4.2将状态操作应用到Kafka Stream
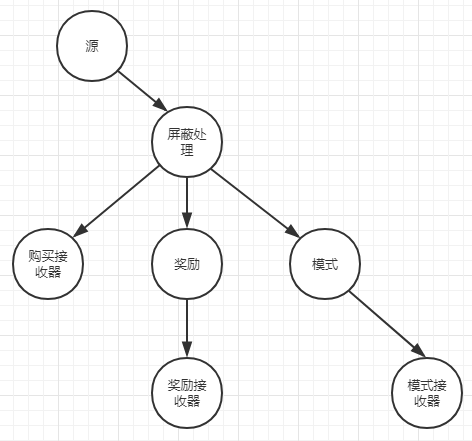
在上图的拓扑中生成了一个购买-交易事件流,拓扑中的一个处理节点根据销售额来计算客户的奖励级分。但在这个处理其中,要做的也仅仅时计算单笔交易的总积分,并转发计算结果。
如果将一些状态添加到处理器中,就可以追踪累积的奖励级分。因此首先要做的就是使用值转换处理器将无状态的奖励处理器转化为有状态的奖励处理器。这样就可以追踪到目前为止所获得的总奖励积分以及两次购买之间的时间间隔,为下游消费者提供更多信息。
4.2.1值转化处理器
最基本的状态函数时KStream.transformValues,下图就展示了KStream.transformValues()方法是如何操作的。

该方法在语义上与 KStream.mapValues()方法相同,但有一些区别。其中一个区别在于 transformvalues方法需要访问一个stateStore实例来完成它的任务。另一个区别在于该方法通过 punctuate()方法安排操作定期执行的能力。我们已在第6章讨论处理器API时再对 punctuate()方法进行详细介绍。
4.2.2 transformValues()详解
KStream<K,VR> transformValues(ValueTransformerSupplier<? super V,? extends VR> valueTransformerSupplier,String stateStoreNames)的作用是将每个输入记录的值转换为输出记录的新值(可能有新类型)。将ValueTransformer(由给定的ValueTransformerSupplier提供)应用于每个输入记录值,并为其计算一个新值。因此,输入记录<K,V>可以转换为输出记录<K:V'>。这是一个有状态的逐记录操作(请参见mapValues(ValueMapper))。此外,通过Punctuator.punctuate(long)可以观察到处理进度,并且可以执行其他周期性操作。
ValueTransformerSupplier接口可以用来创建一个或多个ValueTransformer实例。
ValueTransformer接口用于将值有状态地映射到新值(可能的新类型)。这是一个逐条记录的有状态操作,即对流的每个记录分别调用transform(Object),并且可以访问和修改状态。ValueTransformer中,通过ProcessorContext获得状态。要通过punctuate()触发定期操作,必须注册一个时间表。
4.2.3有状态的客户奖励
最开始的图已经向大家展示了奖励处理器,而奖励处理器属于商户业务中属于奖励程序(rewards)。最初,奖励处理器使用KStream.mapValues()方法传入的Purchase对象映射成RewardAccumulator对象。
RewardAccumulator对象最初仅包含两个字段,即客户ID和交易的购买总额。现在需求发生了一些变化,积分与奖励程序联系在了一起,RewardAccumulator类属性字段定义也变更成如下:
public class RewardAccumulator { private String customerId; //用户id private double purchaseTotal;//购买总额 private int currentRewardPoints;//当前奖励数 }
而在此之前,是一个应用程序从rewards主题中读取数据并计算客户的奖励。但现在我们希望让积分系统通过流式应用程序来维护和计算客户的奖励,还得获取客户当前和上一次购买之间的时间间隔。
当应用程序从rewards主题读取记录时,消费者应用城西只需要检测积分总数是否超过分配奖励的阈值。为实现这个目标可以在RewardAccumulator对象中增加
public class RewardAccumulator { private String customerId; private double purchaseTotal; private int totalRewardPoints; private int currentRewardPoints; private int daysFromLastPurchase;//增加的用于追踪积分总数的字段 }
购买程序的更新规则很简单,客户每消费一美元获得一个积分,交易总额按四舍五入法计算。拓扑的总体结构不会改变,但是奖励处理(rewards-processing)节点将从使用 KStream.mapValues()方法更改为使用 KStream.transformValues()方法。从语义上讲,这两种方法操作方式相同,即仍然是将 Purchase对象映射为RewardAccumulator对象。不同之处在于使用本地状态来执行转换的能力。
具体来说,将采取以下两个主要步骤。
■初始化值转换器。
■使用状态将 Purchase对象映射为 RewardAccumulator对象。
4.2.4初始化值转化器
第一步时在转换器init()方法中设置或创建任何实例变量。
//一个支持放置/获取/删除和范围查询的键值存储。
private KeyValueStore<String, Integer> stateStore; private final String storeName; private ProcessorContext context; //ProcessorContext处理上下文接口 public void init(ProcessorContext context) { this.context = context; //根据名称获取状态存储 stateStore = (KeyValueStore) this.context.getStateStore(storeName); }
在转换器类,将对象类型转化为KeyValueStore类型。
4.2.5使用状态将Purchase对象转化为RewardAccumulator对象
按以下步骤:
①按客户ID检查目前累计积分
②与当前交易的积分求和,并呈现积分总数
③将RewardAccumulator中的奖励积分总数更新为新的积分总数
④按客户ID将新的积分总数保存到本地状态存储中
public RewardAccumulator transform(Purchase value) { //由Purchase对象构造RewardAccumulator对象 RewardAccumulator rewardAccumulator = RewardAccumulator.builder(value).build(); //根据客户ID检索最新积分值 Integer accumulatedSoFar = stateStore.get(rewardAccumulator.getCustomerId()); if (accumulatedSoFar != null) { //如果累积的积分数存在,则将其加到当前总数中。 rewardAccumulator.addRewardPoints(accumulatedSoFar); } //将新的积分存储到stateStore中 stateStore.put(rewardAccumulator.getCustomerId(), rewardAccumulator.getTotalRewardPoints()); //返回新的积分累计值 return rewardAccumulator; }
通过以上代买来实现奖励积分处理器。但在操作之前,你需要考虑一下你正在通过客户ID访问所有的销售信息,如果为给定的客户收集每笔交易信息就意味着该客户的所有交易信息都位于同一个分区。但是,因为进入应用程序的交易信息没有键,所以生产者以轮询的方式将交易信息分配给分区。因此你想要的结果和程序真正执行时就会产生矛盾。

这里存在一个问题(除非你使用主题只有一个分区),因为键没有填充,所以按轮询分配的话就意味着同一个客户的交易信息不一定分配到同一个分区。将相同客户ID的交易信息放到同一个分区很重要,因为需要根据客户ID从状态存储中查找记录。否则。回有相同客户ID客户信息分布在不同分区上,这样查找相同客户的信息时候需要从多个状态存储中查找。
1、对数据重分区
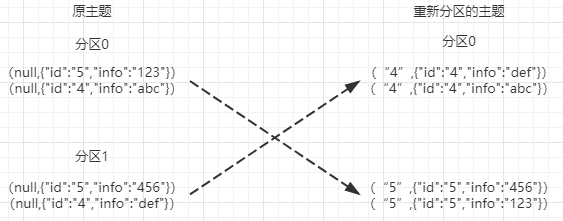
虽然在这个简单的实例中,用一个具体的值替代空间,但是重新分区并不总需要更新键。通过使用流分区器StreamPartitioner,可以使用任何你想到的分区策略,例如不用键而用值或值得一部分来分区。
2、在Kafka Streams中重新分区
在Kafka Streams中使用KStream.through()方法重新分区是一件容易的事。KStream.through()方法创建一个中间主题,当前的Stream实例开始将记录写入这个主题中。调用through()方法返回一个新KStream实例,该实例使用同一个主题作为数据源。通过这种方式,数据就可以被无缝地重新进行分区。
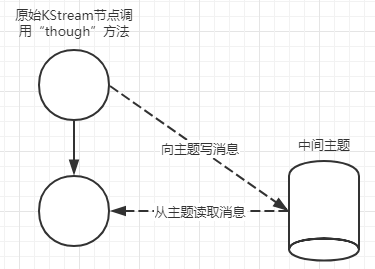
在底层, Kafka Streams创建了一个接收器节点和源节点。接收器节点是调用 KStream实例的子处理器,新 KStream实例使用新的源节点作为它的数据源。你可以使用DSL自己编写相同类型的子拓扑,但是使用 KStream. through()方法更方便。
如果已经修改或更改了键,并且不需要自定义分区策略,那么可以依赖 Kafka Streams的KafkaProducer内部的 DefaultPartitioner来处理分区。但是如果想应用自己的分区方式,那么可以使用流分区器。在下一个例子中就可以这么做。
