创建索引很简单,但是能深入理解索引原理又能恰到好处使用索引又是另外一回事。
-
为什么要给表加上主键?
-
为什么加索引后会使查询变快?
-
为什么加索引后会使写入、修改、删除变慢?
-
什么情况下要同时在两个字段上建索引?
为什么要给表加上主键?
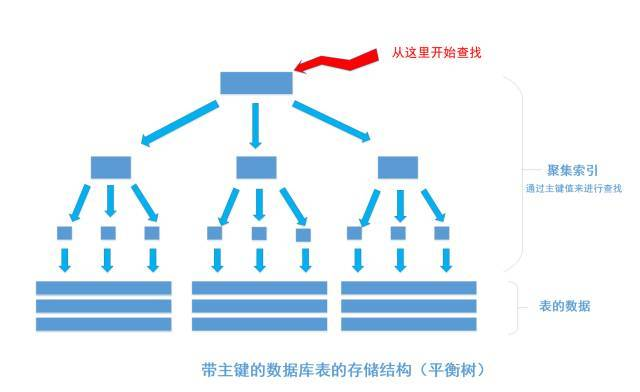
我们平时建表的时候都会为表加上主键, 在某些关系数据库中, 如果建表时不指定主键,数据库会拒绝建表的语句执行。 事实上, 一个加了主键的表,并不能被称之为「表」。一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我认知中的「表」很接近。如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引。
没错, 再说一遍, 整个表变成了一个索引,也就是所谓的「聚集索引」。 这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。
讲完聚集索引 , 接下来聊一下非聚集索引, 也就是我们平时经常提起和使用的常规索引。
非聚集索引和聚集索引一样, 同样是采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,在数据改变时, DBMS需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。 如下图
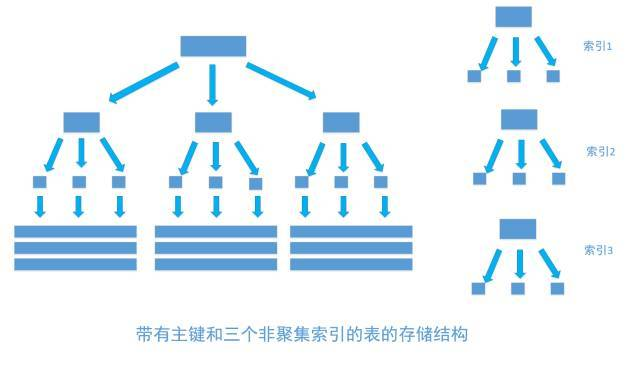 每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。
非聚集索引和聚集索引的区别在于, 通过聚集索引可以直接查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 ,再使用主键的值通过聚集索引查找到需要的数据,如下图
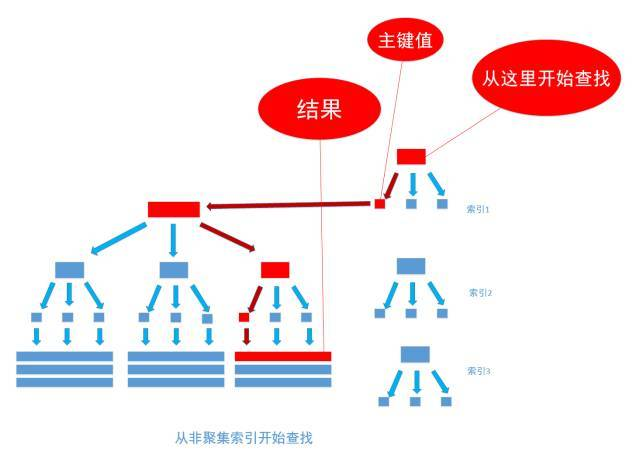
不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径。
然而, 有一种例外可以不使用聚集索引就能查询出所需要的数据, 这种非主流的方法 称之为「覆盖索引」查询, 也就是平时所说的组合索引、复合索引或者多字段索引查询。 文章上面的内容已经指出, 当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
先看下面这个SQL语句
//建立索引 create index index_birthday on user_info(birthday); //查询生日在1991年11月1日出生用户的用户名 select user_name from user_info where birthday = '1991-11-1'
这句SQL语句的执行过程如下
首先,通过非聚集索引index_birthday查找birthday等于1991-11-1的所有记录的主键ID值
然后,通过得到的主键ID值执行聚集索引查找,找到主键ID值对就的真实数据(数据行)存储的位置
最后, 从得到的真实数据中取得user_name字段的值返回, 也就是取得最终的结果
我们把birthday字段上的索引改成双字段的覆盖索引,
create index index_birthday_and_user_name on user_info(birthday, user_name);
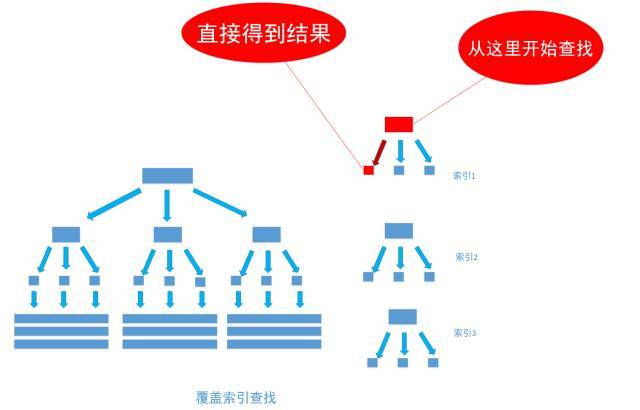
通过非聚集索引index_birthday_and_user_name查找birthday等于1991-11-1的叶节点的内容,然而, 叶节点中除了有user_name表主键ID的值以外, user_name字段的值也在里面, 因此不需要通过主键ID值的查找数据行的真实所在, 直接取得叶节点中user_name的值返回即可。 通过这种覆盖索引直接查找的方式, 可以省略不使用覆盖索引查找的后面两个步骤, 大大的提高了查询性能,如下图
再详细说下这个覆盖索引,也叫组合索引
组合索引,即一个索包含多个列。(当一个表中查询大的情况下,where条件中有多个,那么可以使用组合查询,不会扫描表,直接从索引中获取,查询效率高)
它遵循最左前缀匹配原则,也是就是说一个查询可以只使用复合索引最左侧的一部份。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
因为组合索引建立的时候先对第一维排序,再对第二维,再对第三维...(非常不严谨的说法,但便于初学者理解)
对于如下表结构:
create table test( a int, b int, c int, KEY a(a,b,c) );
那么我们看一下下列语句:
优: select * from test where a=10 and b>50 差: select * from test where b = 50 优: select * from test order by a 差: select * from test order by b 差: select * from test order by c 优: select * from test where a=10 order by a 优: select * from test where a=10 order by b 差: select * from test where a=10 order by c 优: select * from test where a>10 order by a 差: select * from test where a>10 order by b // 其实会索引失效 差: select * from test where a>10 order by c 优: select * from test where a=10 and b=10 order by a 优: select * from test where a=10 and b=10 order by b 优: select * from test where a=10 and b=10 order by c 优: select * from test where a=10 and b=10 order by a 优: select * from test where a=10 and b>10 order by b 差: select * from test where a=10 and b>10 order by c
重点:如果where条件第一个参数取范围值,会导致索引失效(>或者<等相关范围查询),后面的索引也会失效。
比如:select * from test where a>10 order by b 组合索引失效。
注:在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
参考链接: