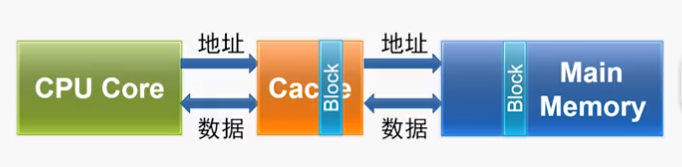
高速缓存的原理
cpu和内存的速度差距越来越大,计算机的性能受到影响,而高速缓存的出现挽救了这一局面。

为什么在cpu和主存直接添加一个容量很小、速度更快的高速缓存能增加计算机的性能呢?
程序的局部性原理
这是一个经验性结论:计算机程序从时间和空间都表现出局部性。
时间局部性(Temporal Locality):最近被访问的存储单元(指令或数据)很快会被访问
例如:
for(int i = 0;i < 100;i++) for(int j = 0;j < 100;j++) sum += a[i][j];
其中的sum、判断指令、加法指令、递增指令都会马上被访问
空间局部性(Spatial Locality):正在被访问的存储单元附近单元很快会被访问
例如,a[i][j]的附近的元素很快会被访问
Cache对局部性的利用
Cache对空间局部性的利用
- 从主存中取出待访问的数据时,会同时取回相邻位置的主存单元的数据
- 以数据块为单位与主存进行数据交换
Cache对时间局部性的利用
- 保存最近被频繁访问的数据元素
Cache的访问过程
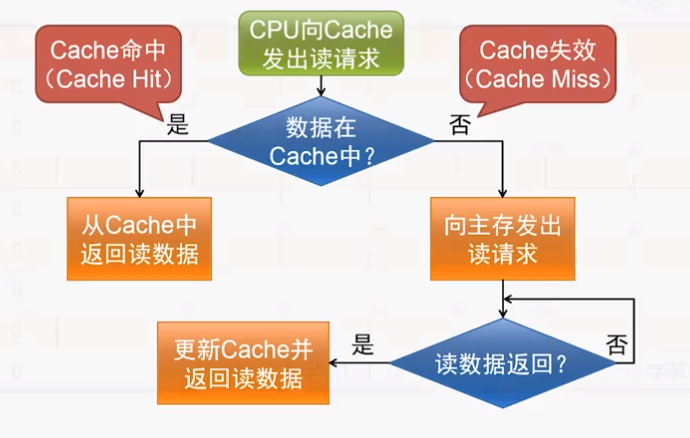
具体是如何实现的呢?示例过程:
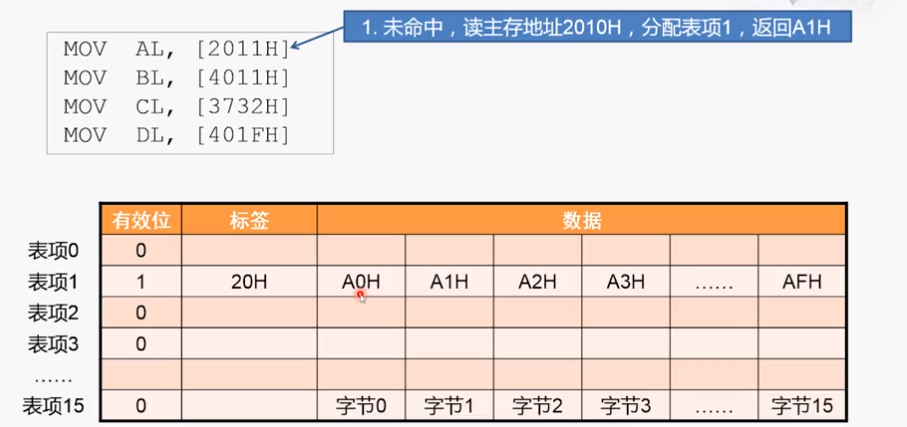
1、由于是16个字节对齐,所以从2010H开始读取数据。每个块16个字节,所以最低位刚好表示在块中的索引,倒数第二位表示块的索引。所以第一次是分配表项1,为命中,将标签设为20H,有效位改为1
