作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
本次作业是爬取CBO中国票房2010-2019年每年年度票房排名前25的电影,通过爬取电影的名称、类型、总票房(万)、平均票价、均场人次、国家及地区以及上映时间等数据并对其进行数据分析从而得出相应结论。
爬虫的代码如下所示:
1 # -*- coding: utf-8 -*-
2 import requests
3 import time
4 import re
5 import csv
6 import pandas as pd
7 from bs4 import BeautifulSoup
8
9 #设置URL固定部分
10 url='http://www.cbooo.cn/year?year='
11 #设置请求头部信息
12 headers = {
13 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
14 }
15 #循环抓取列表页信息
16 for year in range(2010,2020):
17 if year == 2010:
18 year=str(year)
19 a=(url+year)
20 r=requests.get(url=a,headers=headers)
21 html=r.content
22 else:
23 year=str(year)
24 a=(url+year)
25 r=requests.get(url=a,headers=headers)
26 html2=r.content
27 html = html + html2
28 #每次间隔0.5秒
29 time.sleep(0.5)
30 move=BeautifulSoup(html,'html.parser')
31 #print(move)
32 #提取名称、类型、总票房(万)、平均票价、场均人次及国家及地区
33 result=move.find_all('td')
34 #print(result)
35 #print(len(result))
36 mname=[]
37 title=""
38 index=1
39 year=2009
40 for i in result:
41 i=str(i)
42 title=re.findall(r'</span>(.*?)</p>',i,re.I|re.M)
