---恢复内容开始---
回顾:
1.最终开发MR的计算程序
2.hadoop 2.x 出现了一个yarn:资源管理>>MR没有后台场服务
yarn模型:container 容器,里面会运行我们的AppMaster,map/reduce Task
解耦
mapreduce on yarn
架构:RM NM
搭建:
RM要和NN岔开,NM个数要和DN一样
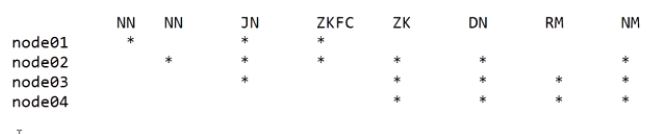
搭建图
----------通过官网:
mapred-site.xml > mapreduce on yarn
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
yarn-site.xml
//shuffle 洗牌 M -shuffle> R <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>node02:2181,node03:2181,node04:2181</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>mashibing</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>node03</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node04</value> </property>
流程:
我hdfs等所有的都用root来操作的
node01:
cd $HADOOP_HOME/etc/hadoop cp mapred-site.xml.template mapred-site.xml vi mapred-site.xml vi yarn-site.xml scp mapred-site.xml yarn-site.xml node02:`pwd` scp mapred-site.xml yarn-site.xml node03:`pwd` scp mapred-site.xml yarn-site.xml node04:`pwd` vi slaves //可以不用管,搭建hdfs时候已经改过了。。。 start-yarn.sh node03~04: yarn-daemon.sh start resourcemanager http://node03:8088 http://node04:8088 This is standby RM. Redirecting to the current active RM: http://node03:8088/
-------MR 官方案例使用:wc
实战:MR ON YARN 的运行方式:
hdfs dfs -mkdir -p /data/wc/input hdfs dfs -D dfs.blocksize=1048576 -put data.txt /data/wc/input cd $HADOOP_HOME cd share/hadoop/mapreduce hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/wc/input /data/wc/output
1)webui:
2)cli:
hdfs dfs -ls /data/wc/output
-rw-r--r-- 2 root supergroup 0 2019-06-22 11:37 /data/wc/output/_SUCCESS //标志成功的文件 -rw-r--r-- 2 root supergroup 788922 2019-06-22 11:37 /data/wc/output/part-r-00000 //数据文件 part-r-00000 part-m-00000 r/m : map+reduce r / map m hdfs dfs -cat /data/wc/output/part-r-00000 hdfs dfs -get /data/wc/output/part-r-00000 ./
抛出一个问题:
data.txt 上传会切割成2个block 计算完,发现数据是对的~!~?后边注意听源码分析~!~~