Redis在日常部署的时候,可以有多种部署模式:单机、主从、哨兵、集群(分区分片),因此本例将对上面这四种模式进行详细的讲解,特别是集群模式将进行最细致的讲解(现行普遍使用的方式)。
一、单机部署
单机部署很简单,直接下载Redis进行安装即可,此处不作详细讲解,具体Redis的安装请参考:Mac下安装Redis及Redis Desktop Manager,Windows以及Linux下的安装没啥不同。
单机模式部署有自己的优缺点,可以根据自己需要进行使用,优点如下:
- 架构简单,部署方便;
- 高性价比:缓存使用时无需备用节点(单实例可用性可以用supervisor或crontab保证),当然为了满足业务的高可用性,也可以牺牲一个备用节点,但同时刻只有一个实例对外提供服务;
- 高性能。
缺点如下:
- 不保证数据的可靠性;
- 在缓存使用,进程重启后,数据丢失,即使有备用的节点解决高可用性,但是仍然不能解决缓存预热问题,因此不适用于数据可靠性要求高的业务;
- 高性能受限于单核CPU的处理能力(Redis是单线程机制),CPU为主要瓶颈,所以适合操作命令简单,排序、计算较少的场景。也可以考虑用Memcached替代。
二、主从模式
1、主从结构
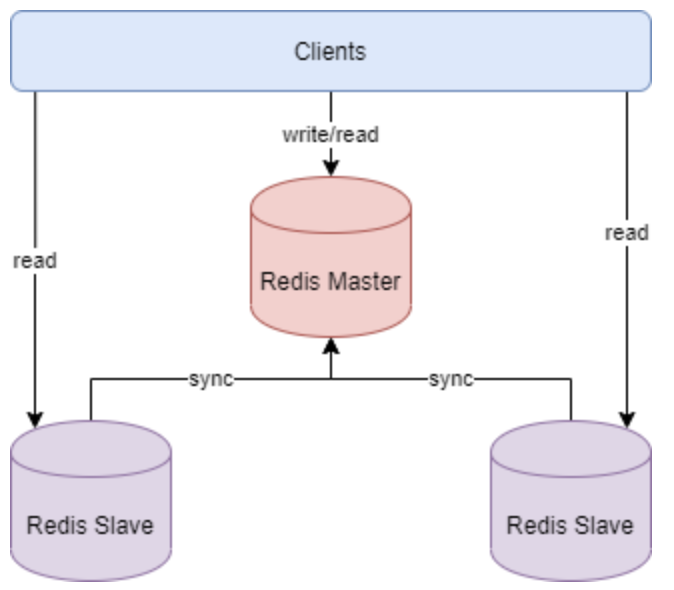
主节点负责写数据,从节点负责读数据,主节点定期把数据同步到从节点保证数据的一致性。其结构图如下所示:
2、主从部署
关于主从的部署,本博文以在本地机器上一主一从部署为例:
- 首先进入Redis安装目录下复制一个redis.conf,并命名为redis6380.conf,然后修改配置文件中对应port字段:
90 # Accept connections on the specified port, default is 6379 (IANA #815344). 91 # If port 0 is specified Redis will not listen on a TCP socket. 92 port 6380
- 进入到Redis安装目录下的bin目录,执行命令 ./redis-server ../redis.conf & 启动master服务器;
- 执行命令 ./redis-server ../redis6380.conf --slaveof 127.0.0.1 6379 & 启动slave服务器;
- 执行命令 ps -ef |grep redis 查看进程启动情况:
192:bin jing$ ps -ef |grep redis 501 40619 1 0 9:46下午 ?? 0:00.45 ./redis-server 127.0.0.1:6379 501 40631 1 0 9:48下午 ?? 0:00.07 ./redis-server 127.0.0.1:6380 501 40627 35166 0 9:47下午 ttys000 0:00.01 sh redis.sh client 501 40628 40627 0 9:47下午 ttys000 0:00.01 ./bin/redis-cli 501 40634 39629 0 9:49下午 ttys001 0:00.00 grep redis
此时可以在bin目录下执行命令 ./redis-cli -p 端口号port 登录客户端,执行命令 info replication 查看主从关系如下:

127.0.0.1:6379> info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6380,state=online,offset=1540,lag=0 master_replid:741d8f4ad091909f7c3eded3ecc75c2f75a15810 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:1540 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:1540 127.0.0.1:6380> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:1 master_sync_in_progress:0 slave_repl_offset:1736 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:741d8f4ad091909f7c3eded3ecc75c2f75a15810 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:1736 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:1736
3、主从验证
此时在master节点添加数据,可以从从节点得到数据,但是从节点只能读无法写,如例:
127.0.0.1:6379> get monkey (nil) 127.0.0.1:6379> set monkey 12345 OK 127.0.0.1:6379> get monkey "12345" 127.0.0.1:6380> get monkey (nil) 127.0.0.1:6380> get monkey "12345" 127.0.0.1:6380> set monkey2 123 (error) READONLY You can't write against a read only replica.
可以看到从节点是READONLY状态。
4、主节点宕机从节点顶替
如果我们关闭主节点,然后看主从节点状态:
127.0.0.1:6379> info replication Could not connect to Redis at 127.0.0.1:6379: Connection refused 127.0.0.1:6380> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:down master_last_io_seconds_ago:-1 master_sync_in_progress:0 slave_repl_offset:2411 master_link_down_since_seconds:13 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:741d8f4ad091909f7c3eded3ecc75c2f75a15810 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:2411 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:2411
要想此时从节点顶替主节点,在从节点执行 slaveof no one 即可:
127.0.0.1:6380> slaveof no one OK 127.0.0.1:6380> info replication # Replication role:master connected_slaves:0 master_replid:0f989ed96bc8cbc0d5d1c3979258e75e94903e51 master_replid2:741d8f4ad091909f7c3eded3ecc75c2f75a15810 master_repl_offset:2411 second_repl_offset:2412 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:2411
5、宕机节点恢复
此时可以重新执行命令 ./redis-server ../redis6380.conf --slaveof 127.0.0.1 6379 & 把原先宕机并恢复的节点挂到新的master节点之上。
6、主从工作机制
主从具体工作机制为(全量复制(初始化)+增量复制):
- slave启动后,向master发送SYNC命令,master接收到SYNC命令后通过bgsave保存快照(即上文所介绍的RDB持久化),并使用缓冲区记录保存快照这段时间内执行的写命令;
- master将保存的快照文件发送给slave,并继续记录执行的写命令;
- slave接收到快照文件后,加载快照文件,载入数据;
- master快照发送完后开始向slave发送缓冲区的写命令,slave接收命令并执行,完成复制初始化;
- 此后master每次执行一个写命令都会同步发送给slave,保持master与slave之间数据的一致性。
7、redis.conf主要配置说明
###网络相关### # bind 127.0.0.1 # 绑定监听的网卡IP,注释掉或配置成0.0.0.0可使任意IP均可访问 protected-mode no # 关闭保护模式,使用密码访问 port 6379 # 设置监听端口,建议生产环境均使用自定义端口 timeout 30 # 客户端连接空闲多久后断开连接,单位秒,0表示禁用 ###通用配置### daemonize yes # 在后台运行 pidfile /var/run/redis_6379.pid # pid进程文件名 logfile /usr/local/redis/logs/redis.log # 日志文件的位置 ###RDB持久化配置### save 900 1 # 900s内至少一次写操作则执行bgsave进行RDB持久化 save 300 10 save 60 10000 # 如果禁用RDB持久化,可在这里添加 save "" rdbcompression yes #是否对RDB文件进行压缩,建议设置为no,以(磁盘)空间换(CPU)时间 dbfilename dump.rdb # RDB文件名称 dir /usr/local/redis/datas # RDB文件保存路径,AOF文件也保存在这里 ###AOF配置### appendonly yes # 默认值是no,表示不使用AOF增量持久化的方式,使用RDB全量持久化的方式 appendfsync everysec # 可选值 always, everysec,no,建议设置为everysec ###设置密码### requirepass 123456 # 设置复杂一点的密码
8、主从配置优缺点
优点:
- master能自动将数据同步到slave,可以进行读写分离,分担master的读压力;