使用 KStream. through()方法的代码如下所示。在本例, KStream. through()方法接受两个参数,即主题名称和一个Produced实例。 Produced实例分别提供键和值的序列化与反序列化器(Serde)以及一个流分区器( Stream Partitioner)。注意,如果想使用默认键和值的 Serde实例,且不需要自定义分区策略,那么可以使用只有一个主题名参数的 KStream. through方法。
//RewardsStreamPartitioner实现StreamPartitioner接口,该确定记录如何在Kafka主题中的分区之间分配。 RewardsStreamPartitioner streamPartitioner = new RewardsStreamPartitioner(); //通过KStream through方法创建一个新的KStream实例 KStream<String, Purchase> transByCustomerStream = purchaseKStream.through( "customer_transactions", Produced.with(stringSerde, purchaseSerde, streamPartitioner));
3、KStream.through()详解
KStream<K,V> through(String topic,Produced<K,V> produced)
该方法将流具体化为一个主题,并使用Produced实例从该主题中以配置键序列,值序列和StreamPartitioner创建一个新的KStream。
topic-主题名称;
produce-生成主题时要使用的选项,示例代码中采用的是:
Produced<K,V> with(Serde<K> keySerde,Serde<V> valueSerde,StreamPartitioner<? super K,? super V> partitioner)
其中partitioner该函数用于确定记录在主题分区之间的分配方式
public class RewardsStreamPartitioner implements StreamPartitioner<String, Purchase> { @Override public Integer partition(String key, Purchase value, int numPartitions) { return value.getCustomerId().hashCode() % numPartitions; } }
注意上面的代码并没有产生新的键,而是使用值得一个属性(客户ID)来确认同一个客户的正确分区.
4.2.5更新奖励处理器
至此,已经创建出一个新的处理节点,该处理节点将购物对象写入一个按客户ID进行分区的主题。这个新主题也将成为即将更新的奖励处理器的数据源。这样做是为了确保同一个客户的所有信息能被写入同一个分区。因此,对给定客户所有购买信息都使用相同的状态存储。

更新奖励处理器以使用有状态转换:
//使用有状态转换(奖励处理器) KStream<String, RewardAccumulator> statefulRewardAccumulator = transByCustomerStream.transformValues(() -> new PurchaseRewardTransformer(rewardsStateStoreName), rewardsStateStoreName); //将结果写入“rewards”主题(接受处理器) statefulRewardAccumulator.to("rewards", Produced.with(stringSerde, rewardAccumulatorSerde));
4.3使用状态存储查找和记录以前看到的数据
4.3.1数据本地化
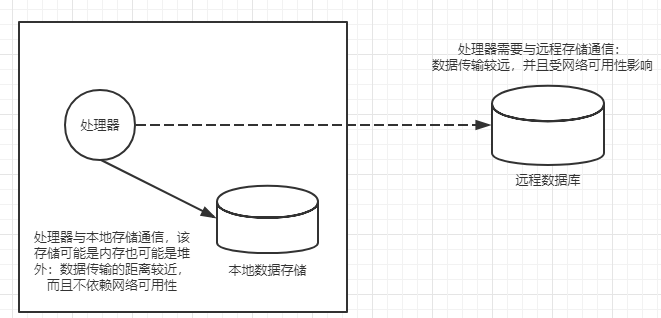
数据本地化对性能至关重要。虽然键查找通常非常快,但是当使用远程存储在大规模处理时带来的延迟将成为瓶颈。
上说明了数据本地化背后的原理。虚线表示从远程数据库检索数据的网络调用。实线描述对位于同一台服务器上的内存数据存储的调用。正如你所看到的,本地数据调用比通过网络向远程数据库的调用更有效。
当通过一个流式应用程序处理数百万或数十亿条记录时,当乘以一个较大的因子时,即使很小的网络延迟也会产生巨大影响。所以数据本地化还意味着存储对每个处理节点都是本地的,并且在进程或线程之间不共享。这样的话,如果一个进程失败了,它就不会对其他流式处理进程或线程产生影响。尽管流式应用程序有时需要状态,但是它应该位于进行处理的本地。应用程序的每个服务器或节点都应该有一个单独的数据存储。
