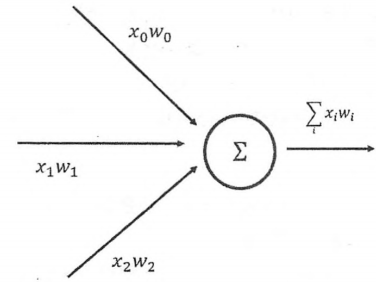
一个神经元有多个输入和一个输出。
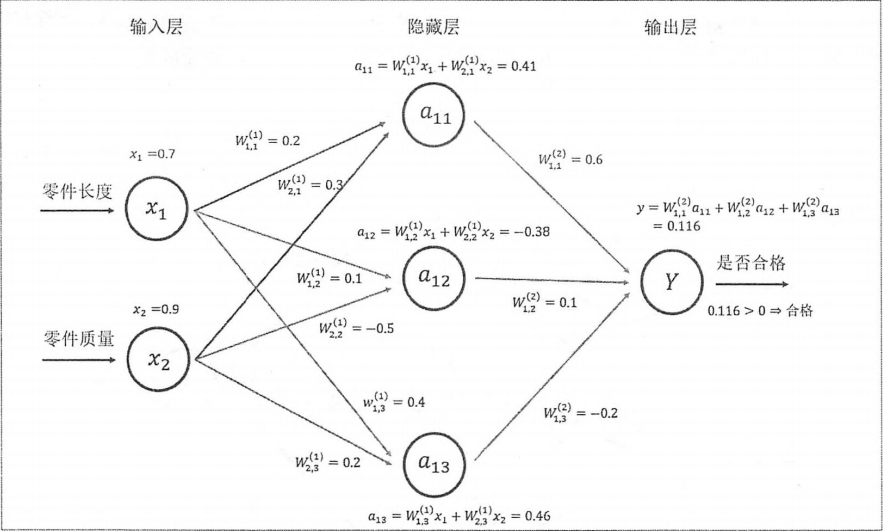
一个最简单的神经元结构。(全连接层)图上已标明计算过程。
把权重W组织成一个矩阵:
 第一层。
第一层。
通过矩阵乘法得到隐藏层三个节点的输出
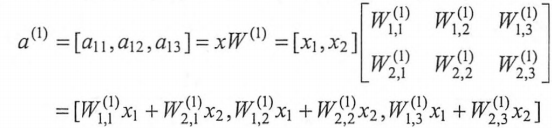
最后的输出层:
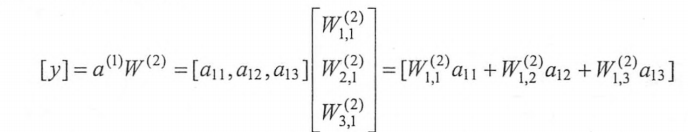
代码:
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1)) b1 = tf.Variable(tf.zeros([256])) w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1)) b2 = tf.Variable(tf.zeros([128])) w3 = tf.Variable(tf.random.truncated_normal([128, 10], stddev=0.1)) b3 = tf.Variable(tf.zeros([10])) lr = 1e-3 for epoch in range(10): # iterate db for 10 for step, (x, y) in enumerate(train_db): # for every batch # x:[128, 28, 28] # y: [128] # [b, 28, 28] => [b, 28*28] x = tf.reshape(x, [-1, 28*28]) with tf.GradientTape() as tape: # tf.Variable # x: [b, 28*28] # h1 = x@w1 + b1 # [b, 784]@[784, 256] + [256] => [b, 256] + [256] => [b, 256] + [b, 256] h1 = x@w1 + tf.broadcast_to(b1, [x.shape[0], 256]) h1 = tf.nn.relu(h1) # [b, 256] => [b, 128] h2 = h1@w2 + b2 h2 = tf.nn.relu(h2) # [b, 128] => [b, 10] out = h2@w3 + b3 # compute loss # out: [b, 10] # y: [b] => [b, 10] y_onehot = tf.one_hot(y, depth=10) # mse = mean(sum(y-out)^2) # [b, 10] loss = tf.square(y_onehot - out) # mean: scalar loss = tf.reduce_mean(loss) # compute gradients grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3]) # print(grads) # w1 = w1 - lr * w1_grad w1.assign_sub(lr * grads[0]) b1.assign_sub(lr * grads[1]) w2.assign_sub(lr * grads[2]) b2.assign_sub(lr * grads[3]) w3.assign_sub(lr * grads[4]) b3.assign_sub(lr * grads[5]) if step % 100 == 0: print(epoch, step, 'loss:', float(loss))
解释:
在TensorFlow中,变量(tf.Variable)的作用就是保存以及使用神经网络参数。和一门编程语言类似,TensorFlow变量也需要赋予初始值,我们这里的初始化方法是产生一个矩阵,矩阵的元素的均值和标准差可以设定,满足正态分布。