InnoDB 概念学习笔记
本笔记主要是先理清InnoDB涉及的一些重要概念。
整体架构

执行单位
按照《MySQL技术内幕》一书的逻辑,体系架构被分为线程、内存池和文件三部分。物理执行层面确实这么分也没问题,毕竟其他的数据库逻辑概念也得在这三者中去体现。此处会先介绍每个物理部分涉及的功能或概念,后续会放到相应的数据库逻辑路径上去另外介绍。
需注意:8.0很多实现和书中介绍还是有差别的,可以参照书中的概念入手,但还是要结合对应版本代码去验证
线程
InnoDB的线程分类可以粗略理解,主要是一个MasterThread主线程,然后配合上一些功能性线程池(IO、Purge)等,然后还有一些拆分出来单独线程协作分担MasterThread的工作(PageCleanerThread)。
Master Thread
8.0源码入口见 srv_mater_thread()。master_thread除了初始化部分,负责的事情归纳如下:
- log_free_check(),检查redo log的存储空间是否足够。如果认为不足够,则会wait。
- srv_master_do_active_tasks(),这里是个计数器,如果activity值大于前值,则说明有新的活动,会调用该函数。什么东西算是server activity?
- srv_master_do_idle_tasks(),如果没有新的活动,则进入idle_tasks()。实际代码基本和srv_master_do_active_tasks() 一样。不知道为啥一样,感觉是历史原因变成这样?
- row_drop_tables_for_mysql_in_background() ,drop table只能发生在没有SELECT quries的时候。
- merge insert buffer 合并插入缓冲到文件的索引页(缓冲池里的页的修改直接写入),结合外层的loop就构成了一个定时合并ibuf的cron逻辑。
- srv_master_evict_from_table_cache(uint check_precent),清除table cache中无用的table。active下检查比例是50%(即检查50%的cache看看又没能evict的),idle是100%。table_cache是一个LRUcache,缓存最近访问的table的元信息。
看上去MasterThread里的工作很零散(包括被移出去的PageCleaner),实际的设计思路是MasterThread负责InnoDB里的Background Operations,而后台活动主要也就是各种检查、清理、刷脏等。前台活动的线程由上层server层的THD提供,不经过MasterThread的逻辑。
PageCleanerThread
InnoDB1.2版本从MasterThread拆分出来的单独线程,负责将bufferpool的脏页刷至磁盘,减轻MasterThread的工作压力。
PageCleaner其实也是一组线程,数量由page_cleaners变量决定,默认为4,共享一个静态变量static page_cleaner_t *page_cleaner来接收flush request和是否running的状态。额外会有一个coordinator线程,所以实际线程数量是page_cleaners+1 。
IO Threads
分为read和write,配置参见read_io_threads和write_io_threads。InnoDB用AIO (libaio) 来实现IO,对于不完善支持libaio的MacOSX则自己实现了一套模拟AIO的代码。
if (!srv_read_only_mode) {
/* Add the log and ibuf IO threads. */
srv_n_file_io_threads += 2;
}
/* For read only mode, we don't need ibuf and log I/O thread.