4.3.2故障恢复和容错
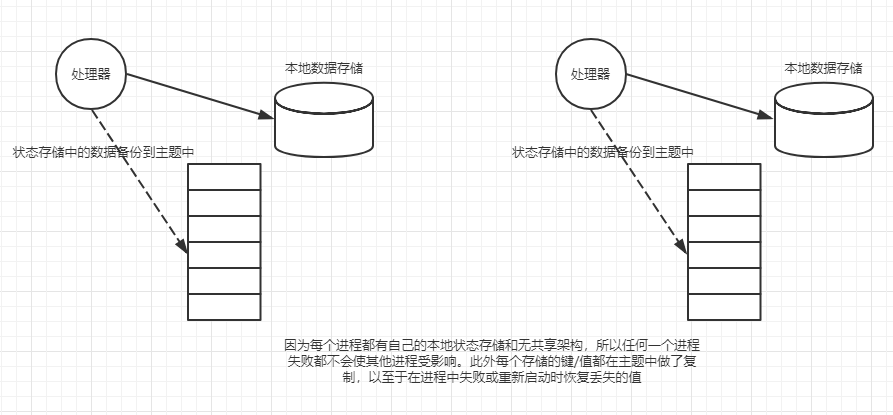
用一个主题备份一个状态存储看起来似乎有些代价,但有几个缓和因素在起作用: KafkaProducer批量发送数据,默认情况下记录会被缓存。仅在缓存刷新时 Kafka Streams才将记录写入存储,因此只保存给定键的最新记录。Kafka Streams提供的状态存储既能满足本地化又能满足容错性的需求,对于已定义的处理器来说它们是本地的,并且不会跨进程或线程访问共享。状态存储也使用主题来做备份和快速恢复。
4.3.3Kafka Stream使用状态存储
添加一个状态存储时一件简单的事情,通过Stores类中的一个静态工厂方法创建一个StoreSupplier实例。有两个用于制定状态存储的附加类,即Meterialized类和StoreBudiler类。使用哪一种类取决于如何向拓扑中添加存储。如果使用高阶DSL,那么通常使用Meterialized类。
//创建StateStore供应者实例 String rewardsStateStoreName = "rewardsPointsStore"; KeyValueBytesStoreSupplier storeSupplier = Stores.inMemoryKeyValueStore(rewardsStateStoreName); //创建StoreBuilder并指定键/值 StoreBuilder<KeyValueStore<String, Integer>> storeBuilder = Stores.keyValueStoreBuilder(storeSupplier, Serdes.String(), Serdes.Integer()); //添加到拓扑 builder.addStateStore(storeBuilder);
在上述代码中,首先,创建一个 storeSupplier对象,它提供一个基于内存的键/值存储,将创建的 StoreSupplier对象作为参数来创建一个 StoreBuilder对象,并指定键的类型为 String,值的类型为 Integer。最后,通过向 StreamsBuilder提供 StoreBuilder将 statestore添加到拓扑,同时通过 StreamBuilder.addStatestore方法将存储添加到应用程序中。因此,现在可以通过上面所创建的状态存储的名字 rewardsStateStoreName来使用处理器中的状态。
4.3.4状态存储容错
所有 StateStoreSupplier类型默认都启用了日志。日志在这里指一个 Kafka主题,该主题作为一个变更日志用来备份存储中的值并提供容错。例如,假设有一台运行 Kafka Streams应用程序的机器宕机了,一旦服务器恢复并重新启动了 Kafka Streams应用程序,该机器上对应实例的状态存储就会恢复到它们原来的内容(在崩溃之前变更日志中最后提交的偏移量)。
当使用带有 disableLogging()方法的 Stores工厂时,可以通过 disableLogging()方法禁用日志功能。但是不要随意禁用日志,因为这样做会从状态存储中移除容错而去除状态存储在崩溃后的恢复能力。
4.3.5配置变更日志主题
用于状态存储的变更日志是可以通过 withLogging(map<String,String> config)方法进行配置的,可以在Map中使用任何主题可用的配置参数。用于状态存储的变更日志的配置在构建一个 Kafka Streams应用程序时很重要。但是请记住,Kafka Streams会创建该主题而并非有我们自己创建。
对 Kafka主题而言,默认的一个日志段的数据保留时间被设置为一星期,数据量没有限制根据你的数据量,这或许是可以接受的,但是你很有可能要调整这些设置。此外,默认清理策略是 delete让我们先看一下如何将变更日志主题配置为保留数据大小为10GB,保留时间为2天,配置代码如下:
Map<String, String> changeLogConfigsMap = new HashMap<>(); changeLogConfigsMap.put("retention.ms","172800000"); changeLogConfigsMap.put("retention.bytes", "10000000000"); storeBuilder.withLoggingEnabled(changeLogConfigsMap); Materialized.as(Stores.inMemoryKeyValueStore("foo")).withLoggingEnabled(changeLogConfigsMap);