- master、slave之间的同步是以非阻塞的方式进行的,同步期间,客户端仍然可以提交查询或更新请求。
缺点:
- 不具备自动容错与恢复功能,master或slave的宕机都可能导致客户端请求失败,需要等待机器重启或手动切换客户端IP才能恢复;
- master宕机,如果宕机前数据没有同步完,则切换IP后会存在数据不一致的问题;
- 难以支持在线扩容,Redis的容量受限于单机配置。
三、哨兵模式
1、哨兵结构
由于无法进行主动恢复,因此主从模式衍生出了哨兵模式。哨兵模式基于主从复制模式,只是引入了哨兵来监控与自动处理故障。如图:

哨兵顾名思义,就是来为Redis集群站哨的,一旦发现问题能做出相应的应对处理。其功能包括:
- 监控master、slave是否正常运行;
- 当master出现故障时,能自动将一个slave转换为master;
- 多个哨兵可以监控同一个Redis,哨兵之间也会自动监控。
2、哨兵部署
哨兵模式基于前面的主从复制模式。哨兵的配置文件为Redis安装目录下的sentinel.conf文件,在文件中配置如下配置文件:
port 26379 # 哨兵端口 # mymaster定义一个master数据库的名称,后面是master的ip, port,1表示至少需要一个Sentinel进程同意才能将master判断为失效,如果不满足这个条件,则自动故障转移(failover)不会执行 sentinel monitor mymaster 127.0.0.1 6379 1 sentinel auth-pass mymaster 123456 # master的密码 sentinel down-after-milliseconds mymaster 5000 #5s未回复PING,则认为master主观下线,默认为30s # 指定在执行故障转移时,最多可以有多少个slave实例在同步新的master实例,在slave实例较多的情况下这个数字越小,同步的时间越长,完成故障转移所需的时间就越长 sentinel parallel-syncs mymaster 2 # 如果在该时间(ms)内未能完成故障转移操作,则认为故障转移失败,生产环境需要根据数据量设置该值 sentinel failover-timeout mymaster 300000 daemonize yes #用来指定redis是否要用守护线程的方式启动,默认为no #保护模式如果开启只接受回环地址的ipv4和ipv6地址链接,拒绝外部链接,而且正常应该配置多个哨兵,避免一个哨兵出现独裁情况 #如果配置多个哨兵那如果开启也会拒绝其他sentinel的连接。导致哨兵配置无法生效 protected-mode no logfile "/data/redis/logs/sentinel.log" #指明日志文件
其中daemonize的值yes和no的区别为:
- daemonize:yes: redis采用的是单进程多线程的模式。当redis.conf中选项daemonize设置成yes时,代表开启守护进程模式。在该模式下,redis会在后台运行,并将进程pid号写入至redis.conf选项pidfile设置的文件中,此时redis将一直运行,除非手动kill该进程。
- daemonize:no: 当daemonize选项设置成no时,当前界面将进入redis的命令行界面,exit强制退出或者关闭连接工具(putty,xshell等)都会导致redis进程退出。
然后就是启动哨兵,启动方式有两种,先进入Redis安装根目录下的bin目录,然后执行:
/server-sentinel ../sentinel.conf &
# 或者
redis-server sentinel.conf --sentinel
执行后可以看到有哨兵进程已启动,如下:
192:bin houjing$ ps -ef |grep redis 501 41115 1 0 11:37下午 ?? 0:12.00 ./redis-server 127.0.0.1:6379 501 41121 1 0 11:38下午 ?? 0:11.88 ./redis-server 127.0.0.1:6380 501 41621 1 0 3:53上午 ?? 0:00.04 ./redis-server *:26379 [sentinel]
可以多个哨兵监控一个master数据库,只需按上述配置添加多套sentinel.conf配置文件,比如分别为sentinel1.conf、sentinel2.conf、sentinel3.conf,分别以26379,36379,46379端口启动三个sentinel,此时就成功配置多个哨兵,成功部署了一套3个哨兵、一个master、2个slave的Redis集群。
3、master节点宕机测试
我们通过手动杀掉master节点进行测试,然后看slave节点是否会自动晋升为master节点:
192:bin houjing$ kill -9 41115 192:bin houjing$ ps -ef |grep redis 501 41121 1 0 11:38下午 ?? 0:12.33 ./redis-server 127.0.0.1:6380 501 41621 1 0 3:53上午 ?? 0:00.68 ./redis-server *:26379 [sentinel] 127.0.0.1:6379> info replication Could not connect to Redis at 127.0.0.1:6379: Connection refused 127.0.0.1:6380> info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:1 master_sync_in_progress:0 slave_repl_offset:14604 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:85362a9182cf9a48d1f93b0633e1963b583c30f7 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:14604 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:14604 127.0.0.1:6380> info replication # Replication role:master connected_slaves:0 master_replid:36bf84c3cb3f2b7969040fdcce9a962025be3605 master_replid2:85362a9182cf9a48d1f93b0633e1963b583c30f7 master_repl_offset:16916 second_repl_offset:15963 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:16916
可以看到验证成功,然后我们重启原先宕机的master节点,可以看到原先的节点成功启动,并由master变成了slave节点,如下所示:
-cli -p 6380 192:bin houjing$ ./redis-server ../redis.conf & [1] 41640 192:bin houjing$ 41640:C 07 Apr 2020 03:59:05.475 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 41640:C 07 Apr 2020 03:59:05.475 # Redis version=5.0.4, bits=64, commit=00000000, modified=0, pid=41640, just started 41640:C 07 Apr 2020 03:59:05.475 # Configuration loaded [1]+ Done ./redis-server ../redis.conf 192:bin houjing$ ps -ef |grep redis 501 41121 1 0 11:38下午 ?? 0:12.82 ./redis-server 127.0.0.1:6380 501 41621 1 0 3:53上午 ?? 0:01.49 ./redis-server *:26379 [sentinel] 501 41641 1 0 3:59上午 ?? 0:00.02 ./redis-server 127.0.0.1:6379 127.0.0.1:6379> info replication # Replication role:slave master_host:127.0.0.1 master_port:6380 master_link_status:up master_last_io_seconds_ago:1 master_sync_in_progress:0 slave_repl_offset:29056 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:36bf84c3cb3f2b7969040fdcce9a962025be3605 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:29056 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:28488 repl_backlog_histlen:569
以上就完成了对哨兵部署方式的测试,那么哨兵的工作原理是什么呢?
4、哨兵工作机制
在配置文件中通过 sentinel monitor <master-name> <ip> <redis-port> <quorum> 来定位master的IP、端口,一个哨兵可以监控多个master数据库,只需要提供多个该配置项即可。哨兵启动后,会与要监控的master建立两条连接:
- 一条连接用来订阅master的
_sentinel_:hello频道与获取其他监控该master的哨兵节点信息。 - 另一条连接定期向master发送INFO等命令获取master本身的信息。
与master建立连接后,哨兵会执行三个操作:
- 定期(一般10s一次,当master被标记为主观下线时,改为1s一次)向master和slave发送INFO命令。
