1. urllib模块
1.1 urllib简介
urllib 是 Python3 中自带的 HTTP 请求库,无需复杂的安装过程即可正常使用,十分适合爬虫入门
urllib 中包含四个模块,分别是:
request:请求处理模块
parse:URL 处理模块
error:异常处理模块
robotparser:robots.txt 解析模块
1.2 urllib使用
1.2.1 request 模块
request模块是urllib中最重要的一个模块,一般用于发送请求和接收响应
(1)urlopen 方法
urllib.request.urlopen()
urlopen 方法无疑是 request 模块中最常用的方法之一,常见的参数说明如下:
url:必填,字符串,指定目标网站的 URL
data:指定表单数据
该参数默认为 None,此时urllib使用GET方法发送请求
当给参数赋值后,urllib使用POST方法发送请求,并在该参数中携带表单信息(bytes 类型)
timeout:可选参数,用来指定等待时间,若超过指定时间还没获得响应,则抛出一个异常
该方法始终返回一个HTTPResponse对象,HTTPResponse对象常见的属性和方法如下:
read():返回响应体(bytes 类型),通常需要使用decode('utf-8')将其转化为str类型
import urllib.request def load_data(): url = "http://www.baidu.com/" #get的请求 #http请求 #response:http相应的对象 response = urllib.request.urlopen(url) # print(response) #读取内容 bytes类型 data = response.read() # print(data) #将文件获取的内容转换成字符串 str_data = data.decode("utf-8") # print(str_data) #将数据写入文件 with open("baidu.html","w",encoding="utf-8")as f: f.write(str_data) #将字符串类型转换成bytes str_name = "baidu" bytes_name =str_name.encode("utf-8") # print(bytes_name) #python爬取的类型:str bytes #如果爬取回来的是bytes类型:但是你写入的时候需要字符串 decode("utf-8") #如果爬取过来的是str类型:但你要写入的是bytes类型 encode(""utf-8") load_data()
大家可以将我注释的输出内容去掉注释,看看到底输出了什么内容。
(2)urlretrleve方法
这个方法可以方便的将网页上的一个文件保存到本地,以下代码可以非常方便的将百度的首页下载到本地。
from urllib import request request.urlretrieve('http://www.baidu.com/','baidu.html')
(3) Request对象
我们还可以给urllib.request.urlopen()方法传入一个 Request 对象作为参数
为什么还需要使用Request对象呢?因为在上面的参数中我们无法指定请求头部,而它对于爬虫而言又十分重要很多网站可能会首先检查请求头部中的USER-AGENT字段来判断该请求是否由网络爬虫程序发起但是通过修改请求头部中的USER_AGENT字段,我们可以将爬虫程序伪装成浏览器,轻松绕过这一层检查这里提供一个查找常用的USER-AGENT的网站:https://techblog.willshouse.com/2012/01/03/most-common-user-agents/
urllib.request.Request()
参数说明如下:
url:指定目标网站的 URL
data:发送POST请求时提交的表单数据,默认为None
headers:发送请求时附加的请求头部,默认为 {}
origin_req_host:请求方的host名称或者 IP 地址,默认为None
unverifiable:请求方的请求无法验证,默认为False
method:指定请求方法,默认为None
import urllib.request def load_data(): url = "http://www.baidu.com/" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } req = urllib.request.Request(url, headers=headers, method='GET') response = urllib.request.urlopen(req) html = response.read().decode("utf-8") print(html) load_data()
这个结果大家要使用抓包工具来查看。
1.2.2 parse模块
parse模块一般可以用于处理URL
(1)quote 方法
当你在URL中使用中文时,你会发现程序会出现莫名其妙的错误。
import urllib.request url = 'https://www.baidu.com/s?wd=爬虫' response = urllib.request.urlopen(url)
![]()
这个时候就靠quote方法了,它使用转义字符替换特殊字符,从而将上面的URL处理成合法的URL。
import urllib.request import urllib.parse url = 'https://www.baidu.com/s?wd=' + urllib.parse.quote('爬虫') response = urllib.request.urlopen(url) data = response.read() str_data = data.decode("utf-8") print(str_data)
(2)urlencode 方法
urlencode方法就是将dict类型数据转化为符合URL标准的str类型数据。
import urllib.parse params = { 'from':'AUTO', 'to':'AUTO' } data = urllib.parse.urlencode(params) print(data)
(3)urlparse 方法
urlparse方法用于解析URL,返回一个ParseResult对象.
该对象可以认为是一个六元组,对应 URL 的一般结构:
scheme/netloc/path/parameters/query/fragment
实例:
import urllib.parse url = 'http://www.example.com:80/python.html?page=1&kw=urllib' url_after = urllib.parse.urlparse(url) print(url_after)
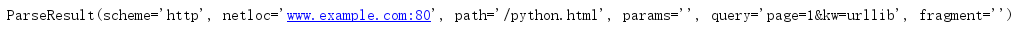
想要获得一个参数的值,只需要 url_after.参数 即可。
(4)parse_qs方法
可以将编码后的url参数进行解码。
from urllib import parse params = {'name':'张三','age':10,'greet':'hello world'} qs = parse.urlencode(params) print(qs) resuit = parse.parse_qs(qs) print(resuit)

(5)urlsplit方法
我感觉这个方法和urlparse方法差不多,都是对url中各个组成部分进行分割。
from urllib import parse url = 'http://www.baidu.com/s?wd=python&username=abc#1' result = parse.urlsplit(url) print('scheme:',result.scheme) print('netloc:',result.netloc) print('path:',result.path) print('query:',result.query)
1.2.3 error模块
error模块一般用于进行异常处理,其中包含两个重要的类:URLError和HTTPError。
注意,HTTPError是URLError的子类,所以捕获异常时一般要先处理HTTPError,常用的格式如下:
import urllib.request import urllib.error import socket try: response = urllib.request.urlopen('http://www.baidu.com/', timeout=0.1) except urllib.error.HTTPError as e: print("Error Code: ", e.code) print("Error Reason: ", e.reason) except urllib.error.URLError as e: if isinstance(e.reason, socket.timeout): print('Time out') else: print('Request Successfully')