4.4连接流以增加洞察力
当流中的事件不独立存在时,流就需要有状态,有时需要的状态或上下文是另一个流。在本节中,将从两个具有相同键的流中获取不同的事件,并将它们组合成新的事件。
学习连接流的最好方式是看一个具体的例子,所以我们将回到 商户交易的应用场景。假设我们新开了经营电子及相关产品(CD、DVD、智能手机等)的商店。为了尝试一种新的方法,我们与一家国营咖啡馆合作,在每家商店里内设一个咖啡馆。这种内设咖啡馆的方式取得了巨大的成功,因此决定启动一个新的项目——通过提供咖啡优惠券来保持电子产品商店的高客流量(期望客流量的增加会带来额外的购买交易),所以我们需要识别出哪些客户购买了咖啡并在电子产品商店进行了交易,那么当这些客户再次交易之后就立即送给他们优惠券。
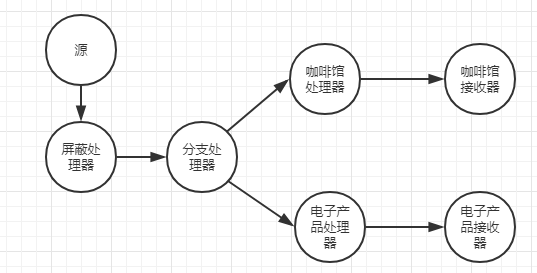
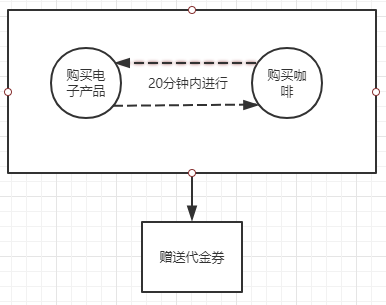
为了确定什么时候给客户赠送代金券,需要将咖啡管的销售记录和电子产品商店的销售记录连接起来。
4.4.1设置数据
//定义匹配记录的谓词,名称不匹配“coffee”或“electronics”将丢弃
Predicate<String, Purchase> isCoffee = (key, purchase) -> purchase.getDepartment().equalsIgnoreCase("coffee"); Predicate<String, Purchase> isElectronics = (key, purchase) -> purchase.getDepartment().equalsIgnoreCase("electronics"); //使用标记的证书来区分相应的数组 int coffee = 0; int electronics = 1; KStream<String, Purchase>[] kstreamByDept = purchaseKStream.branch(isCoffee, isElectronics); kstreamByDept[coffee].to( "coffee", Produced.with(stringSerde, purchaseSerde)); kstreamByDept[coffee].print(Printed.<String, Purchase>toSysOut().withLabel( "coffee")); kstreamByDept[electronics].to("electronics", Produced.with(stringSerde, purchaseSerde)); kstreamByDept[electronics].print(Printed.<String, Purchase>toSysOut().withLabel("electronics"));
KStream<K,V>[] branch(Predicate<? super K,? super V>... predicates)详解:
branch()方法通过基于提供的谓词(做什么/是什么)在原始流中分支记录,从而从此流创建KStream数组。根据提供的谓词评估每个记录并按顺序评估谓词,分支发生在第一个匹配项上:将原始流中的记录分配给第一个谓词的对应结果流,该结果谓词为true,并且仅分配给该流。如果没有任何谓词评估为true,则将删除一条记录。这是无状态逐记录操作。例如案例中如果该记录名称匹配不上coffee或electronics则将该记录丢弃。
上述的代码已经将流进行分支,但是传入的Kafka Streams应用程序的购买记录没有键,因此还要增加一个处理器来生成客户ID的键,从而形成(订单号+客户ID)来保证每一条购买记录都是独一无二的。
4.4.2生成包含客户ID的键来执行连接
为了商城键,从六种的购买数据中选取客户ID,要做到这一点,就需要更新原来的KStream实例,并在该节点和分支节点之间新政另外一个处理器。
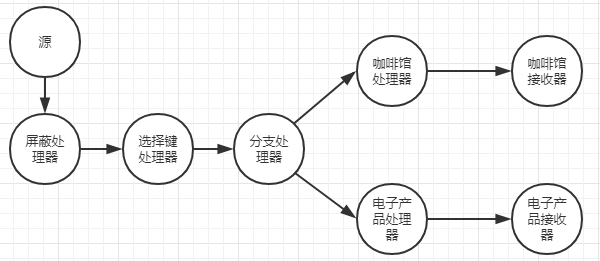
KStream<String, Purchase>[] branchesStream = transactionStream.selectKey((k,v)-> v.getCustomerId()).branch(coffeePurchase, electronicPurchase);
KStream<KR,V> selectKey(KeyValueMapper<? super K,? super V,? extends KR> mapper)
selectKey()方法为每个输入记录设置一个新密钥(可能为新类型),提供的 KeyValueMapper 将应用于每个输入记录并为此计算一个新密钥。
