1.NoSQL是什么?
NoSQL 是 Not Only SQL 的缩写,意即"不仅仅是SQL"的意思,泛指非关系型的数据库。强调Key-Value Stores和文档数据库的优点,而不是单纯的反对RDBMS。
NoSQL产品是传统关系型数据库的功能阉割版本,通过减少用不到或很少用的功能,来大幅度提高产品性能
2.NoSQL是怎么产生的?
随着web2.0技术的发展,其促使了物联网和移动互联网迅猛发展。传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
3.NoSQL的特点:
- 模式自由:NoSQL数据库不像传统的关系型数据库需要定义数据库,数据表等结构才可以存取数据,其在增删数据时不需要做数据的完整性检查。数据表中的每一条记录都可能有不同的属性和格式。
- 逆范式化:为了减少数据冗余,增强数据一致性,在关系型数据库设计时,要遵循范式要求,数据表至少要满足第三范式。这样多个表之间建立各种关联关系就不容易数据库的横向扩展;并且这些连接操作也会降低数据库的查询效率。而NoSQL数据库去除约束,放宽事务保障,更利于数据的分布式存储。
- 多分区存储:传统关系型数据库往往把数据都存储在一个节点上。通过增加内存和磁盘的方式来提高系统的性能,以实现数据的纵向扩展,这种方式不仅昂贵且不可持续。NoSQL数据库会将数据分区,存储在多个节点上,这是一种水平的扩展方式,这种方式不仅能够很好的满足大数据的存储要求,而且还可以提高数据的读写性能。
- 弹性可扩展:NoSQL数据库不仅可以分区存储数据,而且还可以在系统运行过程中动态的增删节点,数据自动平衡移动,不需要人工的干预操作。
- 多副本异步复制:为了保证数据的安全性,NoSQL数据库往往会保存数据的多个副本。在操作的时候往往都是将数据快速的写入一个节点,其余节点通过读取写入节点的读写日志来实现数据的异步复制
- 软事务:事务是关系型数据库的一个特点。事务往往包含一系列的操作,这些操作要么都做,要么都不做。事务要满足ACID特性(ACID:指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability))。而NoSQL数据库不能完全满足事务的ACID特性,但是能保证事务的最终一致性。事务是关系型数据库的核心,这么多年关系型数据库的蓬勃发展都是因为这个核心。但是目前在互联网数据急剧增长的情况,事务也让关系型数据库陷入了瓶颈。
4.NoSQL的基础理论:
1. CAP理论: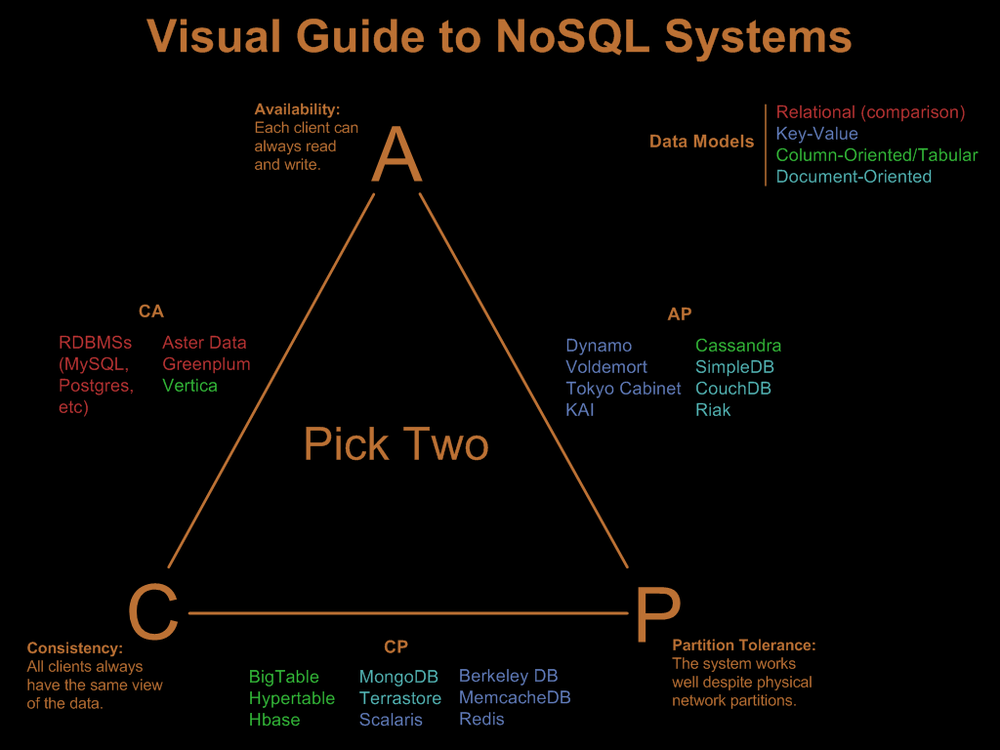
分布式系统中的三个重要特性:一致性(Consistency),可用性(Availability),分区容错性(Tolerance of network Partition)
CAP原理是指这三个要素最多只能同时实现两点,不可能三者兼顾。因此在进行分布式架构设计时,必须做出取舍。而对于分布式数据系统,分区容忍性是基本要求,否则就失去了价值。因此设计分布式数据系统,就是在一致性和可用性之间取一个平衡。对于大多数WEB应用,其实并不需要强一致性,因此牺牲一致性而换取高可用性,是多数分布式数据库产品的方向。
这个理论是由美国著名科学家,同时也是著名互联网企业Inktomi的创始人Eric Brewer在2000年PODC(Symposium on Principles of Distributed Computing)大会上提出的,后来Seth Gilbert 和 Nancy lynch两人也证明了CAP理论的正确性
2. BASE模型:
Basically Availble ——基本可用
Soft-state ——软状态/柔性事务,状态可以有一段时间不同步
Eventual Consistency ——最终一致性

3. 最终一致性理论:
弱一致性包含很多种不同的实现,目前分布式系统中广泛实现的是最终一致性。所谓最终一致性,就是不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化。也可以简单的理解为在一段时间后,节点间的数据会最终达到一致状态。
5.常见NoSQL数据库对比:
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB,Memcache | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak,BigTable | 分布式的文件系统。按列存储,针对某一列或者某几列的查询有非常大的IO优势 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | 存储类似JSON格式的内容,可对某些字段建立索引功能,是最像关系型的数据库 | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱,善于处理大量复杂、互连接、低结构化的数据,数据往往变化迅速,且查询频繁 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |
如果你觉得本博文对你有所帮助,请记得点击右下方的"推荐"哦,么么哒...
转载请注明出处:http://www.cnblogs.com/liushaofeng89/p/4954926.html