无监督学习目标
TaBert使用不同的目标来学习上下文和结构化表的表示。对于自然语言上下文,使用遮蔽语言模型(MLM)目标,在句子中遮蔽15%的token。对于列的表示,TaBert设计了两个学习目标:- 遮蔽列预测(Masked Column Prediction,MCP)目标使模型能够恢复被遮蔽的列名和数据类型。具体来说就是从输入表中随机选取20%的列,在每一行的线性化过程中遮蔽掉它们的名称和数据类型。给定一列的表示,训练模型使用多标签分类目标来预测其名称和类型。直观来说,MCP使模型能够从上下文中恢复列的信息。
- 单元值恢复(Cell Value Recovery,CVR)目标能够确保单元值信息能够在增加垂直注意力层之后能够得以保留。具体而言,在MCP目标中,列(c_{i})被遮蔽之后(单元值未被遮蔽),CVR通过这一列某一单元值的向量表示(s<i, j>)来恢复这一单元值的原始值。由于一个单元值可能包含多个token,TaBert使用了基于范围(span)的预测目标,即使用位置向量(e_{k})和单元的表示(s<i, j>)作为一个两层网络的输入,来预测一个单元值的token。
表格语义解析
本文章对表格语义解析的内容没有介绍论文中介绍到的模型方法(TranX语义解析器、MAPO语义解析器),引用了在"中文NL2SQL挑战赛"中一位选手介绍的方法。
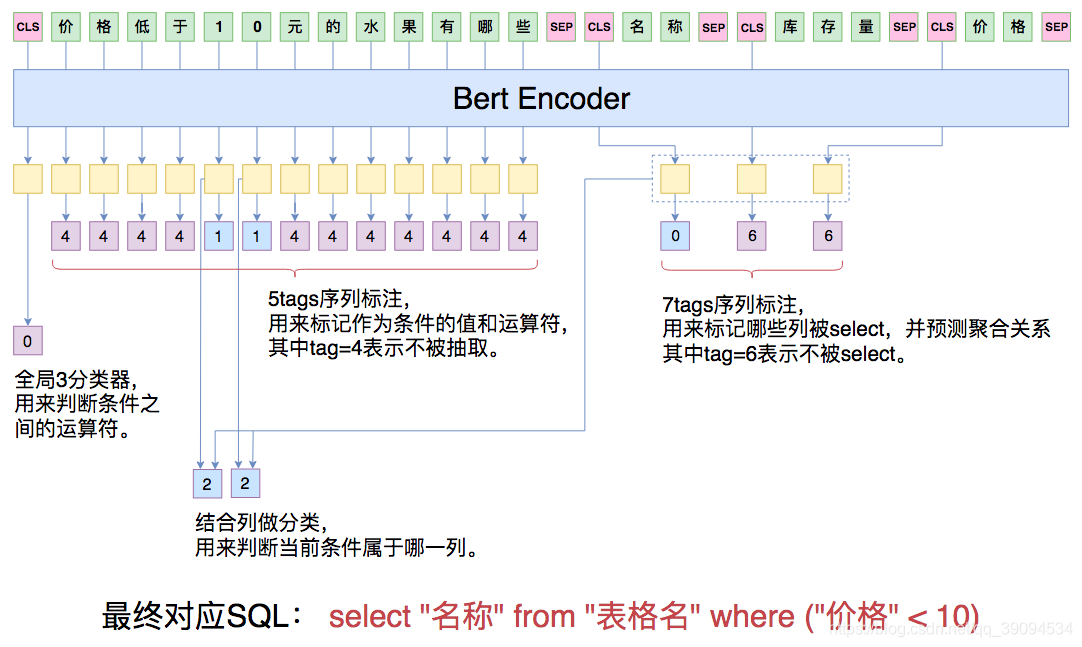
Bridging模型
论文题目: Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing
引言
给定自然语言问句(Q)和关系型数据库模式(S=<Gamma, C>),模型需要生成对应的SQL查询(Y) 。
我们知道,一个数据库中可能包含很多张表,一张表又包含多个字段,所以(Gamma = {{t_1,t_2,...,t_N}}; C={{c_{1|t_1|}, c_{2|t_2|},...c_{N|t_N|}}})。每张表的表名(t_i)和字段名(c_{ij})都是文本字符。表中的字段可能有主键、外键,同时字段有不同的数据类型。
论文提出的模型BRIDGE采用了主流的Seq2Seq架构,把Text2SQL视作翻译问题(原序列:text,目标序列:SQL),包含编码器和解码器。
编码器
编码器的目的是对Q和S分别做向量编码,同时对两者之间的关系充分交互。
论文中,作者将Q和S拼接为一个混合的问题-模式序列(X),作为编码器的输入:
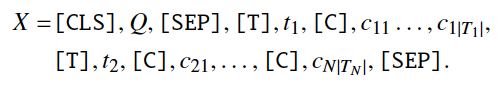
