朴素贝叶斯的“朴素”,并不是简单的意思,而是指样本的特征之间是相互独立的。在所有的机器学习分类算法中, 朴素贝叶斯和其他绝大部分分类算法都不同,其他分类算法基本都是判别方法,即直接学习出特征输出Y和特征向 量X之间的关系,要么是决策函数Y=f(X),要么是条件分布P(Y|X),但是朴素贝叶斯却是生成方法,也就是直接找 出特征输出Y和特征向量X之间的联合分布P(X,Y),然后用P(Y|X)=P(X,Y)/P(X)得出。
朴素贝叶斯的优点在于:1,有稳定的分类效率,2,对小规模数据表现很好,能处理多分类任务,适合增量式训 练,尤其是数据量超出内存时,可以一批一批的去增量训练。3,对缺失数据不太敏感,算法比较简单,常用于文 本分类。
但朴素贝叶斯的缺点是:1,朴素贝叶斯算法有一个重要的使用前提:样本的特征属性之间是相互独立的,这使得 朴素贝叶斯算法在满足这一条件的数据集上效果非常好,而不满足独立性条件的数据集上,效果欠佳。理论上,朴 素贝叶斯模型与其他分类方法相比,有最小的误差率,但是这一结果仅限于满足独立性条件的数据集上。在实际应 用中,属性之间不太可能完全独立,特别是在特征属性个数非常多,且属性之间相关性较大时,朴素贝叶斯分类效 果不太好。2,需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候 会由于假设的先验模型的原因导致预测效果不佳。3,由于通过先验和数据来决定后验的概率从而决定分类,所以 分类决策存在一定的错误率。
1.准备数据集
-------------------------------------输---------出-------------------------------
class Num: 4, class: [0, 1, 2, 3]
--------------------------------------------完------------------------------------
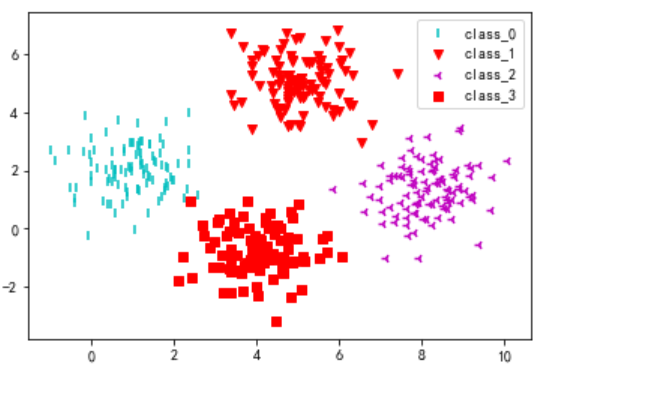
上面从txt文件中加载了数据集,可以看出,该数据集含有400个样本,被平均分成4个不同类别(0,1,2,3)。下面将 这不同类别的数据集绘制到散点图中,以观察每个类别的大概聚集位置。
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
# 准备数据集 data_path='./010-data_multivar.csv'
df=pd.read_csv(data_path,header=None)
# print(df.head()) # print(df.info()) # 查看数据信息,确保没有错误
dataset_X,dataset_y=df.iloc[:,:-1],df.iloc[:,-1] # 拆分为X(所有行,除最后一列)和Y(所有行,最后一 列)
# print('-'*100)
dataset_X=dataset_X.values
dataset_y=dataset_y.values
# print(dataset_X.shape) # (400, 2)
# print(dataset_y.shape) # (400,)
classes=list(set(dataset_y))