43 if len(title)>0:
44 mname.append(index)
45 index=index+1
46 mname.append(title[0])
47 else:
48 info=re.findall(r'<td>(.*?)</td>',i,re.I|re.M)
49 mname.append(info[0])
50 #print(len(mname))
51 #print(mname)
52 k=0
53 data=[]
54 while k<2000:
55 year=2010
56 year=year+(k//200)
57 data.append([mname[k],mname[k+1],mname[k+2],mname[k+3],mname[k+4],mname[k+5],mname[k+6],mname[k+7],year,1])
58 k=k+8
59 #print(data)
60 #print(len(data))#一共250条数据
61 #将结果存到CSV文件
62 with open('./data.csv','w') as fout:
63 cin= csv.writer(fout,lineterminator='
')
64 #写入row_1 cin.writerow(["index","name","type","zpf","mantimes","price","area","datatime","year","mark"])
65 for item in data:
66 cin.writerow(item)
67
68 data1 = pd.read_csv('./data.csv',encoding='gbk');
运行上述代码,我们可以发现爬虫的结果已经存为了data.csv文件。
数据分析
首先,把爬取到的数据存为csv文件,并放在本地中,打开csv文件,可以发现数据已经存进来了,如下图所示。
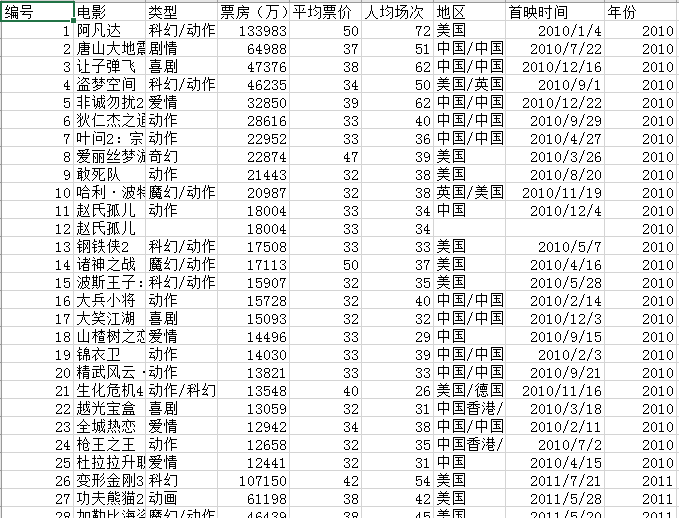
其次,根据所存数据对其进行数据分析,可以得出以下结论。
1.统计不同类型电影的平均票房
如下图所示是统计2010年-2019年不同类型电影的平均票房,由此可知2010年-2019年以来喜剧、奇幻、动作、科幻、剧情这几大类型的电影平均票房最多,最受欢迎。
 |
2.分析十年间每年票房冠军的票房走势
