套接字基础
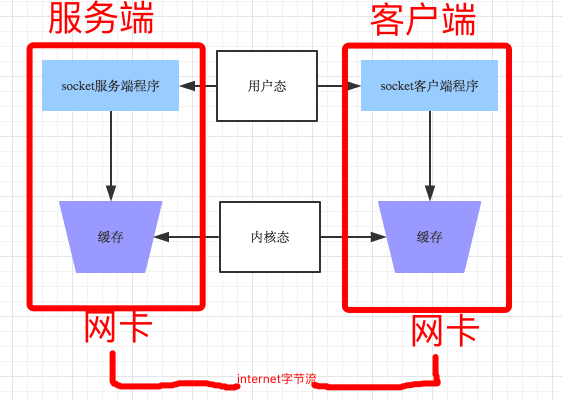
c/s架构 client ---------internet------------server
server端:
力求一直提供服务
要绑定一个唯一的地址,让客户端能够明确的找到
为何学习socket一定要先学习互联网协议:
1.首先:本节课程的目标就是教会你如何基于socket编程,来开发一款自己的C/S架构软件
2.其次:C/S架构的软件(软件属于应用层)是基于网络进行通信的
3.然后:网络的核心即一堆协议,协议即标准,你想开发一款基于网络通信的软件,就必须遵循这些标准。
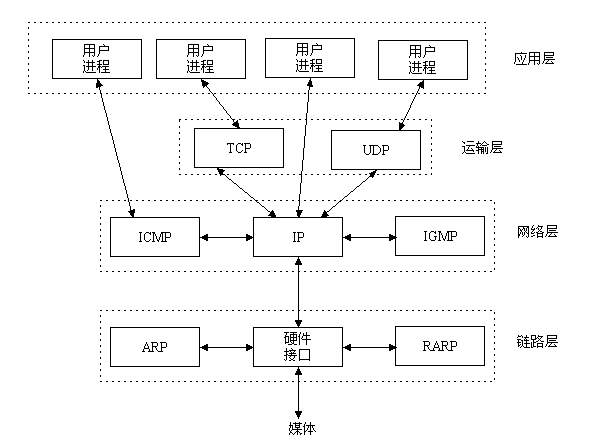
TCP/IP协议族包括传输层、网络层、链路层
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,
它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
所以,我们无需深入理解tcp/udp协议,socket已经为我们封装好了,我们只需要遵循socket的规定去编程,
写出的程序自然就是遵循tcp/udp标准的。
通俗理解:
socket=ip+port,ip是用来标识互联网中的一台主机的位置,而port是用来标识这台机器上的一个应用程序,ip地址是配置到网卡
上的,而port是应用程序开启的,ip与port的绑定就标识了互联网中独一无二的一个应用程序
标准定义:源IP地址和目的IP地址以及源端口号和目的端口号的组合称为套接字。其用于标识客户端请求的服务器和服务。
套接字发展史及分类
套接字起源于 20 世纪 70 年代加利福尼亚大学伯克利分校版本的 Unix,即人们所说的 BSD Unix。 因此,有时人们也把套接字称为“伯克利套接字”或“BSD 套接字”。一开始,套接字被设计用在同 一台主机上多个应用程序之间的通讯。这也被称进程间通讯,或 IPC。套接字有两种(或者称为有两个种族),分别是基于文件型的和基于网络型的。
基于文件类型的套接字家族
套接字家族的名字:AF_UNIX
unix一切皆文件,基于文件的套接字调用的就是底层的文件系统来取数据,两个套接字进程运行在同一机器,可以通过访问同一个文件系统间接完成通信
基于网络类型的套接字家族
套接字家族的名字:AF_INET
(还有AF_INET6被用于ipv6,还有一些其他的地址家族,不过,他们要么是只用于某个平台,要么就是已经被废弃,或者是很少被使用,或者是根本没有实现,所有地址家族中,AF_INET是使用最广泛的一个,python支持很多种地址家族,但是由于我们只关心网络编程,所以大部分时候我么只使用AF_INET)
socket工作流程:
先从服务器端说起。服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。
在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。
客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
基于tcp协议的套接字


1 #基于tcp的服务端 2 import socket 3 phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 4 phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) 5 phone.bind(('127.0.0.1',8080)) 6 phone.listen(5) 7 8 print('start.....') 9 while True:#链接循环 一台客户端中断链接时,不至于服务端也停止运行 10 conn,addr = phone.accept() #等待电话链接 11 print('电话线路是',conn) 12 print('客户端手机号',addr) 13 while True:# 通信循环 14 try: #应对windows系统 15 #print("等待接收") 16 data = conn.recv(1024) 17 if not data : break #应对linux系统 #如果不加,那么正在链接的客户端突然断开,recv便不再阻塞,死循环发生 18 print('客户端发来的消息',data.decode('utf8')) 19 s = input("....") 20 conn.send(s.encode('utf8')) 21 except Exception: 22 break 23 conn.close() 24 phone.close()
1 #基于tcp的客户端 2 import socket 3 phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) 4 phone.connect(('127.0.0.1',8080)) 5 6 while True: 7 msg = input('>> :').strip() 8 if not msg: continue 9 phone.send(msg.encode('utf8')) 10 print('has send=========>') 11 data = phone.recv(1024) 12 print('has recv==========>') 13 print(data) 14 15 16 phone.close()