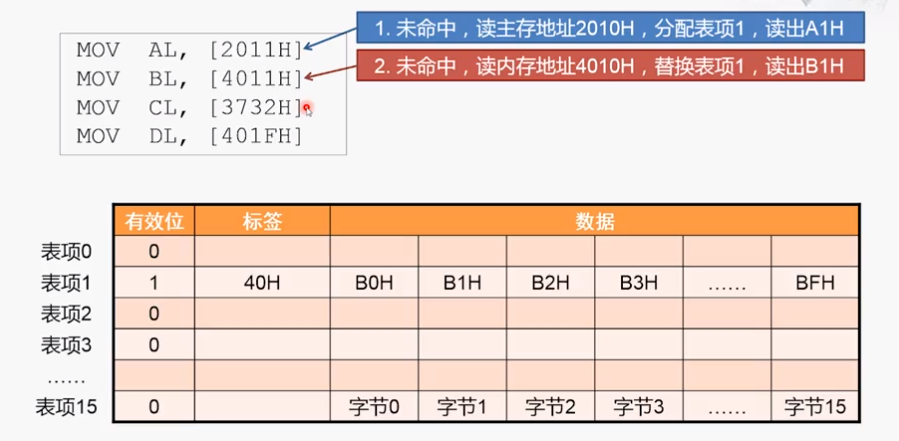
2、对应的表项已经有数据且不是当前数据,当前表项数据和标签都要替换
3、未命中,将数据存到cache的表项三,并返回32H
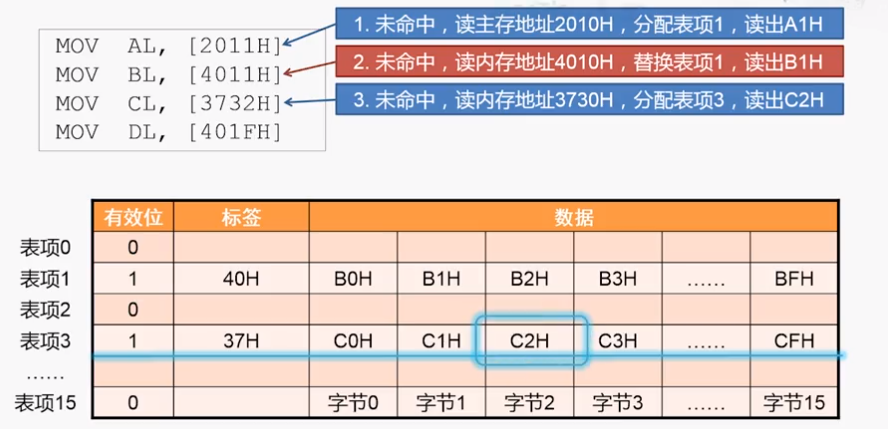
4、对应的表项1有数据(有效位为1),且标签也相同,命中,根据低位找到数据并放回
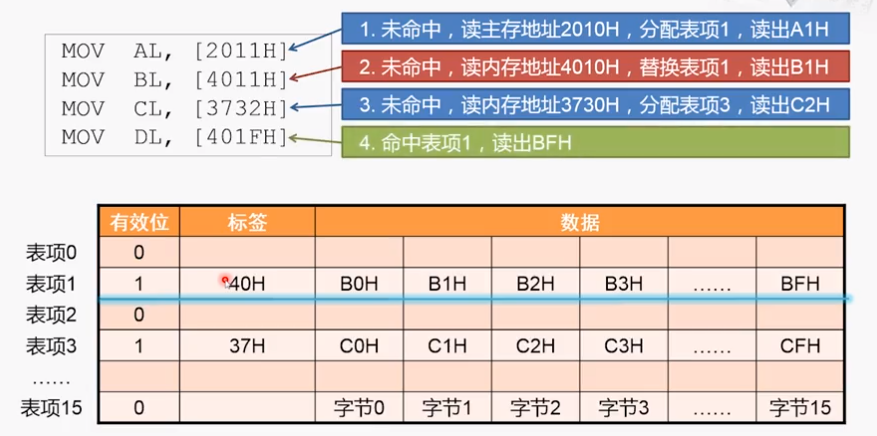
看完了读操作,我们再来看cache的写操作。
Cache的写策略
cache命中时
- 写穿透(Write Through):数据同时写入cache和主存(这样保证了cache和内存中始终保持一致)
- 写返回(Write Back):数据只写入cache,仅当该数据块被替换时才将数据写回内存
cahce失效时
- 写不分配(Write Non-allocate):直接将数据写入内存
- 写分配(Write Allocate):将该数据所在的块读入cache后,再将数据写入cache
写分配需要将数据读入cache中再写入,看起来比写不分配要慢,但是根据局部性的原理,现在写入的数据等下很可能要使用,提前写入cache能使后面的访存性能大大提升。
所以在现在cache的设计中,写创投和写不分配往往是配套使用的,用于那些对性能要求不高但设计简单的系统,对性能要求较高的,通常使用写返回和写分配。
对于如何去查找、替换cache中的表项,与读操作是类似的
平均访存时间
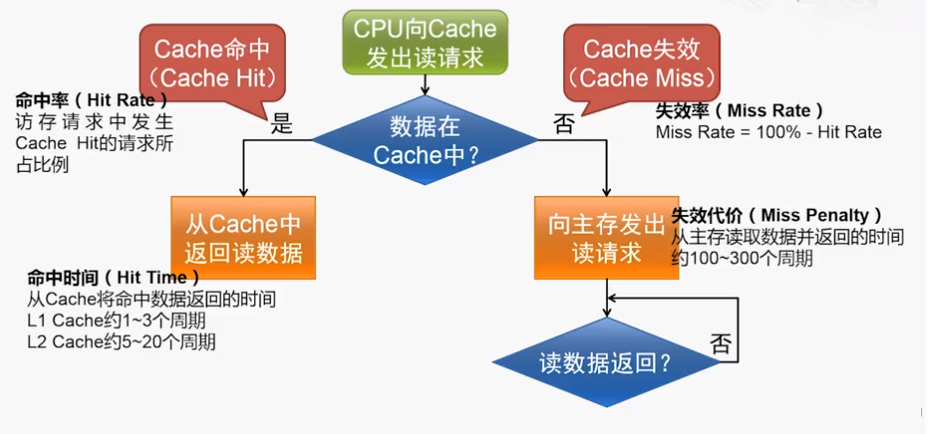