print('class Num: {}, class: {}'.format(len(classes), classes)) # 上面检查加载没有问题,一共有四个不同类别,类别名称为:0,1,2,3

2.数据可视化
# 数据集可视化
def visual_2D_dataset(dataset_X,dataset_y):
'''将二维数据集dataset_X和对应的类别dataset_y显示在散点图中'''
assert dataset_X.shape[1]==2,'only support dataset with 2 features'
plt.figure()
classes=list(set(dataset_y))
markers=['.',',','o','v','^','<','>','1','2','3','4','8'
,'s','p','*','h','H','+','x','D','d','|']
colors=['b','c','g','k','m','w','r','y']
for class_id in classes:
one_class=np.array([feature for (feature,label) in
zip(dataset_X,dataset_y) if label==class_id])
plt.scatter(one_class[:,0],one_class[:,1],marker=np.random.choice(markers,1)[0],
c=np.random.choice(colors,1)[0],label='class_'+str(class_id))
plt.legend()
visual_2D_dataset(dataset_X,dataset_y)
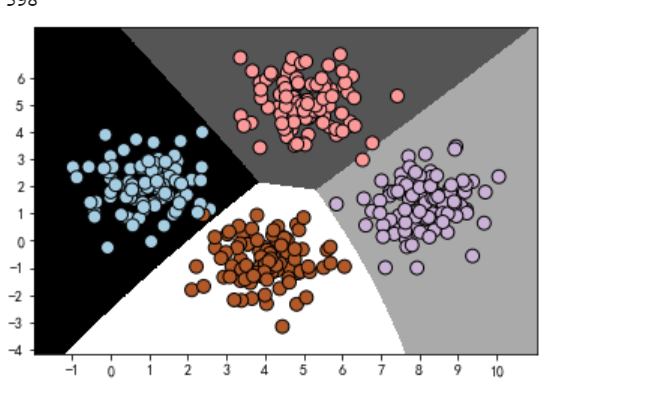
3.构建高斯分布贝叶斯
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
gaussian= GaussianNB()
#预测
gaussian.fit(dataset_X,dataset_y)
y_pre_gauss = gaussian.predict(dataset_X)
# print(y_pre_gauss)
#判断预测结果和真实值的匹配数量
correct_count= (dataset_y == y_pre_gauss).sum()
print(correct_count)
#调用绘图函数
plot_classifier(gaussian,dataset_X,dataset_y)
# plot_classifier(gaussian,dataset_X,y_pre_gauss)
4.多项式朴素贝叶斯
from sklearn.naive_bayes import MultinomialNB
#范围缩放
from sklearn.preprocessing import MinMaxScaler
scalar = MinMaxScaler(feature_range=(10,20))
dataset_X1 = scalar.fit_transform(dataset_X)
# print(dataset_X)
#要求所有的特征必须是非负数,负责无法训练