1.tcp协议:
(1)如果收消息缓冲区里的数据为空,那么recv就会阻塞(阻塞很简单,就是一直在等着收)
(2)只不过tcp协议的客户端send一个空数据就是真的空数据,客户端即使有无穷个send空,也跟没有一个样。
(3)tcp基于链接通信
基于链接,则需要listen(backlog),指定半连接池的大小
基于链接,必须先运行的服务端,然后客户端发起链接请求
对于mac系统:如果一端断开了链接,那另外一端的链接也跟着完蛋recv将不会阻塞,收到的是空(解决方法是:服务端在收消息后加上
if判断,空消息就break掉通信循环)
对于windows/linux系统:如果一端断开了链接,那另外一端的链接也跟着完蛋recv将不会阻塞,收到的是空(解决方法是:服务端通信
循环内加异常处理,捕捉到异常后就break掉通讯循环)
基于udp协议的套接字(QQ聊天)
#基于udp的服务端 from socket import * ip_port = ('127.0.0.1',8080) Bufsize = 1024 t = socket(AF_INET,SOCK_DGRAM) t.bind(ip_port) while True: msg,addr = t.recvfrom(Bufsize) print(msg.decode('utf8'),addr) msg = input('>> :').strip() t.sendto(msg.encode('utf8'),addr)
1 #基于udp的客户端 2 from socket import * 3 ip_port = ('127.0.0.1',8080) 4 Bufsize = 1024 5 t = socket(AF_INET,SOCK_DGRAM) 6 7 8 while True: 9 msg = input('>>:').strip() 10 # if not msg:continue 11 t.sendto(msg.encode('utf8'),ip_port) 12 13 back_msg,addr = t.recvfrom(Bufsize) 14 print(back_msg.decode('utf8'),addr) 15 16 # send(bytes_data):发送数据流,数据流bytes_data若为空,自己这段的缓冲区也为空,操作系统不会控制tcp协议发空包 17 # sendinto(bytes_data,ip_port):发送数据报,bytes_data为空,还有ip_port,所有即便是发送空的bytes_data,数据报其实也 18 # 不是空的,自己这端的缓冲区收到内容,操作系统就会控制udp协议发包。
2.udp协议
(1)如果如果收消息缓冲区里的数据为“空”,recvfrom也会阻塞
(2)只不过udp协议的客户端sendinto一个空数据并不是真的空数据(包含:空数据+地址信息,得到的报仍然不会为空),所以客户端
只要有一个sendinto(不管是否发送空数据,都不是真的空数据),服务端就可以recvfrom到数据。
(3)udp无链接
无链接,因而无需listen(backlog),更加没有什么连接池之说了
无链接,udp的sendinto不用管是否有一个正在运行的服务端,可以己端一个劲的发消息,只不过数据丢失
recvfrom收的数据小于sendinto发送的数据时,在mac和linux系统上数据直接丢失,在windows系统上发送的比接收的大直接报错
只有sendinto发送数据没有recvfrom收数据,数据丢失
服务端套接字函数
s.bind() 绑定(主机,端口号)到套接字
s.listen() 开始TCP监听
s.accept() 被动接受TCP客户的连接,(阻塞式)等待连接的到来
客户端套接字函数
s.connect() 主动初始化TCP服务器连接
s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
公共用途的套接字函数
s.recv() 接收TCP数据
s.send() 发送TCP数据(send在待发送数据量大于己端缓存区剩余空间时,数据丢失,不会发完)
s.sendall() 发送完整的TCP数据(本质就是循环调用send,sendall在待发送数据量大于己端缓存区剩余空间时,数据不丢失,循环调用send直到发完)
s.recvfrom() 接收UDP数据
s.sendto() 发送UDP数据
s.getpeername() 连接到当前套接字的远端的地址
s.getsockname() 当前套接字的地址
s.getsockopt() 返回指定套接字的参数
s.setsockopt() 设置指定套接字的参数
s.close() 关闭套接字
面向锁的套接字方法
s.setblocking() 设置套接字的阻塞与非阻塞模式
s.settimeout() 设置阻塞套接字操作的超时时间
s.gettimeout() 得到阻塞套接字操作的超时时间
面向文件的套接字的函数
s.fileno() 套接字的文件描述符
s.makefile() 创建一个与该套接字相关的文件
粘包现象
两种情况下会发生粘包:
11发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包)
22接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从
缓冲区拿上次遗留的数据,产生粘包)
粘包发生的原因:发消息,都是将数据发送到己端的发送缓冲中,收消息都是从己端的缓冲区中收
TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都
要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较
小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。
即面向流的通信是无消息保护边界的。
UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于
UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消
息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次
需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据
所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
粘包现象:
1 import socket,time 2 3 phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM) 4 #绑定电话卡 5 ip_port=('127.0.0.1',8080) 6 phone.bind(ip_port) 7 phone.listen(5) 8 conn,addr=phone.accept() 9 10 data1=conn.recv(1024) 11 print('第一个包',data1) 12 data2=conn.recv(1024) 13 print('第二个包',data2) 14 15 16 data1=conn.recv(1) #b'h' 17 print('第一个包',data1) 18 time.sleep(5) #利用time来解决粘包问题 19 data2=conn.recv(1024) #b'elloworldSB' 20 print('第二个包',data2)
1 import socket,time 2 3 phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM) 4 5 ip_port=('127.0.0.1',8080) 6 phone.connect(ip_port) 7 8 9 phone.send('helloworld'.encode('utf-8')) 10 time.sleep(3) #利用time来解决粘包问题 11 phone.send('SB'.encode('utf-8'))
利用struct解决粘包问题
(1)为字节流加上自定义固定长度报头,报头中包含字节流长度,然后一次send到对端,对端在接收时,先从缓存中取出定长的报头,然后再取真实数据
struct模块
该模块可以把一个类型,如数字,转成固定长度的bytes
>>> struct.pack('i',1111111111111)
struct.error: 'i' format requires -2147483648 <= number <= 2147483647 #这个是范围
(2)我们可以把报头做成字典,字典里包含将要发送的真实数据的详细信息,然后json序列化,然后用struck将序列化后的数据长度打包成4个字节(4个自己足够用了)
发送时:
先发报头长度
再编码报头内容然后发送
最后发真实内容
接收时:
先手报头长度,用struct取出来
根据取出的长度收取报头内容,然后解码,反序列化
从反序列化的结果中取出待取数据的详细信息,然后去取真实的数据内容
1 from socket import * 2 import subprocess 3 import struct 4 import json 5 t = socket(AF_INET,SOCK_STREAM) 6 t.bind(('192.168.184.128',8080)) 7 t.listen(5) 8 9 while True: #链接循环 10 conn,addr = t.accept() 11 while True: # 通信循环 12 try: 13 cmd = conn.recv(1024) 14 if not cmd:break 15 res = subprocess.Popen(cmd.decode('utf8'), 16 shell = True, 17 stdout = subprocess.PIPE, 18 stderr= subprocess.PIPE) 19 out_res = res.stdout.read() 20 err_res = res.stderr.read() 21 data_size = len(out_res)+len(err_res) 22 head_dic = {'data_size':data_size} 23 head_json = json.dumps(head_dic) 24 head_bytes = head_json.encode('utf8') 25 #发送报头的长度 26 head_len = len(head_bytes) 27 conn.send(struct.pack('i',head_len)) #该模块将一串数字打包以固定长度(4个字节)发送给客户端 28 #发送报头 29 conn.send(head_bytes) 30 #发送数据部分 31 conn.send(out_res) # linux环境中 多个命令用分号隔开的情况 32 conn.send(err_res) 33 except Exception: 34 break 35 conn.close() #通信完成,关闭链接 36 t.close()
