1、为什么需要倒排索引
倒排索引,也是索引。
索引,初衷都是为了快速检索到你要的数据。
每种数据库都有自己要解决的问题(或者说擅长的领域),对应的就有自己的数据结构,而不同的使用场景和数据结构,需要用不同的索引,才能起到最大化加快查询的目的。
对 Mysql 来说,是 B+ 树,对 Elasticsearch/Lucene 来说,是倒排索引。
Elasticsearch 是建立在全文搜索引擎库 Lucene 基础上的搜索引擎,它隐藏了 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API,不过掩盖不了它底层也是 Lucene 的事实。
Elasticsearch 的倒排索引,其实就是 Lucene 的倒排索引。
2、倒排索引内部结构
首先,在数据生成的时候,比如爬虫爬到一篇文章,这时我们需要对这篇文章进行分析,将文本拆解成一个个单词。
这个过程很复杂,比如 “生存还是死亡”,你要如何让分词器自动将它分解为 “生存”、“还是”、“死亡”三个词语,然后把“还是”这个无意义的词语干掉。这里不展开,具体涉及到分词相关知识,后续我会单独写一系列分词相关的文章。
接着,把这两个词语以及它对应的文档id存下来:
word documentId
生存 1
死亡 1
接着爬虫继续爬,又爬到一个含有“生存”的文档,于是索引变成:
word documentId
生存 1,2
死亡 1
下次搜索 “生存”,就会返回文档ID是 1、2两份文档。
基本原理是这样的,但是离实际情况还差的很远。
想想看,你有上百万 或 上亿 的文档,分词后的 word 何其之多,要查找一个词你要全局遍历,先不说是否可以遍历完毕,光内存就放不下这么多东西。
于是有了排序,我们需要对单词进行排序,像 B+ 树一样,可以在页里实现二分查找。
光排序还不行,你单词都放在磁盘呢,磁盘 IO 慢的不得了,所以 Mysql 特意把索引缓存到了内存。
还是想我所说的问题一样,那么多词都放到内存肯定会爆炸的。
所以,elasticsearch 其实就是 Lucene 底层存储如下图所示:


我们知道倒排索引是针对 per field 的,一个字段有一个自己的倒排索引。
Term Dictionary
为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库的方式类似啊,为什么说查询更快呢?
Term Index
这样我们可以用二分查找的方式,比全遍历更快地找出目标的 term。这个就是 term dictionary。有了 term dictionary 之后,可以用 logN 次磁盘查找得到目标。但是磁盘的随机读操作仍然是非常昂贵的(一次 random access 大概需要 10ms 的时间)。所以尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个 term dictionary 本身又太大了,无法完整地放到内存里。于是就有了 term index。term index 有点像一本字典的大的章节表。
Lucene 的倒排索,增加了最左边的一层「字典树」term index,它不存储所有的单词,只存储单词前缀,通过字典树找可以很快速的定位到 term dictionary 的某个 offset,也就是单词的大概位置,然后再在块里二分查找,找到对应的单词,再找到单词对应的文档列表。
问题:为什么 Elasticsearch/Lucene 检索可以比 MySQL 快?
Mysql 只有 term dictionary 这一层,是以 B+树 的方式存储在磁盘上的。检索一个term需要若干次的 random access 的磁盘操作。而 Lucene 在 term dictionary 的基础上添加了 term index 来加速检索,term index 以树的形式缓存在内存中。从 term index 查到对应的 term dictionary 的 block 位置之后,再去磁盘上找 term,大大减少了磁盘的 random access 次数。
当然,内存寸土寸金,能省则省,所以 term index 在内存中是以 FST(Finite State Transducers)对它进一步压缩来存储的。
值得汇总的精华:
1. term index 在内存中是以 FST 压缩存储的
2. term dictionary 在磁盘上是以 分 block 的方式存储的,一个 block 内部利用公共前缀压缩,例如都是 Ab 开头的单词就可以把 Ab 省去。这样 term dictionary 可以更节约磁盘空间
3. Posting List 采用 增量编码压缩,将大数变小数,按字节按需存储;且为了更好的求交集,采用动态 bitset 按位交集 和 skiplist 求交优化性能。
3、FST
lucene从4开始大量使用的数据结构是FST(Finite State Transducer)
FST有两个优点:
1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间。使 Term Index 小到可以放进内存,不过相对的也会占用更多的cpu资源。
2)查询速度快。O(len(str))的查询时间复杂度。
下面简单描述下FST的构造过程(工具演示:http://examples.mikemccandless.com/fst.py?terms=&cmd=Build+it%21)
我们对“cat”、 “deep”、 “do”、 “dog” 、“dogs”这5个单词进行插入构建FST(注:必须已排序)
1)插入“cat”
插入cat,每个字母形成一条边,其中t边指向终点。