Please see innobase_start_or_create_for_mysql() */
ulint start = (srv_read_only_mode) ? 0 : 2;
for (ulint t = 0; t < srv_n_file_io_threads; ++t) {
if (t < start) {
if (t == 0) {
os_thread_create(io_ibuf_thread_key, io_handler_thread, t);
} else {
ut_ad(t == 1);
os_thread_create(io_log_thread_key, io_handler_thread, t);
}
} else if (t >= start && t < (start + srv_n_read_io_threads)) {
os_thread_create(io_read_thread_key, io_handler_thread, t);
} else if (t >= (start + srv_n_read_io_threads) &&
t < (start + srv_n_read_io_threads + srv_n_write_io_threads)) {
os_thread_create(io_write_thread_key, io_handler_thread, t);
} else {
os_thread_create(io_handler_thread_key, io_handler_thread, t);
}
}
IO Threads的分配可参见上述来自 srv_start()的代码。非readonly模式下,会额外多出一个ibuf线程和一个log线程。最后一个else的io_handler_thread_key按照目前代码逻辑应当是不会进入的。
Purge Threads
srv_start_purge_threads(), 由purge_threads参数控制worker线程数量,额外有一个coordinator线程。用于回收undo log,undo log在没有事务使用的时候可以删除。目前支持多个PurgeThreads并行回收,这是很有必要的,因为这种异步回收方式在压力大的时候会出现回收跟不上的情况,导致无用日志占空间越滚越大。
redo log不需要专门删除,事务落盘后,相应的存储位置会释放出来重用给后面的redo log写入(recycle log 的方式)。binlog则是expire_logs_days 到期后回收。
其他线程
MySQL8.0代码中的线程实际比起其他资料介绍的要多不少,具体可以在innodb代码里搜索 os_thread_create。log相关的、fts相关的都未介绍。
内存池
BufferPool
BufferPool是一个由Page组成的LinkedList实现的缓冲池,采用一种优化的LRU算法。BufferPool在单个InnoDB实例中允许存在多个(after 1.0.x)。
LRU in BufferPool 被分为了两部分,默认配置中,大约5/8属于new区,剩下3/8属于old区,由一个midpoint划分开(配置innodb_old_blocks_pct,默认值37,37%约等于3/8)。实际上new区并不一定代表其中的page就是最新的,而是代表最活跃的。想象在scan场景(尤其是全表扫描),每个页都会被访问一次,但是绝大部分scan的页一般也只会在本次scan中被用到一次然后快速地又被换出,并且一般内存容量也不可能将全量的页从磁盘缓存到内存。因此,由于full scan或scan prefetching等场景而导致BufferPool原来的pattern失效,是一件对整体应用性能极其不友好的事。
当前解决方案是 新的page页在进入LRU链表中时,会先插入到old sublist 的头部,然后page需要在old sublist中停留innodb_old_blocks_time(默认1000ms)这么久后,下一次对该page的访问才会使其移动到new sublist的头部。也就是说,scan的page只会在old sublist上换入换出,而不会影响到new sublist的缓存pattern。
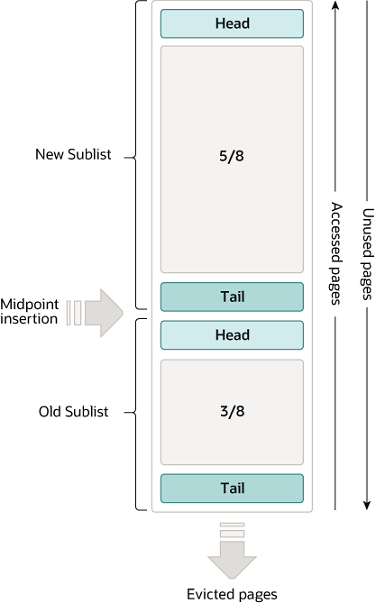
BufferPool中有三种page
- free page: 此page未被使用,此种类型page位于Free List 中
- clean page: 此page被使用,对应数据文件中的一个页面,但是页面没有被修改,此种类型page位于LRU List中
- dirty page: 此page被使用,对应数据文件中的一个页面,但是页面被修改过,此种类型page位于LRU List和Flush List中
BufferPool中实际存在三种page linkedlist结构:
- Free List: 存放free page的列表
- LRU List: 上述所描述的LRU就是LRU List。
