foreach 后面in 传入的参数有1万条,#和$是有效率区别的,$的效率远高于#,上篇文章做了比较。
但没达到我的理想结果。
1. 更改方式,把foreach 去掉,改成拼装方式, 参数直接拼装成 ‘1,2,3,4,5,6’ ,然后传入mybatis 中,dev_id in ${devIds},这里只能用$, 不能用#,#加了引号,实际
到数据库的SQL 是 dev_id in ('1,2,3,4,5,6') 而不是 dev_id in (1,2,3,4,5,6) ,所以查不到结果。但是更改成这样,仍然比foreach的$ 提升一倍的时间,不理想。
2. 继续更改方式,换成exists, 这货和in 在主表数据和子表数据一样多的情况,实际效率差不多,只有当主表数据比子表数据多,用in快,主表数据比子表数据少,用exists, 实际上我这里不是数据库的瓶颈,把这条SQL传入1万条ID作为参数在客户端的工具里查询,花费也就100毫秒左右。所以,我打算用exists试一试。
<if test="devIds != null and devIds != ''"> and EXISTS (select 1 from (SELECT regexp_split_to_table(#{devIds},',') AS dev_id) AS vir where cast(vir.dev_id as BIGINT) = sd.id) </if>
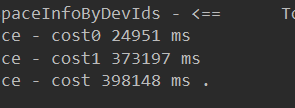
把送来的devIds 字符串进行行转列,然后进行exists, 我这里dev_id字段类型为BIGINT,数据库为Postgresql。我把数据库的数据由1万改为100万条数据,传入的参数由1万改成20万,in 消耗的时间如下图的cost1, 373秒:
exists 消耗的时间如下图cost1 , 2秒不到:
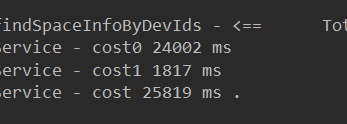
这样,就算是解决了in的效率问题。我们系统达不到100万级别的数量级,可能最多就10万。足矣