2)插入“deep”
与前一个单词“cat”进行最大前缀匹配,发现没有匹配则直接插入,P边指向终点。

3)插入“do”
与前一个单词“deep”进行最大前缀匹配,发现是d,则在d边后增加新边o,o边指向终点。

4)插入“dog”
与前一个单词“do”进行最大前缀匹配,发现是do,则在o边后增加新边g,g边指向终点。

5)插入“dogs”
与前一个单词“dog”进行最大前缀匹配,发现是dog,则在g后增加新边s,s边指向终点。

最终我们得到了如上一个有向无环图。利用该结构可以很方便的进行查询,如给定一个term “dog”,我们可以通过上述结构很方便的查询存不存在,甚至我们在构建过程中可以将单词与某一数字、单词进行关联,从而实现key-value的映射。
假设给定真实的带有权重的词插入:mop/0、moth/1、pop/2、star/3、stop/4、top/5,结果如下所示:
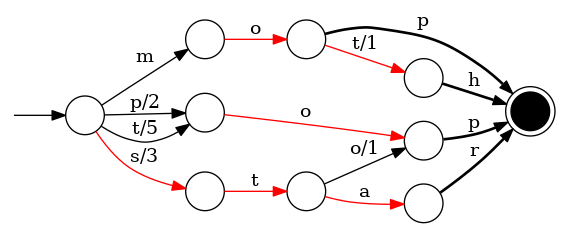
上面的字母/数字表示状态变化和权重,将单词分成单个字母通过 ⭕️ 和 –> 表示出来,0 权重不显示。如果 ⭕️ 后面出现分支,就标记权重,最后整条路径上的权重加起来就是这个单词对应的序号。FST 以字节的方式存储所有的 term,这种压缩方式可以有效的缩减存储空间,使得 term index 足以放进内存,但这种方式也会导致查找时需要更多的CPU资源。
4、Posting List
原生的 Posting List 有两个痛点:
- 如何压缩以节省磁盘空间
- 如何快速求取交并集
4.1、压缩
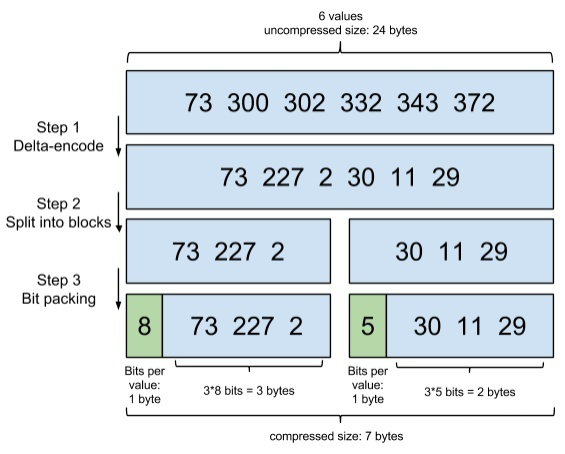
我们来简化下 Lucene 要面对的问题,假设有这样一个数组:
[73, 300, 302, 332, 343, 372]
如何把它进行尽可能的压缩?
Lucene 里,数据是按 Segment 存储的,每个 Segment 最多存 65536 个文档 ID, 所以文档 ID 的范围,从 0 到 2^16-1,所以如果不进行任何处理,那么每个元素都会占用 2 bytes ,对应上面的数组,就是 6 * 2 = 12 bytes。
这里要有一个思考:为什么每个块要以 65536 为界限呢?
因为它 = 2^16-1,正好是用 2 个字节能表示的最大数,一个 short 的存储单位。
怎么压缩呢?压缩的原则是什么?
压缩,就是尽可能降低每个数据占用的空间,同时又能让信息不失真,能够还原回来。
Setp1:Delta-encode(增量编码)
我们只记录元素与元素之间的增量,于是数组变成了:
[73, 227, 2, 30, 11, 29]
Step2:Split into blocks(分割成块)
Lucene里每个块是 256 个文档 ID,这样可以保证每个块,增量编码后,每个元素都不会超过 256(1 byte).
为了方便演示,我们假设每个块是 3 个文档 ID:
[73, 227, 2], [30, 11, 29]
Step3:Bit packing(按需分配空间)
对于第一个块,[73, 227, 2],最大元素是227,需要 8 bits,好,那我给你这个块的每个元素,都分配 8 bits的空间。
但是对于第二个块,[30, 11, 29],最大的元素才30,只需要 5 bits,那我就给你每个元素,只分配 5 bits 的空间,足矣。
这一步,可以说是把吝啬发挥到极致,精打细算,按需分配。
以上三个步骤,共同组成了一项编码技术:
4.2、如何快速求交集
在 Lucene 中查询,通常不只有一个查询条件,比如我们想搜索:
- 含有“生存”相关词语的文档
- 文档发布时间在最近一个月
- 文档发布者是平台的特约作者
这样就需要根据三个字段,去三棵倒排索引里去查,当然,磁盘里的数据,上面提到过,用了相关算法进行压缩,所以我们要把数据进行反向处理,即解压,才能还原成原始的文档 ID,然后把这三个文档 ID 数组在内存中做一个交集。
注意:即使没有多条件查询,Lucene 也需要频繁求交集,因为 Lucene 是分配存储的。
同样,我们把 Lucene 遇到的问题,简化成一道算法题。
假设有下面三个数组,求它们的交集:
[64, 300, 303, 343] 、 [73, 300, 302, 303, 343, 372] 、 [303, 311, 333, 343]
方案一:Integer 数组
直接用原始的文档 ID ,可能你会说,那就逐个数组遍历一遍吧,遍历完就知道交集是什么了。
其实对于有序的数组,用跳表(skip table)可以更高效,这里就不展开了,因为不管是从性能,还是空间上考虑,Integer 数组都不靠谱,假设有100M 个文档 ID,每个文档 ID 占 2 bytes,那已经是 200 MB,而这些数据是要放到内存中进行处理的,把这么大量的数据,从磁盘解压后丢到内存,内存肯定撑不住。
方案二:Bitmap
假设有这样一个数组:[3,6,7,10]
那么我们可以这样来表示:[0,0,1,0,0,1,1,0,0,1],即 3 是在第三个位置标记为 1,6 在第六个位置标记为 1,以此类推......
看出来了么,对,我们用 0 表示角标对应的数字不存在,用 1 表示存在。
这样带来了两个好处:
- 节省空间:既然我们只需要0和1,那每个文档 ID 就只需要 1 bit,还是假设有 100M 个文档,那只需要 100M bits = 100M * 1/8 bytes = 12.5 MB,比之前用 Integer 数组 的 200 MB,优秀太多
- 运算更快:0 和 1,天然就适合进行位运算,求交集,「与」一下,求并集,「或」一下,一切都回归到计算机的起点
方案三:Roaring Bitmaps
细心的你可能发现了,bitmap 有个硬伤,就是不管你有多少个文档,你占用的空间都是一样的,之前说过,Lucene Posting List 的每个 Segement 最多放 65536 个文档ID,举一个极端的例子,有一个数组,里面只有两个文档 ID:
[0, 65535]
用 Bitmap,要怎么表示?
[1,0,0,0,….(超级多个0),…,0,0,1]
你需要 65536 个 bit,也就是 65536/8 = 8192 bytes,而用 Integer 数组,你只需要 2 * 2 bytes = 4 bytes
呵呵,死板的 bitmap。可见在文档数量不多的时候,使用 Integer 数组更加节省内存。
我们来算一下临界值,很简单,无论文档数量多少,bitmap都需要 8192 bytes,而 Integer 数组则和文档数量成线性相关,每个文档 ID 占 2 bytes,所以:
8192 / 2 = 4096
当文档数量少于 4096 时,用 Integer 数组,否则,用 bitmap。
怎么做呢?可以详细点吗?
1. 当使用数组 list 的形式,使用 skiplist 数据结构,同时遍历 包含生存关键词、最近一个月 和 签约作者 的 posting list,互相 skip 即可
2. 当使用 bitmap 数据结构的时候,分别对 同时遍历 包含生存关键词、最近一个月 和 签约作者 的 posting list 求出对应的 bitmap,然后直接 按位与 操作即可。