按年份对电影进行排名发现2010年-2019年每年的票房冠军分别是阿凡达(2010年)、变形金刚(2011年)、人再囧途之泰囧(2012年)、西游降魔篇(2013年)、变形金刚4:绝迹重生(2014年)、捉妖记(2015年)、美人鱼(2016年)、战狼2(2017年)、红海行动(2018年)、流浪地球(2019年)。
通过统计我们不难发现,2010年以来,随着人们生活水平的提高,电影的综合票房逐年增加,越来越多的人进入电影院看电影。
下图所示为2019年票房排名,其中流浪地球、复仇者联盟4、疯狂的外星人这三大电影的票房最好,其中流浪地球更是高达465488万票房。
 |
下图所示为2018年票房排名,红海行动、唐人街探案2、我不是药神这三大电影为年度前三,而其余电影的票房较为接近。
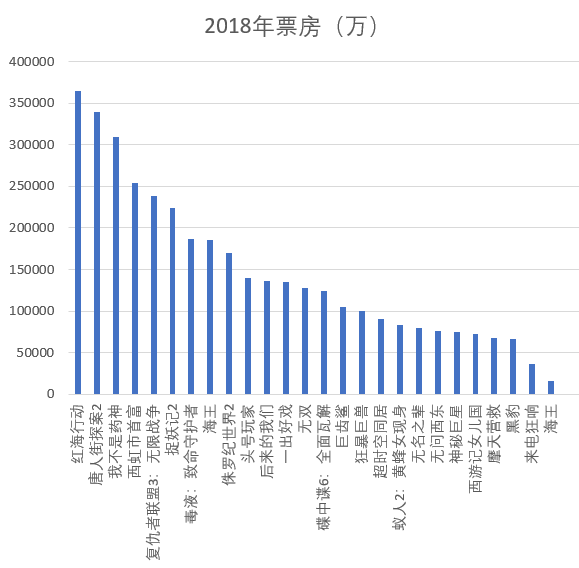 |
下图所示为2017年票房排名,战狼2的票房高达567875万,其余电影票房差距不大。
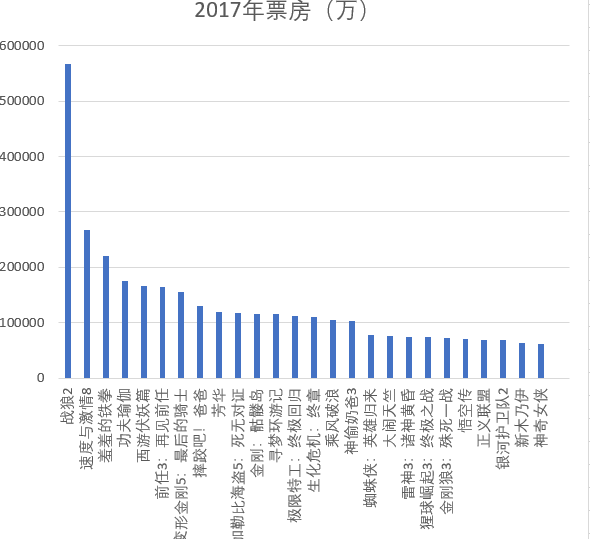
下图所示为2016年票房排名,其中美人鱼、疯狂动物城、魔兽排名前三。

下图所示为2015年票房排名,其中捉妖记、速度与激情7、港囧排名前三。
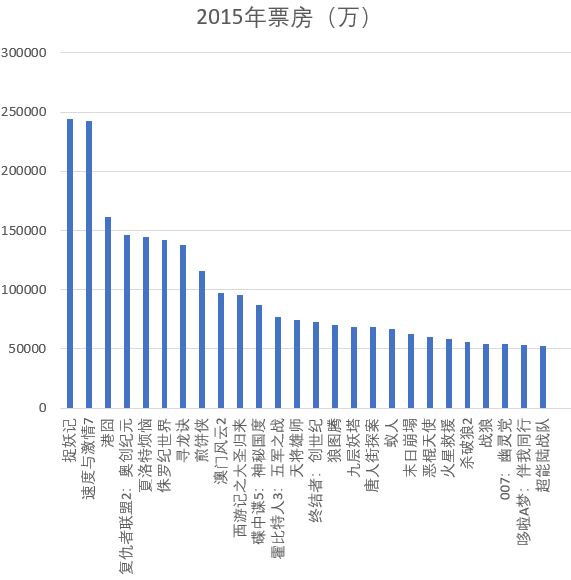
下图所示为2014年票房排名,其中变形金刚4、心花路放、西游记之大闹天宫排名前三。
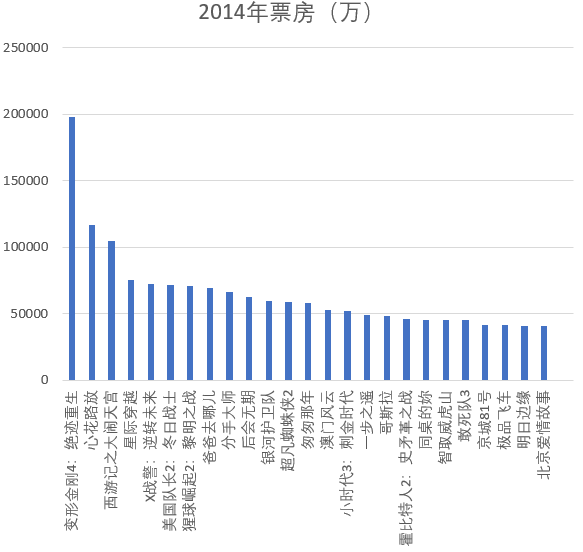
下图所示为2013年票房排名,其中西游降魔篇票房位居首位,其余电影票房相差不大。

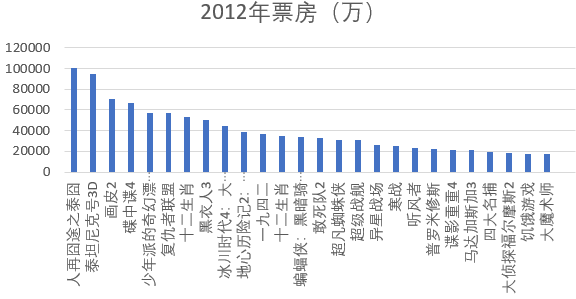
下图所示为2012年票房排名,人再囧途之泰囧、泰坦尼克号、画皮票房较高。
下图所示为2011年票房排名,变形金刚3票房最好。

下图所示为2010年票房排名,阿凡达、唐山大地震、让子弹飞排名最高。

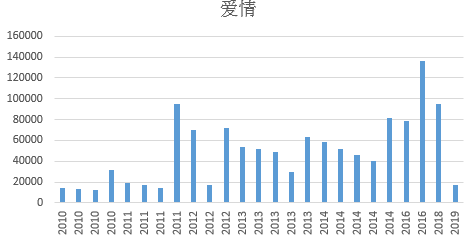
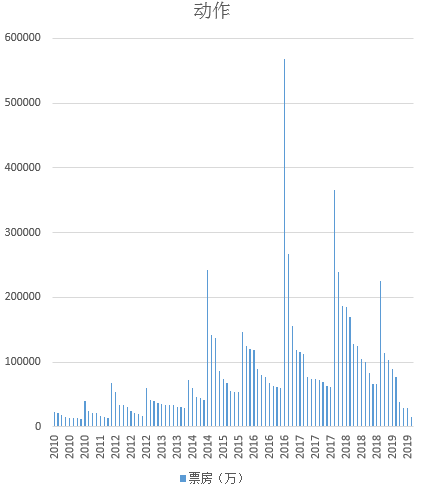
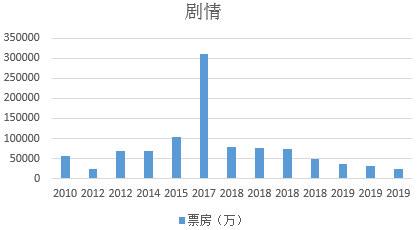
3.分析是否有一种或多种类型的电影在十年间票房震荡非常厉害
首先,我们先分别几大类型的电影进行分析,发现爱情、动作、剧情、科幻、喜剧票房起伏较大