在 Kafka Streams中,无论何时调用一个可导致产生一个新键( selectKey map或 transform)的方法,内部一个布尔类型的标识位就会被设置为true,这就表明新的 KStream实例需要重新分区。如果设置了这个布尔标识位,那么在执行join、 reduce或者聚合操作时,将会自动进行重新分区。在本例,对 transactionStreamelectKey执行了一个()操作,那么产生的 KStream实例就被标记为重新分区。此外,立即执行一个分支操作,那么branch()方法调用产生的每个KStream实例也被标记为重新分区。

1、连接购买记录
public class PurchaseJoiner implements ValueJoiner<Purchase, Purchase, CorrelatedPurchase> { @Override public CorrelatedPurchase apply(Purchase purchase, Purchase otherPurchase) { CorrelatedPurchase.Builder builder = CorrelatedPurchase.newBuilder(); Date purchaseDate = purchase != null ? purchase.getPurchaseDate() : null; Double price = purchase != null ? purchase.getPrice() : 0.0; String itemPurchased = purchase != null ? purchase.getItemPurchased() : null; Date otherPurchaseDate = otherPurchase != null ? otherPurchase.getPurchaseDate() : null; Double otherPrice = otherPurchase != null ? otherPurchase.getPrice() : 0.0; String otherItemPurchased = otherPurchase != null ? otherPurchase.getItemPurchased() : null; List<String> purchasedItems = new ArrayList<>(); if (itemPurchased != null) { purchasedItems.add(itemPurchased); } if (otherItemPurchased != null) { purchasedItems.add(otherItemPurchased); } String customerId = purchase != null ? purchase.getCustomerId() : null; String otherCustomerId = otherPurchase != null ? otherPurchase.getCustomerId() : null; builder.withCustomerId(customerId != null ? customerId : otherCustomerId) .withFirstPurchaseDate(purchaseDate) .withSecondPurchaseDate(otherPurchaseDate) .withItemsPurchased(purchasedItems) .withTotalAmount(price + otherPrice); return builder.build(); } }
ValueJoiner<V1,V2,VR>接口用于将两个值连接到任意类型的新值中,其中apply()返回由 value1 和 value2 组成的已连接值。
VR apply(V1 value1,V2 value2)
value1-联接的第一个值;
value-联接的第二个值;
2、实现连接
//根据之前设置的0/1来区分提取分支流 KStream<String, Purchase> coffeeStream = branchesStream[COFFEE_PURCHASE]; KStream<String, Purchase> electronicsStream = branchesStream[ELECTRONICS_PURCHASE]; //执行拦截操作的ValueJoiner实例,PurchaseJoiner实现ValueJoiner 接口,该接口用于将两个值连接到任意类型的新值中。 ValueJoiner<Purchase, Purchase, CorrelatedPurchase> purchaseJoiner = new PurchaseJoiner();