mul_nb=MultinomialNB()
mul_nb.fit(dataset_X1,dataset_y)
# print(np.c_[dataset_X,dataset_y])
# print(np.r_[dataset_X,dataset_y.reshape(-1,2)])
#row 列向合并,col 列
y_pre = mul_nb.predict([[18.79528986,13.46307385]])
print(y_pre)
#np.c_[]行合并 np.r_[] 列合并
plot_classifier(mul_nb,dataset_X1,dataset_y)
4.伯努利贝叶斯
from sklearn.naive_bayes import BernoulliNB
ber_nb = BernoulliNB()
ber_nb.fit(dataset_X,dataset_y)
y_pre = ber_nb.predict(dataset_X)
# print(y_pre)
plot_classifier(ber_nb,dataset_X,dataset_y)
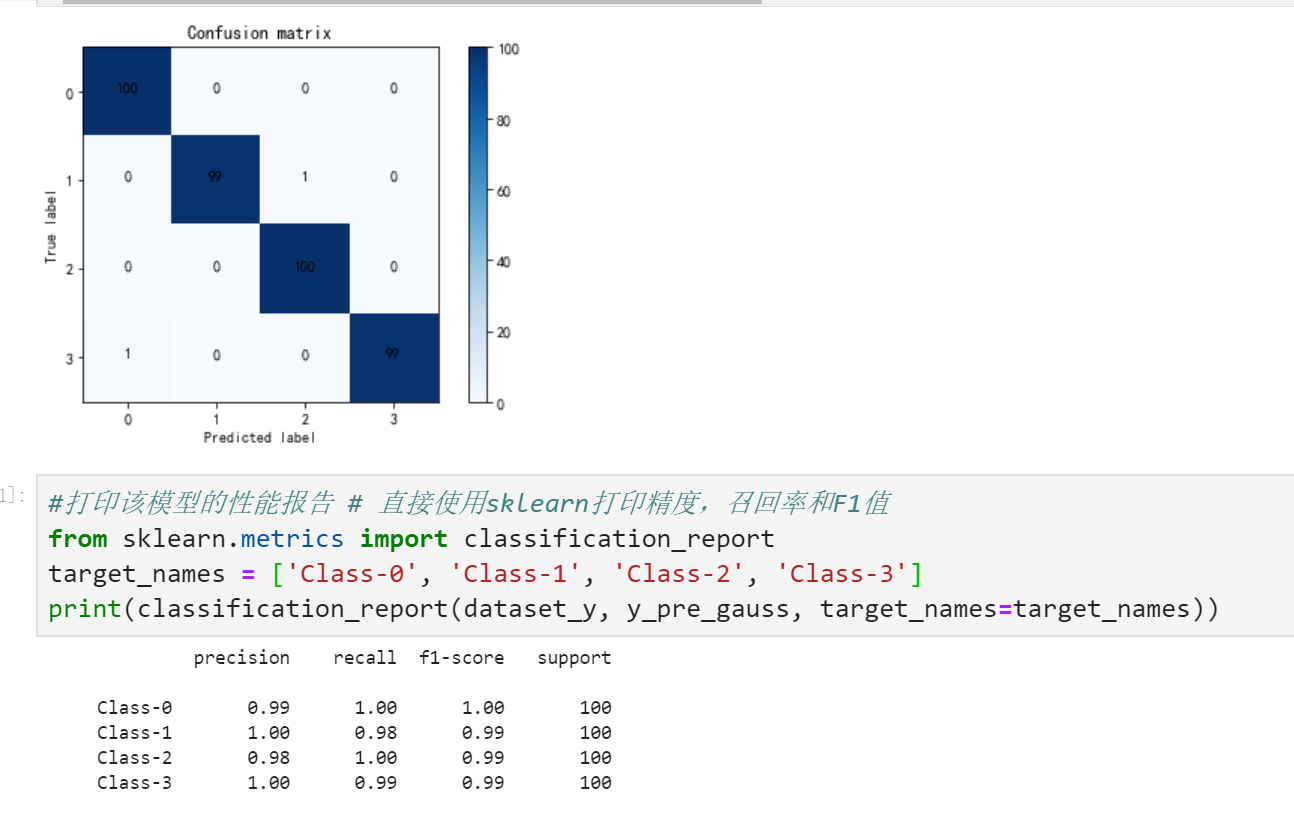
5.打印混淆矩阵
# 使用sklearn 模块计算混淆矩阵
from sklearn.metrics import confusion_matrix
print(dataset_y.shape)
print(y_pre_gauss.shape)
confusion_mat = confusion_matrix(dataset_y, y_pre_gauss)
# print(confusion_mat) #看看混淆矩阵长啥样
6.绘制混合矩阵的图形
from matplotlib import pyplot as plt
%matplotlib inline
import numpy as np # 可视化混淆矩阵
import itertools
def plot_confusion_matrix(confusion_mat):
'''将混淆矩阵画图并显示出来'''
plt.imshow(confusion_mat, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Confusion matrix')
plt.colorbar()
tick_marks = np.arange(confusion_mat.shape[0])
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
thresh = confusion_mat.max()
for i, j in itertools.product(range(confusion_mat.shape[0]), range(confusion_mat.shape[1])): plt.text(j, i, confusion_mat[i, j], horizontalalignment="center", color="white" if confusion_mat[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
plot_confusion_matrix(confusion_mat)