- Flush List:LRU列中数据被修改后,产生脏页。数据库通过checkpoint机制将脏页刷新会磁盘,Flush List中的页即为脏页列表。脏页即存在于LRU中,也存在于Flush中。LRU List用于管理缓冲池中页的可用性,Flush List用于将页刷新回磁盘。
画图 其行为大致是,InnoDB启动时都是free pages on Free List,随着用户使用,LRU List会逐渐被填充,其中被修改过的dirty pages就会提交给Flush List去刷脏。刷盘后的dirty pages就会转为free pages还给 Free List,等待分配。最后是否所有flush操作都会还给Free List存疑
Buffer Pool LRU/Flush List flush对比:
- LRU list flush,由用户线程触发(MySQL 5.6.2之前);而Flush list flush由MySQL数据库InnoDB存储引擎后台srv_master线程处理。(在MySQL 5.6.2之后,都被迁移到page cleaner线程中)
- LRU list flush,其目的是为了写出LRU 链表尾部的dirty page,释放足够的free pages,当buf pool满的时候,用户可以立即获得空闲页面,而不需要长时间等待;Flush list flush,其目的是推进Checkpoint LSN,使得InnoDB系统崩溃之后能够快速的恢复。
- LRU list flush,其写出的dirty page,需要移动到LRU链表的尾部(MySQL 5.6.2之前版本);或者是直接从LRU链表中删除,移动到free list(MySQL 5.6.2之后版本)。Flush list flush,不需要移动page在LRU链表中的位置。
- LRU list flush,由于可能是用户线程发起,已经持有其他的page latch,因此在LRU list flush中,不允许等待持有新的page latch,导致latch死锁;而Flush list flush由后台线程发起,未持有任何其他page latch,因此可以在flush时等待page latch。
- LRU list flush,每次flush的dirty pages数量较少,基本固定,只要释放一定的free pages即可;Flush list flush,根据当前系统的更新繁忙程度,动态调整一次flush的dirty pages数量,量很大。
Redo log buffer
redo log会有一段内存专门用来作为写缓存,大小为 innodb_log_buffer_size(默认16MB)。log_buffer_write()的时候实际是memcpy到了缓存中,log_buffer_flush_to_disk()才会刷盘。刷盘时每一个block都是OS_FILE_LOG_BLOCK_SIZE=512 byte。
redo log刷盘触发条件:
- srv_start()
- binary log group commit
- 存疑,low level代码没见到16MB满了触发flush这种逻辑
Adaptive Hash Index (AHI)
InnoDB观察到符合如下情况时,会对缓冲池里的对应页构建Hash索引,加速页的定位查找:
- enable AHI,并且该页未被加写锁
- 对于该页的连续的访问模式必须一样(查询条件必须完全一样)
- 访问模式查询了100次
- 页通过该访问模式被访问到了N次,N = 页中记录数 / 16
On-disk structure
基本概念
-
Row 行:InnoDB存储引擎是面向行的(row-oriented),每个页存放的行记录最多允许存放16KB / 2 = 7992行记录。
-
Page 页:默认16k,innodb最基本的存储单位。innoDB存储引擎中,常见的页类型有:
- 数据页(B-tree Node)
- undo页(undo Log Page)
- 系统页 (System Page)
- 事务数据页 (Transaction System Page)
- 插入缓冲位图页(Insert Buffer Bitmap)
- 插入缓冲空闲列表页(Insert Buffer Free List)
- 未压缩的二进制大对象页(Uncompressed BLOB Page)
- 压缩的二进制大对象页 (compressed BLOB Page)
-
Extent 区:每个文件按照固定的page size进行区分,默认情况下,非压缩表的page size为16Kb。在文件内部又按照64个Page(总共1M)一个Extent的方式进行划分并管理。对于不同的page size,对应的Extent大小也不同,对应为:
page size file space extent size
4 KiB 256 pages = 1 MiB
8 KiB 128 pages = 1 MiB
16 KiB 64 pages = 1 MiB
32 KiB 64 pages = 2 MiB
64 KiB 64 pages = 4 MiB -
Segment 段:逻辑概念。一棵B+树会分为数据段和索引段。存疑?和ibuf/log 的线程 segment有什么关系?