1 from socket import * 2 import struct 3 import json 4 t =socket(AF_INET,SOCK_STREAM) 5 t.connect(('192.168.184.128',8080)) 6 7 while True: #通信循环 8 #发消息 9 cmd = input('>>> :') 10 if not cmd: continue 11 t.send(bytes(cmd,encoding='utf8')) 12 #收报头的长度 13 head_struct=t.recv(4) 14 head_len = struct.unpack('i',head_struct) 15 #收报头 16 head_bytes = t.recv(head_len) 17 head_json = head_bytes.decode('utf8') 18 19 head_dic = json.loads(head_json) 20 print(head_dic) 21 data_size = head_dic['data_size'] 22 23 #收数据 24 recv_size = 0 25 recv_data = b'' 26 while recv_size < data_size: 27 28 data = t.recv(1024) 29 recv_size += len(data) 30 recv_data += data 31 print(recv_data.decode('utf8')) #基于windows的shell 用GBK解码 32 #基于linux的shell 用utf8解码 33 34 t.close()
模拟远程访问ssh
1 from socket import * 2 import subprocess 3 t = socket(AF_INET,SOCK_STREAM) #两个参数 基于网络通信的套接字,基于tcp协议的套接字 4 t.bind(('127.0.0.1',8080)) #绑定唯一一个IP地址和端口号 此处为本地回环地址 5 t.listen(5) #开启监听 同时允许最多5个客户端访问 6 7 while True: #链接循环 8 conn,addr = t.accept() #等待客户端链接 9 while True: # 通信循环 10 try: #应对windows系统 客户端关闭链接的情况下 11 cmd = conn.recv(1024) #接收客户端消息 每次接收1024字节的数据 12 if not cmd:break #应对linux系统 服务器不断的接收空 13 res = subprocess.Popen(cmd.decode('utf8'), 14 shell = True, 15 stdout = subprocess.PIPE, 16 stderr= subprocess.PIPE) 17 conn.send(res.stdout.read()) # linux环境中 多个命令用分号隔开的情况 18 conn.send(res.stderr.read()) 19 20 21 err = res.stderr.read() #只有一个命令的情况下 22 if err : 23 cmd_res = err 24 else: 25 cmd_res = res.stdout.read() 26 conn.send(cmd_res) 27 except Exception: 28 break 29 conn.close() #通信完成,关闭链接 30 t.close()
1 from socket import * 2 t =socket(AF_INET,SOCK_STREAM) 3 t.connect(('192.168.184.128',8280)) 4 5 while True: #通信循环 6 cmd = input('>>> :') 7 if not cmd: continue 8 t.send(cmd.encode('utf8')) 9 data = t.recv(1024) 10 print(data.decode('utf8')) #基于windows的shell 用GBK解码 11 #基于linux的shell 用utf8解码 12 13 t.close()
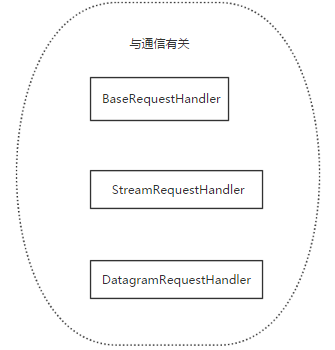
socketserver实现并发
基于tcp的套接字,关键就是两个循环,一个链接循环,一个通信循环
socketserver模块中分两大类:server类(解决链接问题)和request类(解决通信问题)
server类:

request类:
继承关系:

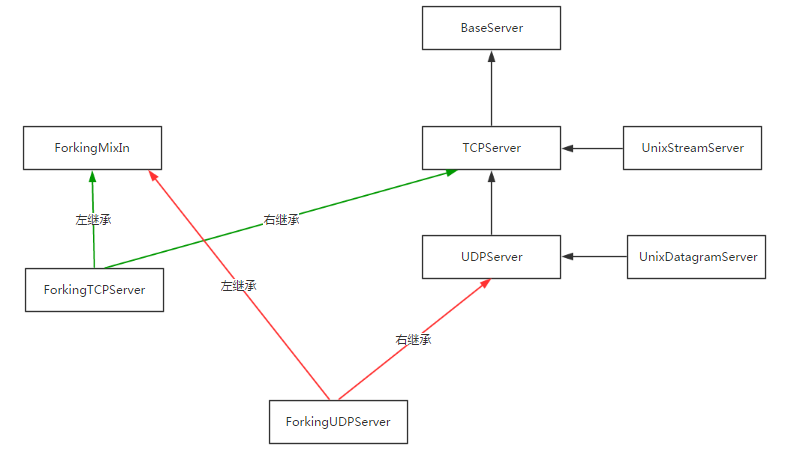
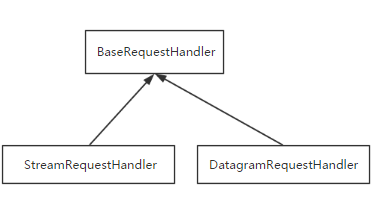
tcp协议下的并发问题