- 定期向master和slave的
_sentinel_:hello频道发送自己的信息。 - 定期(1s一次)向master、slave和其他哨兵发送PING命令。
发送INFO命令可以获取当前数据库的相关信息从而实现新节点的自动发现。所以说哨兵只需要配置master数据库信息就可以自动发现其slave信息。获取到slave信息后,哨兵也会与slave建立两条连接执行监控。通过INFO命令,哨兵可以获取主从数据库的最新信息,并进行相应的操作,比如角色变更等。
接下来哨兵向主从数据库的_sentinel_:hello频道发送信息与同样监控这些数据库的哨兵共享自己的信息,发送内容为哨兵的ip端口、运行id、配置版本、master名字、master的ip端口还有master的配置版本。这些信息有以下用处:
- 其他哨兵可以通过该信息判断发送者是否是新发现的哨兵,如果是的话会创建一个到该哨兵的连接用于发送PING命令。
- 其他哨兵通过该信息可以判断master的版本,如果该版本高于直接记录的版本,将会更新。
- 当实现了自动发现slave和其他哨兵节点后,哨兵就可以通过定期发送PING命令定时监控这些数据库和节点有没有停止服务。
如果被PING的数据库或者节点超时(通过 sentinel down-after-milliseconds master-name milliseconds 配置)未回复,哨兵认为其主观下线(sdown,s就是Subjectively —— 主观地)。如果下线的是master,哨兵会向其它哨兵发送命令询问它们是否也认为该master主观下线,如果达到一定数目(即配置文件中的quorum)投票,哨兵会认为该master已经客观下线(odown,o就是Objectively —— 客观地),并选举领头的哨兵节点对主从系统发起故障恢复。若没有足够的sentinel进程同意master下线,master的客观下线状态会被移除,若master重新向sentinel进程发送的PING命令返回有效回复,master的主观下线状态就会被移除。
哨兵认为master客观下线后,故障恢复的操作需要由选举的领头哨兵来执行,选举采用Raft算法:
- 发现master下线的哨兵节点(我们称他为A)向每个哨兵发送命令,要求对方选自己为领头哨兵。
- 如果目标哨兵节点没有选过其他人,则会同意选举A为领头哨兵。
- 如果有超过一半的哨兵同意选举A为领头,则A当选。
- 如果有多个哨兵节点同时参选领头,此时有可能存在一轮投票无竞选者胜出,此时每个参选的节点等待一个随机时间后再次发起参选请求,进行下一轮投票竞选,直至选举出领头哨兵。
选出领头哨兵后,领头者开始对系统进行故障恢复,从出现故障的master的从数据库中挑选一个来当选新的master,选择规则如下:
- 所有在线的slave中选择优先级最高的,优先级可以通过slave-priority配置。
- 如果有多个最高优先级的slave,则选取复制偏移量最大(即复制越完整)的当选。
- 如果以上条件都一样,选取id最小的slave。
- 挑选出需要继任的slave后,领头哨兵向该数据库发送命令使其升格为master,然后再向其他slave发送命令接受新的master,最后更新数据。将已经停止的旧的master更新为新的master的从数据库,使其恢复服务后以slave的身份继续运行。
5、哨兵模式的优缺点
优点:
- 哨兵模式基于主从复制模式,所以主从复制模式有的优点,哨兵模式也有。
- 哨兵模式下,master挂掉可以自动进行切换,系统可用性更高。
缺点:
- 同样也继承了主从模式难以在线扩容的缺点,Redis的容量受限于单机配置。
- 需要额外的资源来启动sentinel进程,实现相对复杂一点,同时slave节点作为备份节点不提供服务。
四、集群(分区分片)模式
哨兵模式解决了主从复制不能自动故障转移,达不到高可用的问题,但还是存在难以在线扩容,Redis容量受限于单机配置的问题,因此就诞生了集群模式。我们一般要实现一个Redis集群,可以有三种方式:客户端实现、Proxy代理层、服务端实现。
1、客户端实现
我们通过代码的实现方式,实现集群访问,如下图所示:
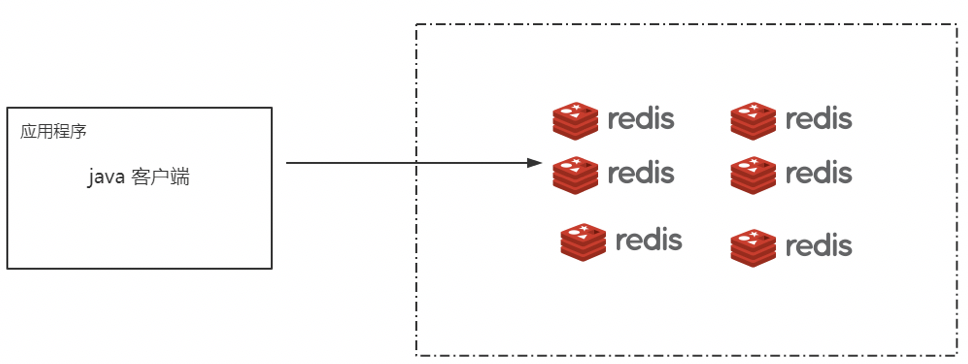
这样的访问方式都通过代码来维护集群以及访问路径,可是这样的方式 维护难度大,也不支持动态扩容,因为一切都以代码实现访问规划。
2、Proxy代理层
如图所示:
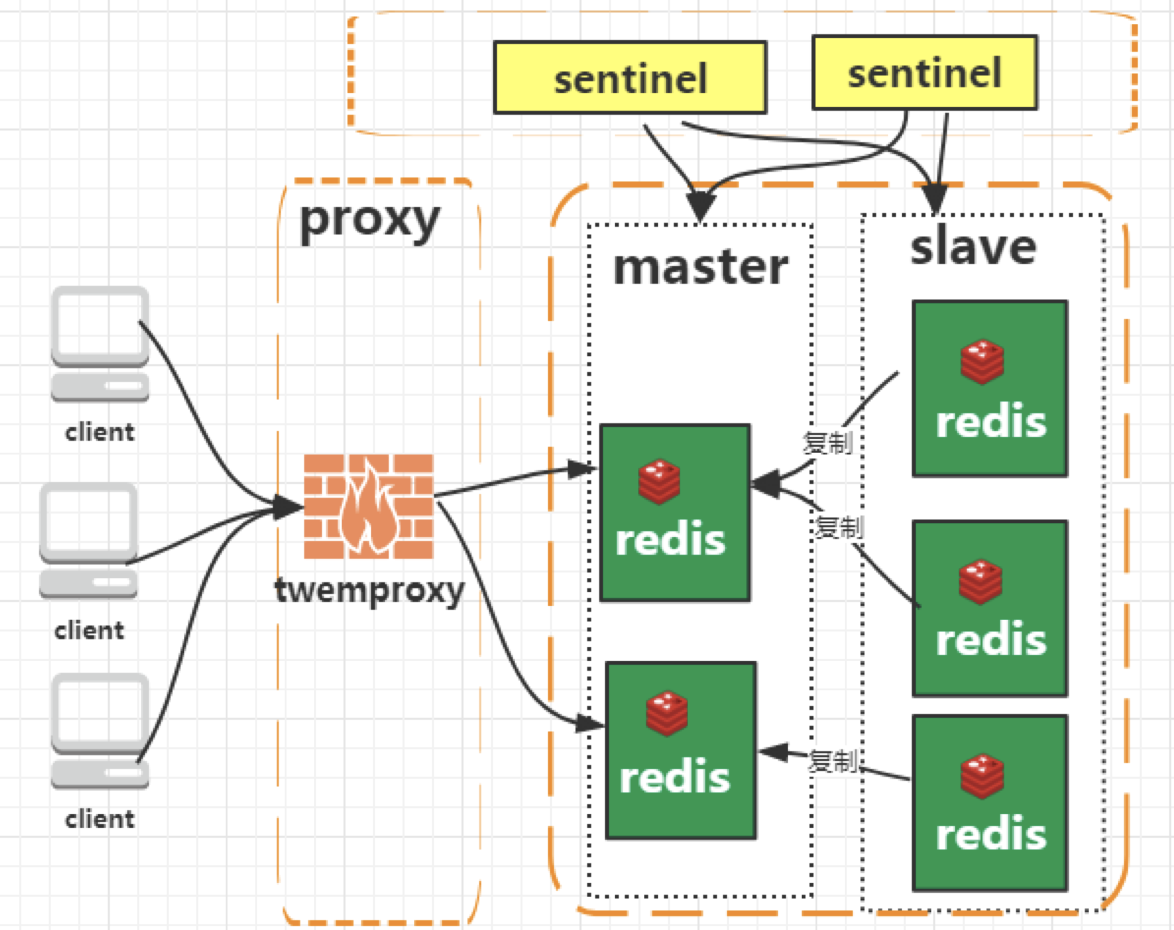
我们在Redis和我们的客户端之间新加了一层Proxy,我们通过Proxy去规划访问,这样我们在代码层面以及Redis部署层面就无需处理,而且市面上也提供了这样的中间件,如Codis(国产)、Twemproxy。我们看下Codis的架构图,就可以知道这个插件是如何工作的,如图所示:
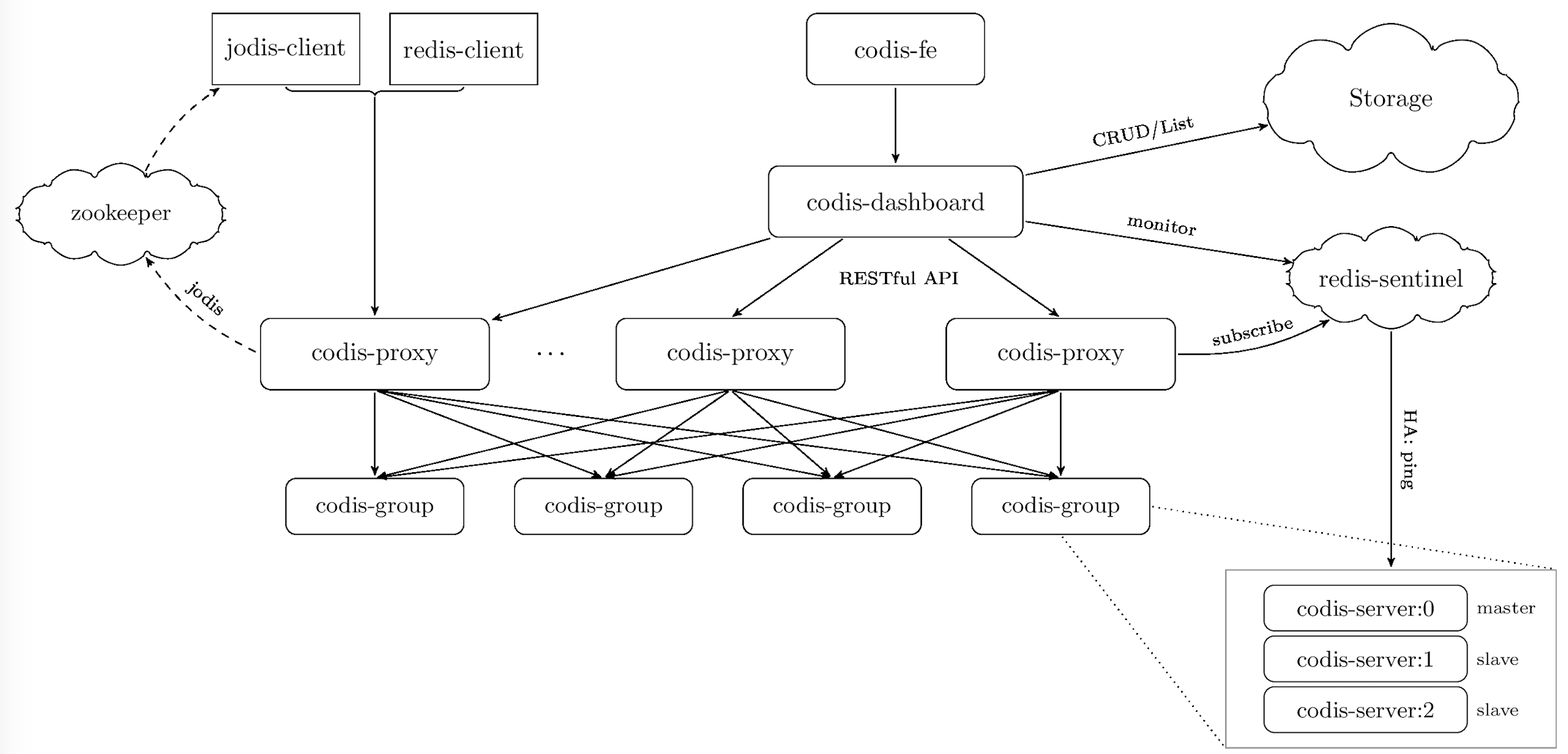
可见Codis是一个很完善的集群管理实现,我们可以不关心具体分片规则,程序开发容易简单,可是这样也有它的一些缺点:
- 相对单机、主从、哨兵可以看到,原先可以直接访问Redis,现在由于多了一层Proxy,所有访问要经过Proxy中转,性能下降。
- 我们需要依赖以及配置额外的插件(中间件),增加了系统复杂度。
Codis的GitHub地址:https://github.com/CodisLabs/codis
3、服务端实现
服务端的实现方式就是标准的集群(分区分片)模式,RedisCluster是Redis在3.0版本后推出的分布式解决方案。
3.1、集群结构
Cluster模式实现了Redis的分布式存储,即每台节点存储不同的内容,来解决在线扩容的问题。如图:
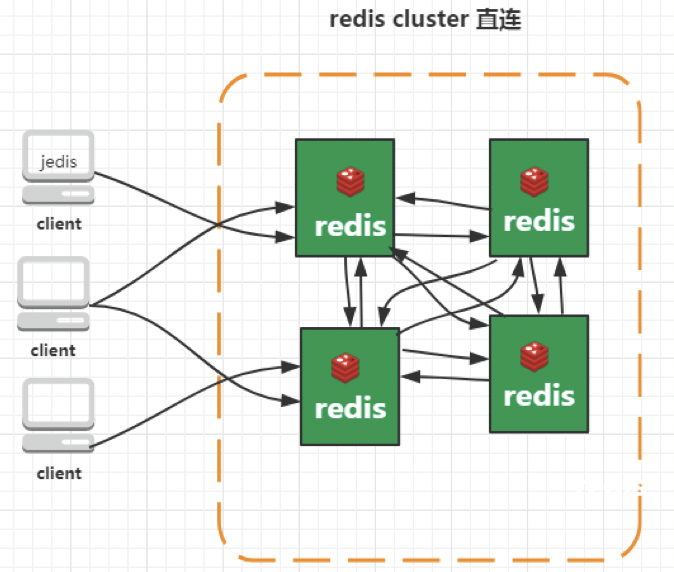
RedisCluster采用无中心结构,它的特点如下:
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
- 节点的fail是通过集群中超过半数的节点检测失效时才生效。
- 客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
3.2、Redis集群工作机制
Cluster模式的具体工作机制:
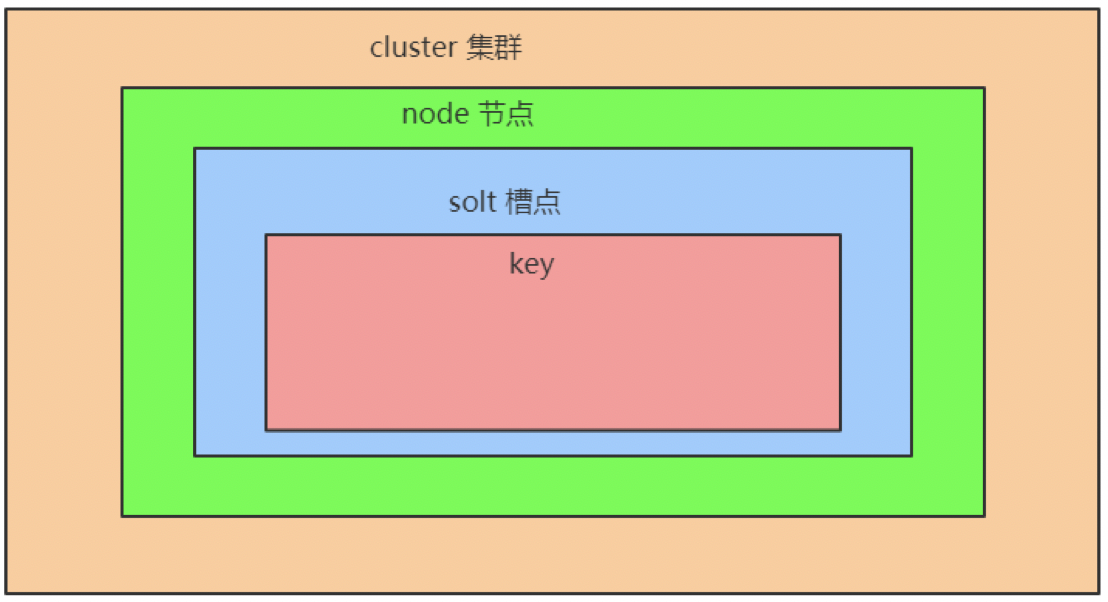
- 在Redis的每个节点上,都有一个插槽(slot),总共16384个哈希槽,取值范围为0-16383。如下图所示,跟前三种模式不同,Redis不再是默认有16(0-15)个库,也没有默认的0库说法,而是采用Slot的设计(一个集群有多个主从节点,一个主从节点上会分配多个Slot槽,每个槽点上存的是Key-Value数据):
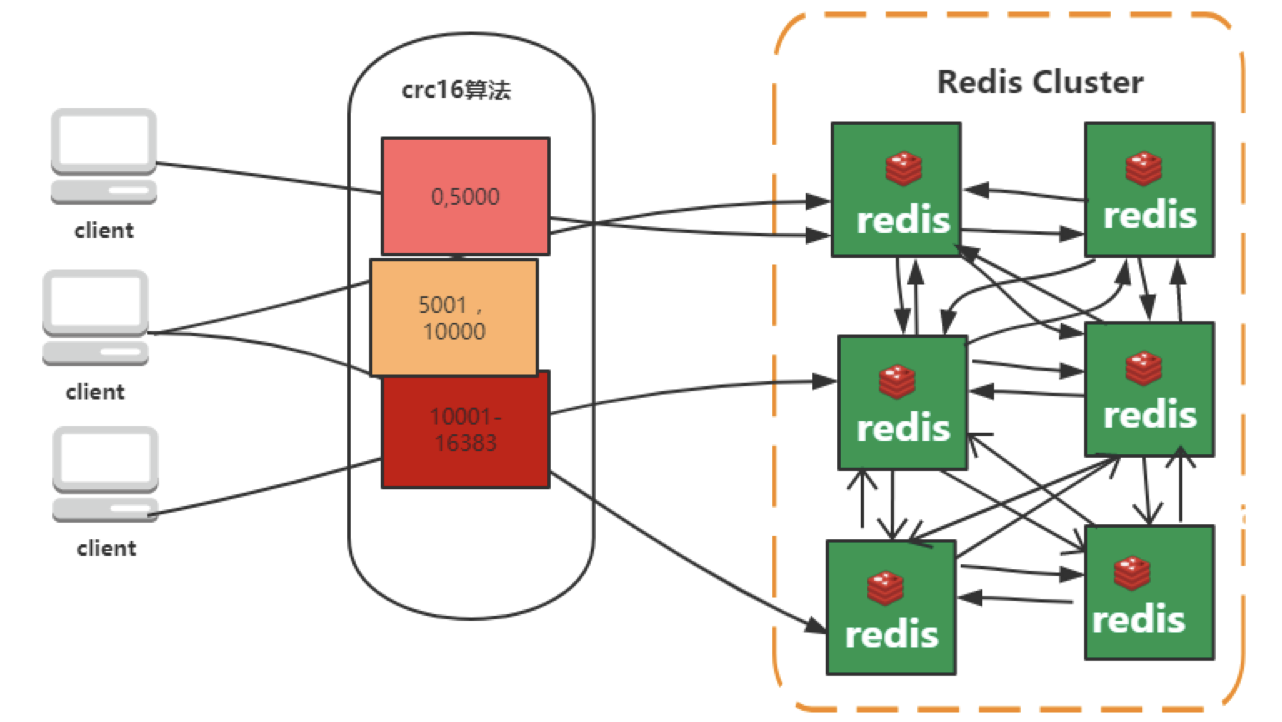
- 当我们存取key的时候,Redis会根据CRC16的算法得出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。如图所示:
- 为了保证高可用,Cluster模式也引入主从复制模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点。
- 当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点都宕机了,那么该集群就无法再提供服务了
Cluster模式集群节点最小配置6个节点(3主3从,因为需要半数以上),其中主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用。关于集群中的涉及动态选举的机制,请参考地址:http://thesecretlivesofdata.com/raft/#election
3.3、集群部署
首先我们复制6份redis.conf配置文件,分别命名为redis7001.conf、redis7002.conf、redis7003.conf、redis7004.conf、redis7005.conf、redis7006conf,存放在自己想要放的地方。
并按照下列配置信息修改配置文件:
#修改成自己对应的端口号 port #指定了记录日志的文件。 logfile #数据目录,数据库的写入会在这个目录。rdb、aof文件也会写在这个目录 dir #是否开启集群 cluster-enabled #集群配置文件的名称,每个节点都有一个集群相关的配置文件,持久化保存集群的信息。 #这个文件并不需要手动配置,这个配置文件由Redis生成并更新,每个Redis集群节点需要一个单独的配置文件,请确保与实例运行的系统中配置文件名称不冲突(建议配对应端口号) cluster-config-file nodes-6379.conf #节点互连超时的阀值。集群节点超时毫秒数 cluster-node-timeout 5000 #默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了。
#但是redis如果中途宕机,会导致可能有几分钟的数据丢失,根据save来策略进行持久化,Append Only File是另一种持久化方式,可以提供更好的持久化特性。
#Redis会把每次写入的数据在接收后都写入 appendonly.aof 文件,每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件。 appendonly appendonly yes protected-mode no #保护模式 yes改为no #bind 127.0.0.1 #注释或者去掉这个 daemonize yes #用来指定redis是否要用守护线程的方式启动,yes表示后台启动
执行命令分别启动所有节点,如:
/Volumes/work/redis-5.0.8/src/redis-server /Volumes/work/redis-5.0.8/conf/7001/redis7001.conf /Volumes/work/redis-5.0.8/src/redis-server /Volumes/work/redis-5.0.8/conf/7002/redis7002.conf /Volumes/work/redis-5.0.8/src/redis-server /Volumes/work/redis-5.0.8/conf/7003/redis7003.conf /Volumes/work/redis-5.0.8/src/redis-server /Volumes/work/redis-5.0.8/conf/7004/redis7004.conf /Volumes/work/redis-5.0.8/src/redis-server /Volumes/work/redis-5.0.8/conf/7005/redis7005.conf /Volumes/work/redis-5.0.8/src/redis-server /Volumes/work/redis-5.0.8/conf/7006/redis7006.conf
可以查看到进程:
192:conf houjing$ ps -ef |grep redis 501 43005 1 0 5:46上午 ?? 0:00.20 /Volumes/work/redis-5.0.8/src/redis-server *:7001 [cluster] 501 43018 1 0 5:47上午 ?? 0:00.02 /Volumes/work/redis-5.0.8/src/redis-server *:7002 [cluster] 501 43020 1 0 5:47上午 ?? 0:00.02 /Volumes/work/redis-5.0.8/src/redis-server *:7003 [cluster] 501 43022 1 0 5:47上午 ?? 0:00.02 /Volumes/work/redis-5.0.8/src/redis-server *:7004 [cluster] 501 43024 1 0 5:47上午 ?? 0:00.02 /Volumes/work/redis-5.0.8/src/redis-server *:7005 [cluster] 501 43026 1 0 5:47上午 ?? 0:00.01 /Volumes/work/redis-5.0.8/src/redis-server *:7006 [cluster]
执行命令创建集群:
/Volumes/work/redis-5.0.8/src/redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006
--cluster-replicas 1 # 1表示每个主节点至少一个备份
可以得到如下结果:
192:conf houjing$ /Volumes/work/redis-5.0.8/src/redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004
127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1 >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 127.0.0.1:7005 to 127.0.0.1:7001 Adding replica 127.0.0.1:7006 to 127.0.0.1:7002 Adding replica 127.0.0.1:7004 to 127.0.0.1:7003 >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master M: 4c7fcd06c55ceec27b5bbc450b99159282e7783e 127.0.0.1:7001 slots:[0-5460] (5461 slots) master M: d7a0d77d2f0fa05ccf4a14e379b52044b212607e 127.0.0.1:7002 slots:[5461-10922] (5462 slots) master M: 6494df31d4ed564d80947c9d39369cc7cfb6c0e6 127.0.0.1:7003 slots:[10923-16383] (5461 slots) master S: 9d6d78888e579442b209fca95af13b6ece4810b6 127.0.0.1:7004 replicates 6494df31d4ed564d80947c9d39369cc7cfb6c0e6 S: 8891bfe505da42298be048364ed003b83dc52139 127.0.0.1:7005 replicates 4c7fcd06c55ceec27b5bbc450b99159282e7783e S: 981ad9769245c140c0bd9ee239472dc6e2cb07eb 127.0.0.1:7006 replicates d7a0d77d2f0fa05ccf4a14e379b52044b212607e Can I set the above configuration? (type 'yes' to accept): yes 此处输入yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join ... >>> Performing Cluster Check (using node 127.0.0.1:7001) M: 4c7fcd06c55ceec27b5bbc450b99159282e7783e 127.0.0.1:7001 slots:[0-5460] (5461 slots) master 1 additional replica(s) S: 981ad9769245c140c0bd9ee239472dc6e2cb07eb 127.0.0.1:7006 slots: (0 slots) slave replicates d7a0d77d2f0fa05ccf4a14e379b52044b212607e M: 6494df31d4ed564d80947c9d39369cc7cfb6c0e6 127.0.0.1:7003 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 9d6d78888e579442b209fca95af13b6ece4810b6 127.0.0.1:7004 slots: (0 slots) slave replicates 6494df31d4ed564d80947c9d39369cc7cfb6c0e6 M: d7a0d77d2f0fa05ccf4a14e379b52044b212607e 127.0.0.1:7002 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: 8891bfe505da42298be048364ed003b83dc52139 127.0.0.1:7005 slots: (0 slots) slave replicates 4c7fcd06c55ceec27b5bbc450b99159282e7783e [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
3.4、集群检查
可以执行命令 ./redis-cli -c -p 7001 进行登录,然后查看集群信息以及slot分配信息:
192:src houjing$ ./redis-cli -c -p 7001 127.0.0.1:7001> cluster nodes 981ad9769245c140c0bd9ee239472dc6e2cb07eb 127.0.0.1:7006@17006 slave d7a0d77d2f0fa05ccf4a14e379b52044b212607e 0 1586210070424 6 connected 4c7fcd06c55ceec27b5bbc450b99159282e7783e 127.0.0.1:7001@17001 myself,master - 0 1586210069000 1 connected 0-5460 6494df31d4ed564d80947c9d39369cc7cfb6c0e6 127.0.0.1:7003@17003 master - 0 1586210071437 3 connected 10923-16383 9d6d78888e579442b209fca95af13b6ece4810b6 127.0.0.1:7004@17004 slave 6494df31d4ed564d80947c9d39369cc7cfb6c0e6 0 1586210069416 4 connected d7a0d77d2f0fa05ccf4a14e379b52044b212607e 127.0.0.1:7002@17002 master - 0 1586210070000 2 connected 5461-10922 8891bfe505da42298be048364ed003b83dc52139 127.0.0.1:7005@17005 slave 4c7fcd06c55ceec27b5bbc450b99159282e7783e 0 1586210070000 5 connected
可以根据以上得出总共有3个master节点,每个节点有一个slave节点,三个master节点分别分配了0-5460、5461-10922、10923-16383三个slot范围,7001这个master节点的slave节点为7005节点,其id为4c7fcd06c55ceec27b5bbc450b99159282e7783e。
添加数据,可以看到数据会根hash然后存到对应的slot槽,也就是存到slot槽对应的节点上,如下所示:
127.0.0.1:7001> set 789 789 -> Redirected to slot [11123] located at 127.0.0.1:7003 OK 127.0.0.1:7003> set 123 123 -> Redirected to slot [5970] located at 127.0.0.1:7002 OK 127.0.0.1:7002> set 365 365 -> Redirected to slot [5424] located at 127.0.0.1:7001 OK
当然每个节点也只有自己的那部分数据:
127.0.0.1:7001> keys * 1) "365"
3.5、宕机测试
我们通过手动杀掉节点7001的进程:
192:bin houjing$ kill 43005 192:bin houjing$ ps -ef|grep redis 501 43018 1 0 5:47上午 ?? 0:03.91 /Volumes/work/redis-5.0.8/src/redis-server *:7002 [cluster] 501 43020 1 0 5:47上午 ?? 0:03.94 /Volumes/work/redis-5.0.8/src/redis-server *:7003 [cluster] 501 43022 1 0 5:47上午 ?? 0:03.95 /Volumes/work/redis-5.0.8/src/redis-server *:7004 [cluster] 501 43024 1 0 5:47上午 ?? 0:03.92 /Volumes/work/redis-5.0.8/src/redis-server *:7005 [cluster] 501 43026 1 0 5:47上午 ?? 0:03.91 /Volumes/work/redis-5.0.8/src/redis-server *:7006 [cluster]
然后查看集群信息:
127.0.0.1:7002> cluster nodes 8891bfe505da42298be048364ed003b83dc52139 127.0.0.1:7005@17005 master - 0 1586210953749 7 connected 0-5460 9d6d78888e579442b209fca95af13b6ece4810b6 127.0.0.1:7004@17004 slave 6494df31d4ed564d80947c9d39369cc7cfb6c0e6 0 1586210953547 4 connected 981ad9769245c140c0bd9ee239472dc6e2cb07eb 127.0.0.1:7006@17006 slave d7a0d77d2f0fa05ccf4a14e379b52044b212607e 0 1586210952000 6 connected d7a0d77d2f0fa05ccf4a14e379b52044b212607e 127.0.0.1:7002@17002 myself,master - 0 1586210952000 2 connected 5461-10922 6494df31d4ed564d80947c9d39369cc7cfb6c0e6 127.0.0.1:7003@17003 master - 0 1586210952538 3 connected 10923-16383 4c7fcd06c55ceec27b5bbc450b99159282e7783e 127.0.0.1:7001@17001 master,fail - 1586210920633 1586210919825 1 disconnected
可以看到原先7001节点断开连接,其slave节点7005顶替了7001节点,变成了master节点,并继承了原先7001节点的slot槽。
当我们重新启动7001节点后,7001节点便作为7005的slave节点重新上线:
127.0.0.1:7002> cluster nodes 8891bfe505da42298be048364ed003b83dc52139 127.0.0.1:7005@17005 master - 0 1586211138837 7 connected 0-5460 9d6d78888e579442b209fca95af13b6ece4810b6 127.0.0.1:7004@17004 slave 6494df31d4ed564d80947c9d39369cc7cfb6c0e6 0 1586211138331 4 connected 981ad9769245c140c0bd9ee239472dc6e2cb07eb 127.0.0.1:7006@17006 slave d7a0d77d2f0fa05ccf4a14e379b52044b212607e 0 1586211139548 6 connected d7a0d77d2f0fa05ccf4a14e379b52044b212607e 127.0.0.1:7002@17002 myself,master - 0 1586211138000 2 connected 5461-10922 6494df31d4ed564d80947c9d39369cc7cfb6c0e6 127.0.0.1:7003@17003 master - 0 1586211139000 3 connected 10923-16383 4c7fcd06c55ceec27b5bbc450b99159282e7783e 127.0.0.1:7001@17001 slave 8891bfe505da42298be048364ed003b83dc52139 0 1586211137522 7 connected
3.6、水平扩展
由于我们Redis集群是有能力限制的,当不能满足当下要求的时候,就需要进行扩容,这事就涉及到水平扩展,我们先增加两份配置文件redis7007.conf、redis7008.conf,并创建两个节点并启动:
192:conf houjing$ /Volumes/work/redis-5.0.8/src/redis-server /Volumes/work/redis-5.0.8/conf/7007/redis7007.conf 192:conf houjing$ /Volumes/work/redis-5.0.8/src/redis-server /Volumes/work/redis-5.0.8/conf/7008/redis7008.conf 192:conf houjing$ ps -ef |grep redis 501 43018 1 0 5:47上午 ?? 0:06.27 /Volumes/work/redis-5.0.8/src/redis-server *:7002 [cluster] 501 43020 1 0 5:47上午 ?? 0:06.29 /Volumes/work/redis-5.0.8/src/redis-server *:7003 [cluster] 501 43022 1 0 5:47上午 ?? 0:06.29 /Volumes/work/redis-5.0.8/src/redis-server *:7004 [cluster] 501 43024 1 0 5:47上午 ?? 0:06.25 /Volumes/work/redis-5.0.8/src/redis-server *:7005 [cluster] 501 43026 1 0 5:47上午 ?? 0:06.24 /Volumes/work/redis-5.0.8/src/redis-server *:7006 [cluster] 501 43109 1 0 6:12上午 ?? 0:01.31 /Volumes/work/redis-5.0.8/src/redis-server *:7001 [cluster] 501 43141 1 0 6:18上午 ?? 0:00.03 /Volumes/work/redis-5.0.8/src/redis-server *:7007 [cluster] 501 43143 1 0 6:18上午 ?? 0:00.03 /Volumes/work/redis-5.0.8/src/redis-server *:7008 [cluster]
但是我们可以看到虽然进程启动了,但是并未加到集群中去:
127.0.0.1:7002> cluster nodes 8891bfe505da42298be048364ed003b83dc52139 127.0.0.1:7005@17005 master - 0 1586211626238 7 connected 0-5460 9d6d78888e579442b209fca95af13b6ece4810b6 127.0.0.1:7004@17004 slave 6494df31d4ed564d80947c9d39369cc7cfb6c0e6 0 1586211626741 4 connected 981ad9769245c140c0bd9ee239472dc6e2cb07eb 127.0.0.1:7006@17006 slave d7a0d77d2f0fa05ccf4a14e379b52044b212607e 0 1586211626036 6 connected d7a0d77d2f0fa05ccf4a14e379b52044b212607e 127.0.0.1:7002@17002 myself,master - 0 1586211625000 2 connected 5461-10922 6494df31d4ed564d80947c9d39369cc7cfb6c0e6 127.0.0.1:7003@17003 master - 0 1586211626540 3 connected 10923-16383 4c7fcd06c55ceec27b5bbc450b99159282e7783e 127.0.0.1:7001@17001 slave 8891bfe505da42298be048364ed003b83dc52139 0 1586211627751 7 connected
执行集群节点并没有返现我们的节点数据,这个时候需要把启动的节点数据增加到集群中去,执行命令:./redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7005:
192:src houjing$ ./redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001 >>> Adding node 127.0.0.1:7007 to cluster 127.0.0.1:7001 >>> Performing Cluster Check (using node 127.0.0.1:7001) M: e83dc175f217148444a07ed367fea54ed6b3e2aa 127.0.0.1:7001 slots:[0-5460] (5461 slots) master 1 additional replica(s) S: 4686809f8673bc918f03fd8642c410c1ca647a39 127.0.0.1:7004 slots: (0 slots) slave replicates a3b2d4619e3ad17ea86f69a05543b12aa722a864 S: 10eed7c7bbbd7e9e427d0ccf7e2d557607d7467f 127.0.0.1:7005 slots: (0 slots) slave replicates de6820c4780a070ac658ee4bdf98c44b46038d81 M: de6820c4780a070ac658ee4bdf98c44b46038d81 127.0.0.1:7003 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 9624c69e40a36dd1d67fbd21cae75753735f3f02 127.0.0.1:7006 slots: (0 slots) slave replicates e83dc175f217148444a07ed367fea54ed6b3e2aa M: a3b2d4619e3ad17ea86f69a05543b12aa722a864 127.0.0.1:7002 slots:[5461-10922] (5462 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. >>> Send CLUSTER MEET to node 127.0.0.1:7007 to make it join the cluster. [OK] New node added correctly. 127.0.0.1:7005> cluster nodes de6820c4780a070ac658ee4bdf98c44b46038d81 127.0.0.1:7003@17003 master - 0 1586212133524 3 connected 10923-16383 e83dc175f217148444a07ed367fea54ed6b3e2aa 127.0.0.1:7001@17001 master - 0 1586212134536 1 connected 0-5460 a3b2d4619e3ad17ea86f69a05543b12aa722a864 127.0.0.1:7002@17002 master - 0 1586212133323 2 connected 5461-10922 4686809f8673bc918f03fd8642c410c1ca647a39 127.0.0.1:7004@17004 slave a3b2d4619e3ad17ea86f69a05543b12aa722a864 0 1586212133000 4 connected a8236394ddd7f210e4df2036bd73968503283cf8 127.0.0.1:7007@17007 master - 0 1586212134333 0 connected 10eed7c7bbbd7e9e427d0ccf7e2d557607d7467f 127.0.0.1:7005@17005 myself,slave de6820c4780a070ac658ee4bdf98c44b46038d81 0 1586212134000 5 connected 9624c69e40a36dd1d67fbd21cae75753735f3f02 127.0.0.1:7006@17006 slave e83dc175f217148444a07ed367fea54ed6b3e2aa 0 1586212134000 6 connected
可以看到7007成功加入到集群节点,但是并未分配slot槽,接下来使用redis-cli命令为7007分配hash槽,找到集群中的任意一个主节点(7001),对其进行重新分片工作。命令: ./redis-cli --cluster reshard 127.0.0.1:7001
192:src houjing$ ./redis-cli --cluster reshard 127.0.0.1:7001 >>> Performing Cluster Check (using node 127.0.0.1:7001) M: e83dc175f217148444a07ed367fea54ed6b3e2aa 127.0.0.1:7001 slots:[0-5460] (5461 slots) master 1 additional replica(s) S: 4686809f8673bc918f03fd8642c410c1ca647a39 127.0.0.1:7004 slots: (0 slots) slave replicates a3b2d4619e3ad17ea86f69a05543b12aa722a864 S: 10eed7c7bbbd7e9e427d0ccf7e2d557607d7467f 127.0.0.1:7005 slots: (0 slots) slave replicates de6820c4780a070ac658ee4bdf98c44b46038d81 M: de6820c4780a070ac658ee4bdf98c44b46038d81 127.0.0.1:7003 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 9624c69e40a36dd1d67fbd21cae75753735f3f02 127.0.0.1:7006 slots: (0 slots) slave replicates e83dc175f217148444a07ed367fea54ed6b3e2aa M: a8236394ddd7f210e4df2036bd73968503283cf8 127.0.0.1:7007 slots: (0 slots) master M: a3b2d4619e3ad17ea86f69a05543b12aa722a864 127.0.0.1:7002 slots:[5461-10922] (5462 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. How many slots do you want to move (from 1 to 16384)? 1000 What is the receiving node ID? a8236394ddd7f210e4df2036bd73968503283cf8 Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1: all
以上就是要从其余三个master上划分1000个slot到7007节点,7007节点的ID为a8236394ddd7f210e4df2036bd73968503283cf8。两种reshard方式如下:
- 一种是all,以将所有节点用作散列槽的源节点,
- 一种是done,这种是你自己选择从哪个节点上拿出来节点分给8007
备注:all是随机的,比如说我们要分出1000个,则3个主节点分别拿出333个,333个,334个节点分别给7007。
此时查看cluster nodes信息如下:
127.0.0.1:7005> cluster nodes de6820c4780a070ac658ee4bdf98c44b46038d81 127.0.0.1:7003@17003 master - 0 1586212646000 3 connected 11256-16383 e83dc175f217148444a07ed367fea54ed6b3e2aa 127.0.0.1:7001@17001 master - 0 1586212645158 1 connected 333-5460 a3b2d4619e3ad17ea86f69a05543b12aa722a864 127.0.0.1:7002@17002 master - 0 1586212646000 2 connected 5795-10922 4686809f8673bc918f03fd8642c410c1ca647a39 127.0.0.1:7004@17004 slave a3b2d4619e3ad17ea86f69a05543b12aa722a864 0 1586212646572 4 connected a8236394ddd7f210e4df2036bd73968503283cf8 127.0.0.1:7007@17007 master - 0 1586212646372 7 connected 0-332 5461-5794 10923-11255 10eed7c7bbbd7e9e427d0ccf7e2d557607d7467f 127.0.0.1:7005@17005 myself,slave de6820c4780a070ac658ee4bdf98c44b46038d81 0 1586212645000 5 connected 9624c69e40a36dd1d67fbd21cae75753735f3f02 127.0.0.1:7006@17006 slave e83dc175f217148444a07ed367fea54ed6b3e2aa 0 1586212645000 6 connected
可以看到7007节点拿到了3段合计1000个slot槽,接下来我们为7007增加从节点7008,依旧是先把7008添加到集群中去:./redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7001:
127.0.0.1:7005> cluster nodes d9daa198ebe389f7c707e6d41c8052e59f29ce0b 127.0.0.1:7008@17008 master - 0 1586212814000 0 connected de6820c4780a070ac658ee4bdf98c44b46038d81 127.0.0.1:7003@17003 master - 0 1586212814970 3 connected 11256-16383 e83dc175f217148444a07ed367fea54ed6b3e2aa 127.0.0.1:7001@17001 master - 0 1586212815000 1 connected 333-5460 a3b2d4619e3ad17ea86f69a05543b12aa722a864 127.0.0.1:7002@17002 master - 0 1586212815000 2 connected 5795-10922 4686809f8673bc918f03fd8642c410c1ca647a39 127.0.0.1:7004@17004 slave a3b2d4619e3ad17ea86f69a05543b12aa722a864 0 1586212814565 4 connected a8236394ddd7f210e4df2036bd73968503283cf8 127.0.0.1:7007@17007 master - 0 1586212815574 7 connected 0-332 5461-5794 10923-11255 10eed7c7bbbd7e9e427d0ccf7e2d557607d7467f 127.0.0.1:7005@17005 myself,slave de6820c4780a070ac658ee4bdf98c44b46038d81 0 1586212815000 5 connected 9624c69e40a36dd1d67fbd21cae75753735f3f02 127.0.0.1:7006@17006 slave e83dc175f217148444a07ed367fea54ed6b3e2aa 0 1586212814565 6 connected
可以看到7008添加到了集群,但是目前还是主节点,并且没有hash槽。接下来需要让其变成从节点。
命令:CLUSTER REPLICATE a8236394ddd7f210e4df2036bd73968503283cf8(这个节点给哪个主节点)
192:src houjing$ ./redis-cli -c -p 7008 127.0.0.1:7008> CLUSTER REPLICATE a8236394ddd7f210e4df2036bd73968503283cf8 OK 127.0.0.1:7008> cluster nodes 4686809f8673bc918f03fd8642c410c1ca647a39 127.0.0.1:7004@17004 slave a3b2d4619e3ad17ea86f69a05543b12aa722a864 0 1586213074000 2 connected a8236394ddd7f210e4df2036bd73968503283cf8 127.0.0.1:7007@17007 master - 0 1586213073000 7 connected 0-332 5461-5794 10923-11255 9624c69e40a36dd1d67fbd21cae75753735f3f02 127.0.0.1:7006@17006 slave e83dc175f217148444a07ed367fea54ed6b3e2aa 0 1586213073000 1 connected de6820c4780a070ac658ee4bdf98c44b46038d81 127.0.0.1:7003@17003 master - 0 1586213074818 3 connected 11256-16383 e83dc175f217148444a07ed367fea54ed6b3e2aa 127.0.0.1:7001@17001 master - 0 1586213074000 1 connected 333-5460 d9daa198ebe389f7c707e6d41c8052e59f29ce0b 127.0.0.1:7008@17008 myself,slave a8236394ddd7f210e4df2036bd73968503283cf8 0 1586213073000 0 connected a3b2d4619e3ad17ea86f69a05543b12aa722a864 127.0.0.1:7002@17002 master - 0 1586213074513 2 connected 5795-10922 10eed7c7bbbd7e9e427d0ccf7e2d557607d7467f 127.0.0.1:7005@17005 slave a8236394ddd7f210e4df2036bd73968503283cf8 0 1586213074513 7 connected
如上所示,查看cluster nodes信息则可直到成功实现Redis集群的水平扩容。
3.7、节点下线
我们现实中存在着水平扩展,那么当服务使用量下降时,也存在着节点下线。比如我们要让刚扩容的7007、7008下线,我们先来删除从节点7008:
命令:./redis-cli --cluster del-node 127.0.0.1:7008 d9daa198ebe389f7c707e6d41c8052e59f29ce0b
192:src houjing$ ./redis-cli --cluster del-node 127.0.0.1:7008 d9daa198ebe389f7c707e6d41c8052e59f29ce0b >>> Removing node d9daa198ebe389f7c707e6d41c8052e59f29ce0b from cluster 127.0.0.1:7008 >>> Sending CLUSTER FORGET messages to the cluster... >>> SHUTDOWN the node. 127.0.0.1:7001> cluster nodes 4686809f8673bc918f03fd8642c410c1ca647a39 127.0.0.1:7004@17004 slave a3b2d4619e3ad17ea86f69a05543b12aa722a864 0 1586213383501 4 connected e83dc175f217148444a07ed367fea54ed6b3e2aa 127.0.0.1:7001@17001 myself,master - 0 1586213383000 1 connected 333-5460 10eed7c7bbbd7e9e427d0ccf7e2d557607d7467f 127.0.0.1:7005@17005 slave a8236394ddd7f210e4df2036bd73968503283cf8 0 1586213383000 7 connected de6820c4780a070ac658ee4bdf98c44b46038d81 127.0.0.1:7003@17003 master - 0 1586213383000 3 connected 11256-16383 9624c69e40a36dd1d67fbd21cae75753735f3f02 127.0.0.1:7006@17006 slave e83dc175f217148444a07ed367fea54ed6b3e2aa 0 1586213384308 6 connected a8236394ddd7f210e4df2036bd73968503283cf8 127.0.0.1:7007@17007 master - 0 1586213383300 7 connected 0-332 5461-5794 10923-11255 a3b2d4619e3ad17ea86f69a05543b12aa722a864 127.0.0.1:7002@17002 master - 0 1586213383000 2 connected 5795-10922
接下来删除主节点7007,命令:./redis-cli --cluster reshard 127.0.0.1:7007
192:src houjing$ ./redis-cli --cluster reshard 127.0.0.1:7007 >>> Performing Cluster Check (using node 127.0.0.1:7007) M: a8236394ddd7f210e4df2036bd73968503283cf8 127.0.0.1:7007 slots:[172-665],[5461-6128],[10923-11588] (1828 slots) master 1 additional replica(s) M: a3b2d4619e3ad17ea86f69a05543b12aa722a864 127.0.0.1:7002 slots:[6542-10922] (4381 slots) master 1 additional replica(s) S: 4686809f8673bc918f03fd8642c410c1ca647a39 127.0.0.1:7004 slots: (0 slots) slave replicates a3b2d4619e3ad17ea86f69a05543b12aa722a864 M: de6820c4780a070ac658ee4bdf98c44b46038d81 127.0.0.1:7003 slots:[12003-16383] (4381 slots) master S: 9624c69e40a36dd1d67fbd21cae75753735f3f02 127.0.0.1:7006 slots: (0 slots) slave replicates e83dc175f217148444a07ed367fea54ed6b3e2aa M: e83dc175f217148444a07ed367fea54ed6b3e2aa 127.0.0.1:7001 slots:[0-171],[666-5460],[6129-6541],[11589-12002] (5794 slots) master 1 additional replica(s) S: 10eed7c7bbbd7e9e427d0ccf7e2d557607d7467f 127.0.0.1:7005 slots: (0 slots) slave replicates a8236394ddd7f210e4df2036bd73968503283cf8 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. How many slots do you want to move (from 1 to 16384)? 1828 What is the receiving node ID? a3b2d4619e3ad17ea86f69a05543b12aa722a864 Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1: a8236394ddd7f210e4df2036bd73968503283cf8 Source node #2: done Ready to move 1828 slots.