- 数据段 leaf-node segment,又称为叶节点段,存储实际的行数据
- 索引段 non-leaf node segment,又称为内节点段,存储索引。
- 回滚段 rollback segment,undo pages所在的段。
-
Tablespace 表空间:由不同的段组成。InnoDB把数据保存在表空间内,表空间可以看作是InnoDB存储引擎逻辑结构的最高层。本质上是一个由一个或多个磁盘文件组成的虚拟文件系统。InnoDB用表空间并不只是存储表和索引,还保存了回滚段、双写缓冲区等。表空间分为了两种:
- 独立表空间:启用参数innodb_file_per_table,每一个表都将会生成以独立的文件方式来进行存储,每一个表都有一个.frm表描述文件,还有一个.ibd文件。 其中这个文件包括了单独一个表的数据内容以及索引内容,默认情况下它的存储位置也是在表的位置之中。
- 共享表空间: Innodb的所有数据保存在一个单独的表空间里面,而这个表空间可以由很多个文件组成,一个表可以跨多个文件存在,所以其大小限制不再是文件大小的限制,而是其自身的限制。从Innodb的官方文档中可以看到,其表空间的最大限制为64TB,也就是说,Innodb的单表限制基本上也在64TB左右了,当然这个大小是包括这个表的所有索引等其他相关数据。
-
Fil_system (File system): 在InnoDB的内存中维护了一个
Fil_system的数据结构来缓存整个文件管理.Fil_system分为64个shard. 而每个shard管理多个Tablespace。64个shard中,第1个即索引为0的shard属于系统表空间,最后一个shard即索引为63的shard为Redo Log的Tablespace, 而58-61是属于Undo Log的shard。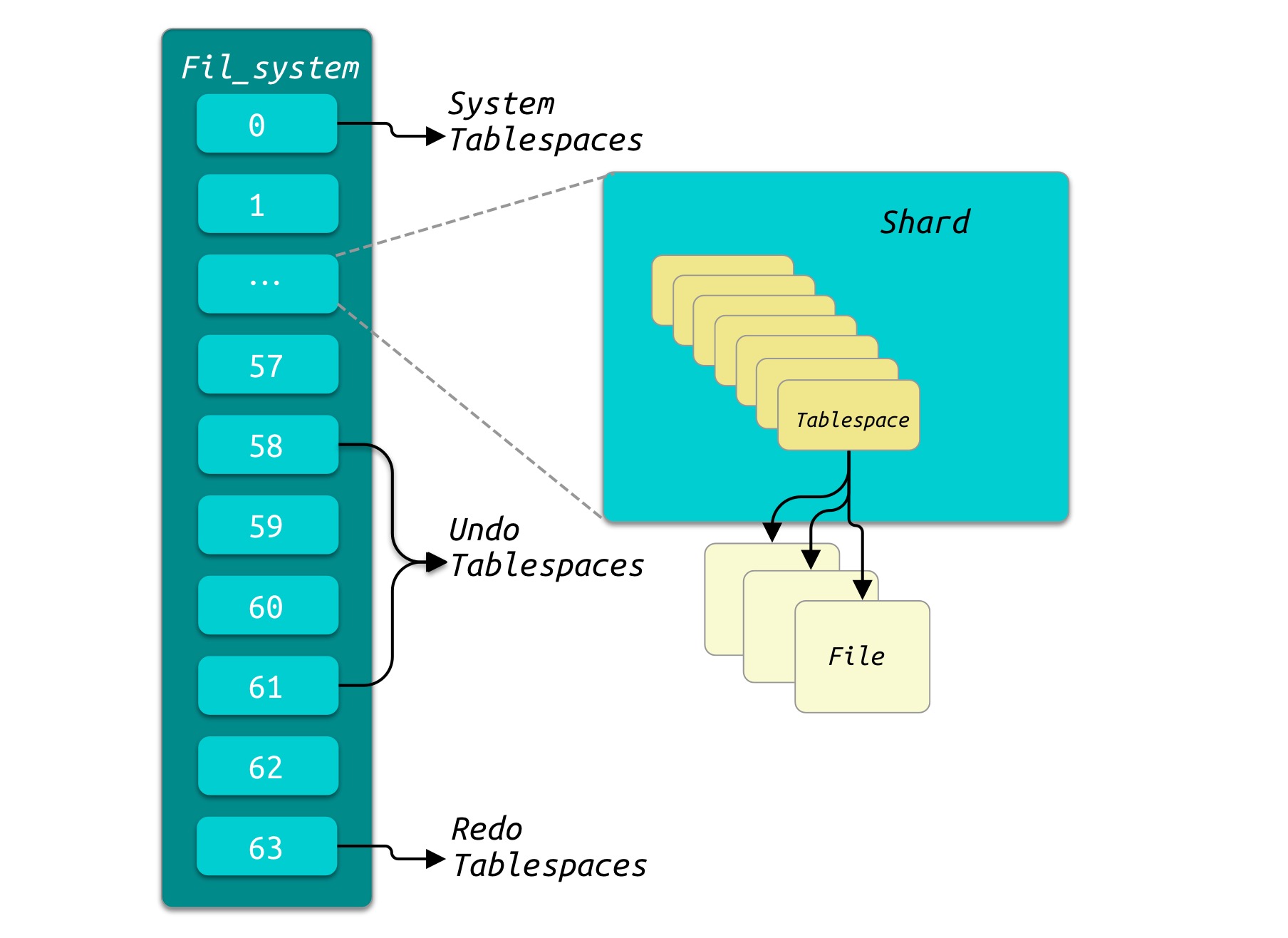
-
undo pages: 记录page的上一个状态,用于实现多版本和事务的回滚。
-
redo log: 相当于可重放的WAL,InnoDB用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。
-
binlog: 由Server层产生的binlog记录了对MySQL数据库执行更改的所有操作,不包括SELECT、SHOW等只读操作,包括即使没有造成实际数据变化的写操作。
redo log与binlog的区别
- redo log是在InnoDB存储引擎层产生,而binlog是MySQL数据库的上层产生的,并且二进制日志不仅仅针对INNODB存储引擎,MySQL数据库中的任何存储引擎对于数据库的更改都会产生二进制日志。
- 两种日志记录的内容形式不同。MySQL的binlog是逻辑日志,其记录是对应的SQL语句。而innodb存储引擎层面的重做日志是物理日志。