所以可以得到平均访存时间的计算公式:
平均访存时间(Average Memrory Access Time) = 命中时间(Hit time) + 缺失率(Miss Rate) x 缺失代价(Miss Penalty)
减少平均访存时间的三个途径:
- 降低Hit Time:要求cache的容量小一点,cache的结构简单一点
- 减少Miss Penalty:提升主存的性能、再增加一层cache
- 降低Miss Rate:增大cache的容量
Cache的映射策略
直接映射
例如,如果有一个8表项的cache,直接映射的情形如图:
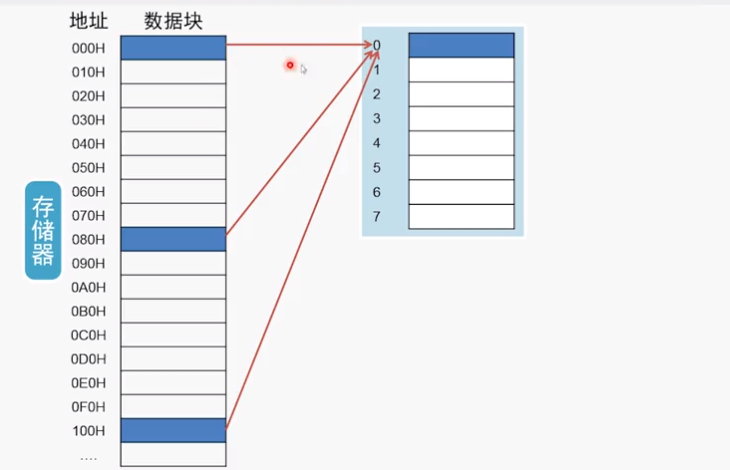
相当于模8
特点:计算规则简单,缺点是如果交替的访问两个数据a,b(差能整除8),将会一直miss
二路组相联
如果跟刚才一样,交替访问a,b,a被放在第一行第一个位置,然后b被放在第一行第二个,之后在访问a,b时都能hit。
如果是交替访问a,b,c呢?二路组相连也不行了
在不增加cache总的容量的情况下,还可以进一步切分,比如四路组相联

是不是可以无限切分下去呢?最多全部展开,像这里的八路组相联。内存当中任一个数据块都可以放到这个Cache当中的任何一个行中, 而不用通过地址的特征来约定固定放在哪一个行,那这样结构的Cache就叫做全相联的cache。
是不是组数越多越好呢?当然不是,组数越多,确定行之后要比较的标签也会变增加。这样降低了缺失率,却增加了命中时间。且话又说回来,增加了路数,还不一定能够降低失效率,还跟替换策略有关。