可以看到我们把7007节点的1828个slot全部移到了7002上,再次查看cluster nodes信息如下:
127.0.0.1:7001> cluster nodes 4686809f8673bc918f03fd8642c410c1ca647a39 127.0.0.1:7004@17004 slave a3b2d4619e3ad17ea86f69a05543b12aa722a864 0 1586214201506 9 connected e83dc175f217148444a07ed367fea54ed6b3e2aa 127.0.0.1:7001@17001 myself,master - 0 1586214200000 8 connected 0-171 666-5460 6129-6541 11589-12002 10eed7c7bbbd7e9e427d0ccf7e2d557607d7467f 127.0.0.1:7005@17005 slave a3b2d4619e3ad17ea86f69a05543b12aa722a864 0 1586214201000 9 connected de6820c4780a070ac658ee4bdf98c44b46038d81 127.0.0.1:7003@17003 master - 0 1586214200000 3 connected 12003-16383 9624c69e40a36dd1d67fbd21cae75753735f3f02 127.0.0.1:7006@17006 slave e83dc175f217148444a07ed367fea54ed6b3e2aa 0 1586214200000 8 connected a8236394ddd7f210e4df2036bd73968503283cf8 127.0.0.1:7007@17007 master - 0 1586214201707 7 connected a3b2d4619e3ad17ea86f69a05543b12aa722a864 127.0.0.1:7002@17002 master - 0 1586214201000 9 connected 172-665 5461-6128 6542-11588
7007节点还在,但是分配的slot没有了,接下来关闭7007节点,命令:./redis-cli -p 7001 shutdown
127.0.0.1:7001> cluster nodes a8236394ddd7f210e4df2036bd73968503283cf8 127.0.0.1:7007@17007 master - 1586214471239 1586214469000 7 disconnected 4686809f8673bc918f03fd8642c410c1ca647a39 127.0.0.1:7004@17004 slave a3b2d4619e3ad17ea86f69a05543b12aa722a864 0 1586214473159 9 connected e83dc175f217148444a07ed367fea54ed6b3e2aa 127.0.0.1:7001@17001 myself,slave 9624c69e40a36dd1d67fbd21cae75753735f3f02 0 1586214473000 8 connected de6820c4780a070ac658ee4bdf98c44b46038d81 127.0.0.1:7003@17003 master - 0 1586214473000 3 connected 12003-16383 9624c69e40a36dd1d67fbd21cae75753735f3f02 127.0.0.1:7006@17006 master - 0 1586214472653 10 connected 0-171 666-5460 6129-6541 11589-12002 a3b2d4619e3ad17ea86f69a05543b12aa722a864 127.0.0.1:7002@17002 master - 0 1586214474073 9 connected 172-665 5461-6128 6542-11588 10eed7c7bbbd7e9e427d0ccf7e2d557607d7467f 127.0.0.1:7005@17005 slave 9624c69e40a36dd1d67fbd21cae75753735f3f02 0 1586214474175 10 connected
于是实现了7007、7008节点的下线。
3.8、集群模式优缺点
优点:
- 无中心架构;
- 数据按照slot存储分布在多个节点,节点间数据共享,可动态调整数据分布;
- 可扩展性:可线性扩展到1000多个节点,节点可动态添加或删除;
- 高可用性:部分节点不可用时,集群仍可用。通过增加Slave做standby数据副本,能够实现故障自动failover,节点之间通过gossip协议交换状态信息,用投票机制完成Slave到Master的角色提升;
- 降低运维成本,提高系统的扩展性和可用性。
缺点:
- Client实现复杂,驱动要求实现Smart Client,缓存slots mapping信息并及时更新,提高了开发难度,客户端的不成熟影响业务的稳定性。目前仅JedisCluster相对成熟,异常处理部分还不完善,比如常见的“max redirect exception”。
- 节点会因为某些原因发生阻塞(阻塞时间大于clutser-node-timeout),被判断下线,这种failover是没有必要的。
- 数据通过异步复制,不保证数据的强一致性。
- 多个业务使用同一套集群时,无法根据统计区分冷热数据,资源隔离性较差,容易出现相互影响的情况。
- Slave在集群中充当“冷备”,不能缓解读压力,当然可以通过SDK的合理设计来提高Slave资源的利用率。
- Key批量操作限制,如使用mset、mget目前只支持具有相同slot值的Key执行批量操作。对于映射为不同slot值的Key由于Keys不支持跨slot查询,所以执行mset、mget、sunion等操作支持不友好。
- Key事务操作支持有限,只支持多key在同一节点上的事务操作,当多个Key分布于不同的节点上时无法使用事务功能。
- Key作为数据分区的最小粒度,不能将一个很大的键值对象如hash、list等映射到不同的节点。
- 不支持多数据库空间,单机下的redis可以支持到16个数据库,集群模式下只能使用1个数据库空间,即db 0。
- 复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
- 避免产生hot-key,导致主库节点成为系统的短板。
- 避免产生big-key,导致网卡撑爆、慢查询等。
- 重试时间应该大于cluster-node-time时间。
- Redis Cluster不建议使用pipeline和multi-keys操作,减少max redirect产生的场景。
3.9、常见问题
在安装的过程中,可能会出现以下问题。
3.9.1、服务启动成功了但是 telnet IP 端口 不通
如果telnet不通,但是ps -ef|grep redis可以看到服务或者本地客户端可以连接,远程客户端连接不了。这个时候就要修改redis.conf参数了
通常注释bind;关掉受保护模式。
protected-mode no #保护模式 yes改为no #bind 127.0.0.1 #注释或者去掉这个
3.9.2、启动redis时没有反应,查看进程没有相关进程号。
redis.conf文件中有一个logfile标签,可以设置日志文件输出到这个文件中进行排查问题。
#指定了记录日志的文件。 logfile "此处为日志存放路径"
3.9.3、注意以下的情况[ERR] Node 127.0.0.1:7001 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
这个时候需要将每个节点下的这几个文件给删掉(测试情况删掉,实际应用不要删,这是备份文件以及节点信息,按实际的情况进行处理):
appendonly.aof dump.rdb nodes-7001.conf
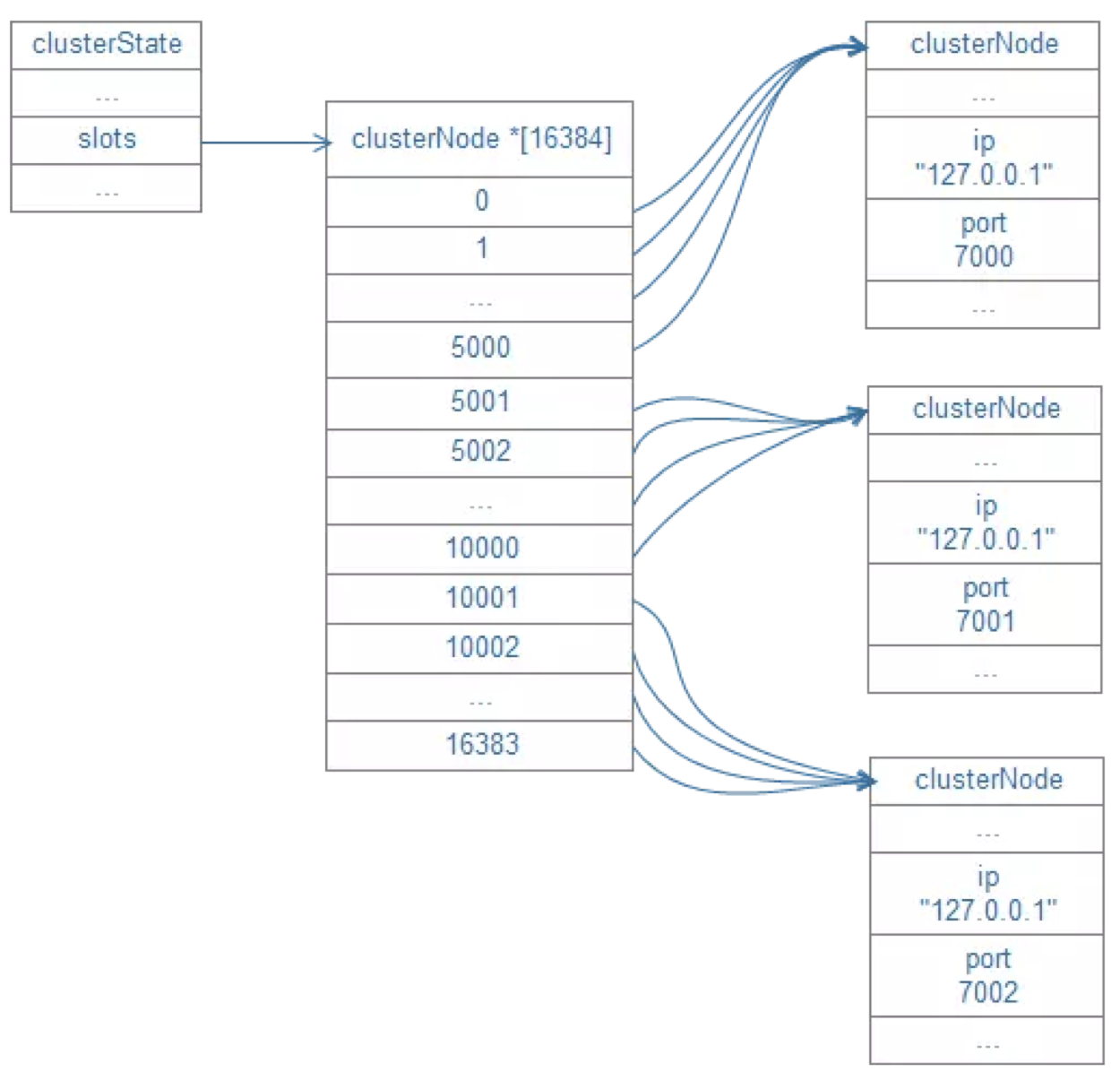
3.10、Slot槽
RedisCluster采用分区规则是键根据哈希函数(CRC16[key]&16383)映射到0-16383槽内,共16384个槽位,每个节点维护部分槽及槽所映射的键值数据。哈希函数: Hash()=CRC16[key]&16383
3.11、Gossip通信
节点之间采用Gossip协议进行通信,Gossip协议就是指节点彼此之间不断通信交换信息,当主从角色变化或新增节点,彼此通过ping/pong进行通信知道全部节点的最新状态并达到集群同步。
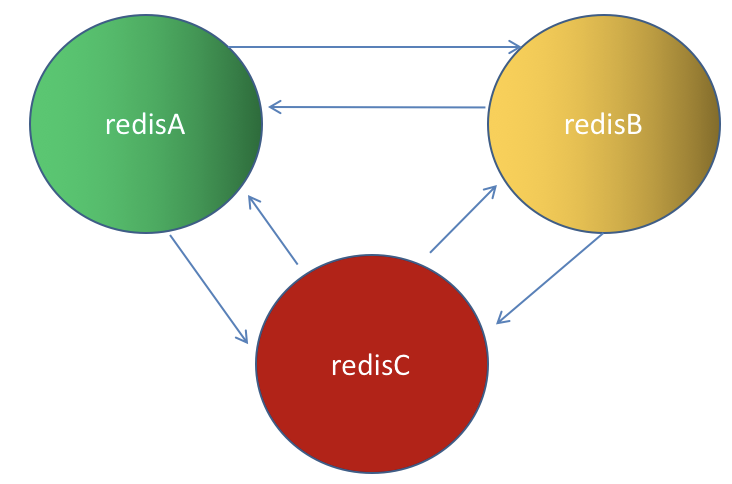
Gossip协议的主要职责就是信息交换,信息交换的载体就是节点之间彼此发送的Gossip消息,常用的Gossip消息有ping消息、pong消息、meet消息、fail消息:
- meet消息:用于通知新节点加入,消息发送者通知接收者加入到当前集群,meet消息通信完后,接收节点会加入到集群中,并进行周期性ping pong交换
- ping消息:集群内交换最频繁的消息,集群内每个节点每秒向其它节点发ping消息,用于检测节点是在在线和状态信息,ping消息发送封装自身节点和其他节点的状态数据;
- pong消息:当接收到ping meet消息时,作为响应消息返回给发送方,用来确认正常通信,pong消息也封闭了自身状态数据;
- fail消息:当节点判定集群内的另一节点下线时,会向集群内广播一个fail消息

具体更为详尽的Gossip协议请参考博文:https://yq.aliyun.com/articles/680237