- 两种日志与记录写入磁盘的时间点不同,二进制日志只在事务提交完成后进行一次写入。而innodb存储引擎的重做日志在事务进行中不断地被写入,并日志不是随事务提交的顺序进行写入的。二进制日志仅在事务提交时记录,并且对于每一个事务,仅在事务提交时记录,并且对于每一个事务,仅包含对应事务的一个日志。而对于innodb存储引擎的重做日志,由于其记录是物理操作日志,因此每个事务对应多个日志条目,并且事务的重做日志写入是并发的,并非在事务提交时写入,其在文件中记录的顺序并非是事务开始的顺序。
- binlog不是循环使用,在写满或者重启之后,会生成新的binlog文件,redo log是循环使用。
- binlog可以作为恢复数据使用,主从复制搭建,redo log作为异常宕机或者介质故障后的数据恢复使用。
ChangeBuffer
名字虽然是Buffer,但实际是单独的一类物理页,包括InsertBuffer、DeleteBuffer、PurgeBuffer,分别对应DML的insert、delete、update。仅作用于非UNIQUE的二级索引,因为ChangeBuffer并没有去查找索引来确定当前插入key是唯一的这一步骤。每个Buffer实际上是一棵B+Tree(据说是全局的B+Tree,而不是按表划分的?)。
InsertBuffer:每次插入非聚集索引时,先检查对应索引页是否在缓冲池中,如果在则直接插入;否则,写入到InsertBuffer中,然后会定期或条件触发merge ibuf操作。这种思想有点近似于LSM的做法,先写到当前的乱序的level-0,然后之后再和主要存储数据的higher levels去做合并。这样的好处是提高写入效率,减少边写边查的情况。
触发merge ibuf的原因包括:
- MasterThread 的loop检查
- 相应的二级索引页要被读到缓冲池
- InsertBuffer Bitmap页追踪到该二级索引页在InsertBuffer上已无可用空间
存疑:所以实际的page组织是怎么样的?数据和page的映射是怎么决定的?
DoubleWriteBuffer
名字虽然是Buffer,但实际是一片顺序物理存储,相当于页刷入磁盘时的WAL。一个innodb页一般16k,但在OS层一个IO一般是4k,所以如果只写了16k的一部分然后宕机了,这时候就会出现'partial page write' ,即写入失败了,但部分页已经被更新了。
如果数据先顺序写入DoubleWriteBuffer,然后再刷盘,就算部分失败,也可借助DoubleWriteBuffer 里的页信息去重新apply一遍写入。DoubleWriteBuffer由于是顺序写,因此写入效率也比较高、写入失败也能比较容易恢复(Append写)。