1 #服务端 2 import socketserver 3 4 class Ftpserver(socketserver.BaseRequestHandler): #通信链接 5 def handle(self): 6 print('==========>',self) 7 print(self.request) #self.request == conn 8 while True: 9 data = self.request.recv(1024) 10 print(data.decode('utf8')) 11 data1 =input('>>') 12 self.request.send(data1.encode('utf8')) 13 14 if __name__ == '__main__': 15 obj = socketserver.ThreadingTCPServer(('127.0.0.1',8080),Ftpserver) 16 obj.serve_forever()#链接循环
udp协议下的并发问题
1 import socketserver 2 class Ftpserver(socketserver.BaseRequestHandler): 3 def handle(self): 4 print(self.request) 5 print(self.client_address) 6 # msg = input('>>>:') 7 self.request[1].sendto(self.request[0],self.client_address) 8 9 if __name__ == '__main__': 10 obj = socketserver.ThreadingUDPServer(('127.0.0.1',8080),Ftpserver) 11 obj.serve_forever()
socketserver源码分析:
SocketServer的ThreadingTCPServer之所以可以同时处理请求得益于 select 和 Threading 两个东西,其实本质上就是在服务器端为每一个客户端创建一个线程,当前线程用来处理对应客户端的请求,所以,可以支持同时n个客户端链接(长连接)
1 启动服务端程序 2 执行 TCPServer.__init__ 方法,创建服务端Socket对象并绑定 IP 和 端口 3 执行 BaseServer.__init__ 方法,将自定义的继承自SocketServer.BaseRequestHandler 的类 MyRequestHandle赋值给 self.RequestHandlerClass 4 执行 BaseServer.server_forever 方法,While 循环一直监听是否有客户端请求到达 ... 5 当客户端连接到达服务器 6 执行 ThreadingMixIn.process_request 方法,创建一个 “线程” 用来处理请求 7 执行 ThreadingMixIn.process_request_thread 方法 8 执行 BaseServer.finish_request 方法,执行 self.RequestHandlerClass() 即:执行 自定义 MyRequestHandler 的构造方法(自动调用基类BaseRequestHandler的构造方法,在该构造方法中又会调用 MyRequestHandler的handle方法)
简单例子实现源码重现:
1 import socket 2 import threading 3 import select 4 5 def process(request,client_address): 6 print(request,client_address) 7 conn = request 8 conn.sendall('欢迎致电10086,请输入。。。。'.encode('utf8')) 9 flag = True 10 while flag: 11 data = conn.recv(1024) 12 if data == 'exit': 13 flag = False 14 elif data == '0': 15 conn.sendall('可能会被录音'.encode('utf8')) 16 else: 17 conn.sendall('重新输'.encode('utf8')) 18 19 sk = socket.socket() 20 sk.bind(('127.0.0.1',8080)) 21 sk.listen() 22 23 while True: 24 r,w,e=select.select([sk,],[],[],1) 25 if sk in r: 26 print('get request') 27 request,client_address = sk.accept() 28 t = threading.Thread(target=process,args=(request,client_address)) 29 t.start() 30 sk.close()
应用:
FTP上传下载
1. 用户登陆
2. 上传/下载文件
3. 不同用户家目录不同
4. 查看当前目录下文件
5. 充分使用面向对象知识
6. 用户加密认证
7. 多用户同时登陆
8. 每个用户有自己的家目录且只能访问自己的家目录
9. 对用户进行磁盘配额、不同用户配额可不同
10. 用户可以登陆server后,可切换目录
11. 查看当前目录下文件
12. 上传下载文件,保证文件一致性
13. 传输过程中现实进度条
14. 支持断点续传