//设置时间,指定如果同一键的记录的时间戳在指定时间内,即要记录的时间戳早于或晚于主要记录的时间戳,则该记录可以联接。 JoinWindows twentyMinuteWindow = JoinWindows.of(60 * 1000 * 20); //调用join方法,触发coffeeStream和electronicesStream自动重新分区 KStream<String, CorrelatedPurchase> joinedKStream = coffeeStream.join(electronicsStream,
purchaseJoiner, twentyMinuteWindow, //构造连接 Joined.with(stringSerde, purchaseSerde, purchaseSerde)); //将结果达应到控制台 joinedKStream.print(Printed.<String, CorrelatedPurchase>toSysOut().withLabel("joined KStream"));
KStream.join()方法详解:
KStream<K,VR> join(KStream<K,VO> otherStream,ValueJoiner<? super V,? super VO,? extends VR> joiner,JoinWindows windows,Joined<K,V,VO> joined)
ortherStream-要与此流连接的KStream;
joiner-一个ValueJoiner,它为一对匹配记录计算联接结果;
windows-JoinWindows的规范;
joined-一个Joined实例,该实例定义要用于序列化/反序列化Joined流的输入和输出的Serdes;
向 KStream.join方法提供了4个参数,各参数说明如下:
■electronicsstream要连接的电子产品购买流。
■purchaseJoiner ValueJoiner<v1,v2,r>接口的一个实现, ValueJoiner
接收两个值(不一定是相同类型) ValueJoiner. apply方法执行用于特定实现的逻辑并返回一个R类型(可能是一个全新的类型)的对象(有可能是新创建的对象)本示例中, purchaseJoiner将增加一些从两个 Purchase对象中获取的相关信息,并返回一个 CorrelatedPurchase对象。
■ twentyMinuteWindow个 Joinwindows实例。 Joinwindows.of方法指定连接的两个值之间的最大时间差。本示例中,时间戳必须在彼此20分钟以内。
■ 一个 Joined实例提供执行连接操作的可选参数。本示例中。提供流的键和值对应的 Serde,以及第二个流的值对应的 Serde。仅提供键的 Serde,因为连接记录时两个记录的键必须是相同类型。
【注意:连接操作时序列化与反序列化器( Serde)是必需的,因为连接操作的参与者物化在窗口状态存储中。本示例中,只提供了键的 Serde,因为连接操作的两边的键必须是相同类型】
本示例仅指定购买事件要在彼此20分钟以内,但是没有要求顺序。只要时间戳在彼此20分钟以内,连接操作就会发生。
两个额外的 JoinWindows()方法可供使用,可以使用它们来指定事件的顺序。
■ JoinWindows. after streamA.join(streamB,......,twentyMinuteWindow.after(5000),......),这句指定了 streamB记的时间戳最多比 streamA记录的时间戳滞后5秒。窗口的起始时间边界不变。
■ JoinWindows. before-streamA. join(stream,......,twentyMinuteWindow. before(500),......),这句指定了 streamB记录的时间戳最多比 streamA记录的时间戳提早5秒。窗口的结束时间边界不变。
before()和 after()方法的时间差均以毫秒表示。用于连接的时间间隔是滑动窗口的一个例子,在下章将详细介绍窗口操作。
【注意:在代码清单4-13中,依赖于交易的实际时间戳,而不是Kafka设置的时间戳。为了使用交易自带的时间戳,通过设置 StreamsConfig. DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG,指定自定义的时间戳提取器 TransactionTimestampExtractor. class】
现在已经构建了一个连接流:在购买咖啡后20分钟内购买电子产品的客户将获得一张免费咖啡券。
【注意】本内容选自《Kafka Stream实战》,本人仅对其中未讲解清楚的代码进行解读注释工作,不可私自转载!