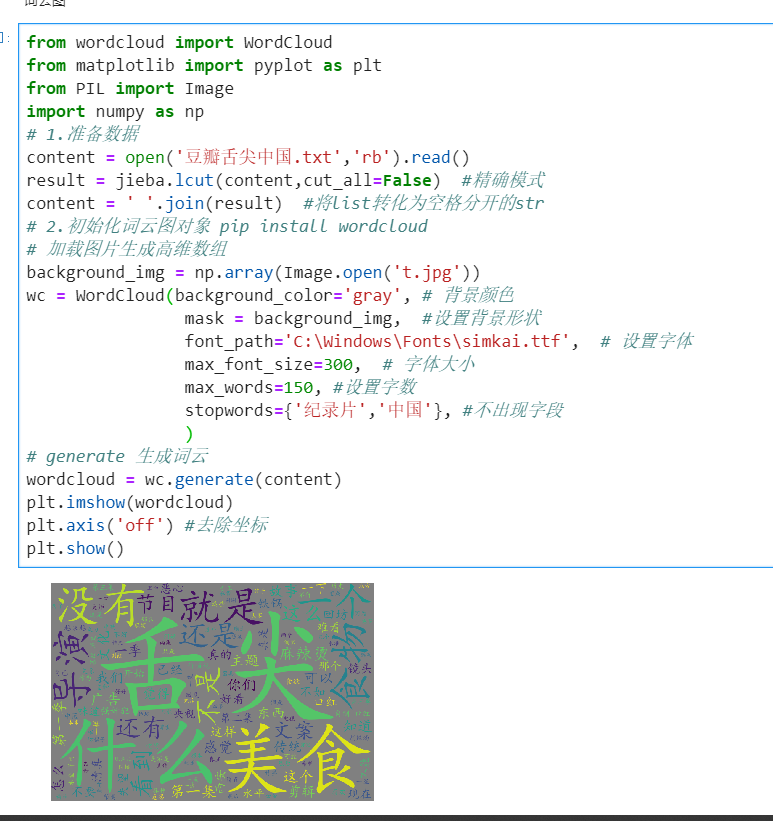
from wordcloud import WordCloud
from matplotlib import pyplot as plt
from PIL import Image
import numpy as np
# 1.准备数据
content = open('豆瓣舌尖中国.txt','rb').read()
result = jieba.lcut(content,cut_all=False) #精确模式
content = ' '.join(result) #将list转化为空格分开的str
# 2.初始化词云图对象 pip install wordcloud
# 加载图片生成高维数组
background_img = np.array(Image.open('t.jpg'))
wc = WordCloud(background_color='gray', # 背景颜色
mask = background_img, #设置背景形状
font_path='C:WindowsFontssimkai.ttf', # 设置字体
max_font_size=300, # 字体大小
max_words=150, #设置字数
stopwords={'纪录片','中国'}, #不出现字段
)
# generate 生成词云
wordcloud = wc.generate(content)
plt.imshow(wordcloud)
plt.axis('off') #去除坐标
plt.show()