每一个表名、字段名分别用字符[T]和[C]分隔。问题Q和S之间用字符[SEP]分隔。最后,在开始位置插入[CLS]字符。这样的序列既符合BERT的输入格式,从而优雅地编码跨模态信息,又能快速获取任意字段的编码向量(提取[T]/[C]对应特征即可)。
-
获得问题初始编码
(X)首先输入BERT,随后经过一层双向LSTM获得序列的初始编码表示 (h_X)。

(h_X)中的问题片段继续通过一层bi-LSTM获得Q的最终编码(h_Q) 。 -
获得元数据特征
相比于表名,字段名多了主键、外键等属性。为了利用这些特征(meta-data),论文中用了一层前馈网络对表名、字段名进一步编码。
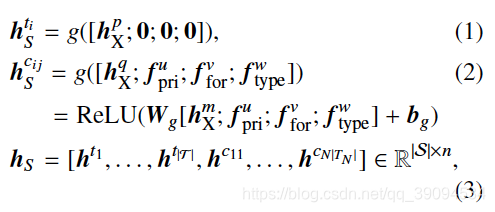
这里的(f_{pri}; f_{for}; f_{type})分别表示各个字段的主键、外键、类型特征,(h^{q}_X)表示字段特征。将4个向量横向顺序拼接,经过函数(g)转化,可以得到每一个字段的最终向量表示。
表名没有额外特征,后三个维度均用零向量替代。各个表名、字段名都进行(g)函数转化,纵向拼接得到模式的最终编码(h_S)。
Bridging
为了解决(Q)和(S)的交互,使用了锚文本,将问题(Q)中包含的单元值与数据库字段链接起来。
具体实现上,作者将问题Q中的每一个token,与数据库表中每一列的所有value值进行字符串模糊匹配,匹配上的value值将被插入到序列X中。
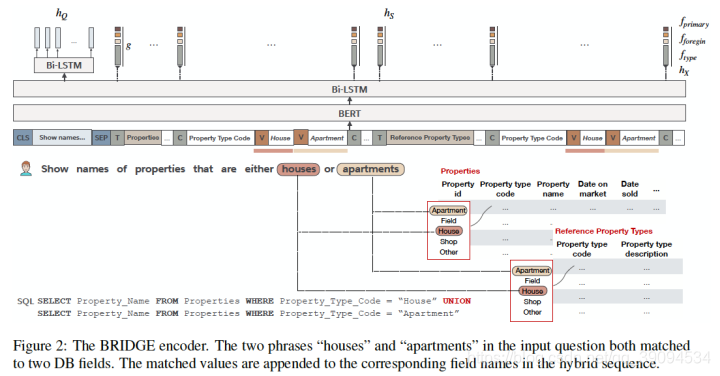
如上图所示,问题Q和表格“Properties”、“Reference Property Types”相关联。其中Q包含的两个单词“houses”和“apartments”与两张表中的同名字段“Property type code”有重合单元值。
所以作者在(X)中把和问题有关的单元值人为拼接在相应字段之后,相当于直接告诉BERT哪些问题片段包含引用。
解码器
解码器的目的是从编码特征中还原出相应SQL。
相比于前人的工作(RAT-SQL、IRNet等),BRIDGE解码器设计非常简洁,仅使用了一层带多头注意力机制[4]的LSTM指针生成网络。
在每一个step中,解码器从如下动作中选择1种:
1、从词汇表V中选择一个token(SQL关键字)
2、从问题Q中复制一个token
3、从模式S中复制一个组件(字段名、表名、单元值)
(解码器部分看的不是很明白,读者可自行阅读原文内容理解,但该论文方法中将NLP和表格进行结合的编码部分值得借鉴)