从 Hudi v0.10.0 开始,我们很高兴地宣布推出适用于 Deltastreamer 的 Debezium 源,它提供从 Postgres 和 MySQL 数据库到数据湖的变更捕获数据 (CDC) 的摄取。有关详细信息请参阅原始 RFC
1. 背景

当想要对来自事务数据库(如 Postgres 或 MySQL)的数据执行分析时,通常需要通过称为更改数据捕获 CDC的过程将此数据引入数据仓库或数据湖等 OLAP 系统。 Debezium 是一种流行的工具,它使 CDC 变得简单,其提供了一种通过读取更改日志来捕获数据库中行级更改的方法,通过这种方式 Debezium 可以避免增加数据库上的 CPU 负载,并确保捕获包括删除在内的所有变更。
现在 Apache Hudi 提供了 Debezium 源连接器,CDC 引入数据湖比以往任何时候都更容易,因为它具有一些独特的差异化功能。 Hudi 可在数据湖上实现高效的更新、合并和删除事务。 Hudi 独特地提供了 Merge-On-Read 写入器,与使用 Spark 或 Flink 的典型数据湖写入器相比,该写入器可以显着降低摄取延迟。 最后,Apache Hudi 提供增量查询,因此在从数据库中捕获更改后可以在所有后续 ETL 管道中以增量方式处理这些更改下游。
2. 总体设计
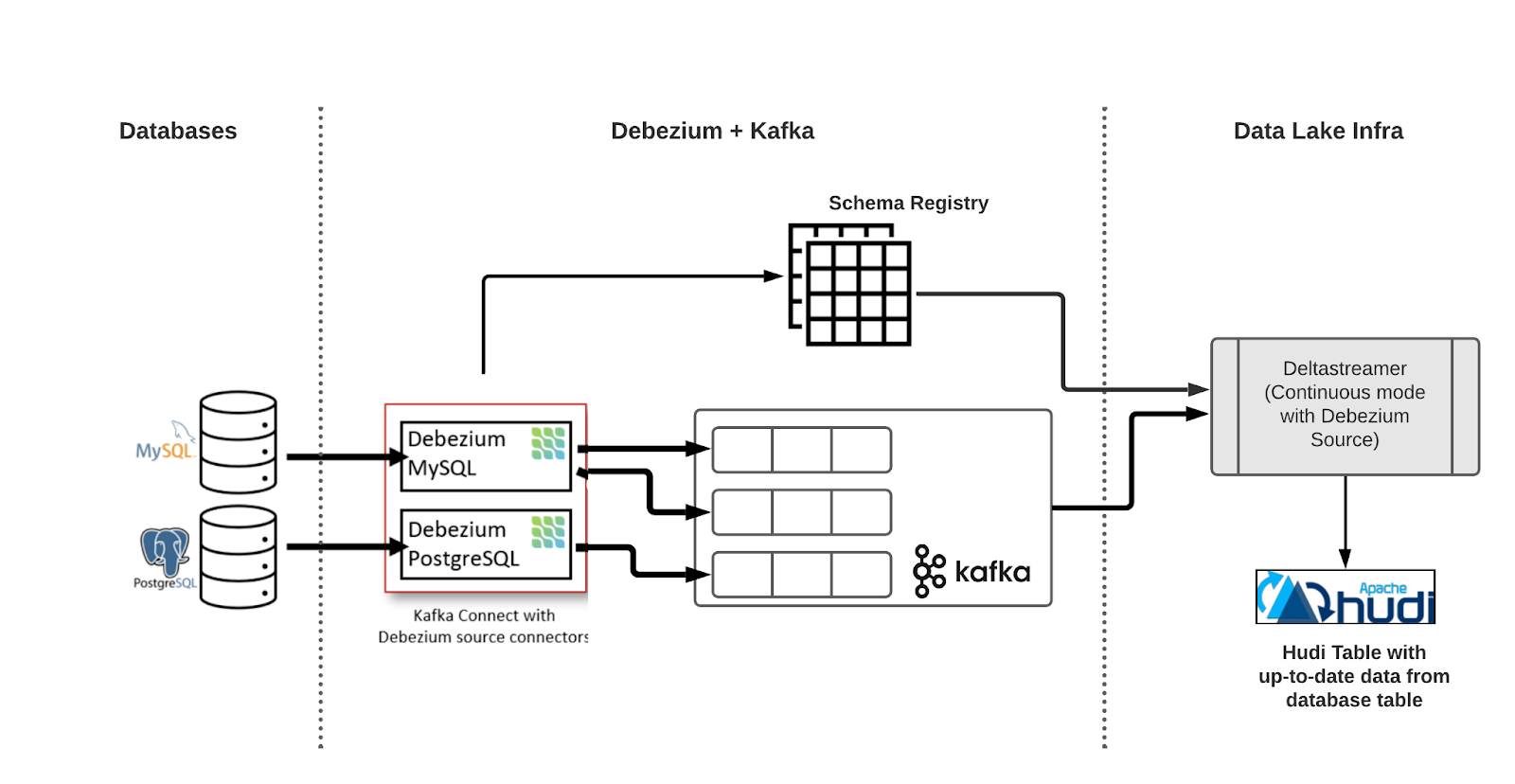
上面显示了使用 Apache Hudi 的端到端 CDC 摄取流的架构,第一个组件是 Debezium 部署,它由 Kafka 集群、schema registry(Confluent 或 Apicurio)和 Debezium 连接器组成,Debezium 连接器不断轮询数据库中的更改日志,并将每个数据库行的更改写入 AVRO 消息到每个表的专用 Kafka 主题。
第二个组件是 Hudi Deltastreamer,它为每个表从 Kafka 读取和处理传入的 Debezium 记录,并在云存储上的 Hudi 表中写入(更新)相应的行。
为了近乎实时地将数据库表中的数据提取到 Hudi 表中,我们实现了两个可插拔的 Deltastreamer 类。首先我们实现了一个 Debezium 源。 Deltastreamer 在连续模式下运行,源源不断地从给定表的 Kafka 主题中读取和处理 Avro 格式的 Debezium 更改记录,并将更新的记录写入目标 Hudi 表。 除了数据库表中的列之外,我们还摄取了一些由 Debezium 添加到目标 Hudi 表中的元字段,元字段帮助我们正确地合并更新和删除记录,使用Schema Registry表中的最新模式读取记录。
其次我们实现了一个自定义的 Debezium Payload,它控制了在更新或删除同一行时如何合并 Hudi 记录,当接收到现有行的新 Hudi 记录时,有效负载使用相应列的较高值(MySQL 中的 FILEID 和 POS 字段以及 Postgres 中的 LSN 字段)选择最新记录,在后一个事件是删除记录的情况下,有效负载实现确保从存储中硬删除记录。 删除记录使用 op 字段标识,该字段的值 d 表示删除。
3. Apache Hudi配置
在使用 Debezium 源连接器进行 CDC 摄取时,请务必考虑以下 Hudi 部署配置。
- 记录键 - 表的 Hudi 记录键应设置为上游数据库中表的主键。这可确保正确应用更新,因为记录键唯一地标识 Hudi 表中的一行。
- 源排序字段 - 对于更改日志记录的重复数据删除,源排序字段应设置为数据库上发生的更改事件的实际位置。 例如我们分别使用 MySQL 中的 FILEID 和 POS 字段以及 Postgres 数据库中的 LSN 字段来确保记录在原始数据库中以正确的出现顺序进行处理。
- 分区字段 - 不要将 Hudi 表的分区与与上游数据库相同的分区字段相匹配。当然也可以根据需要为 Hudi 表单独设置分区字段。
3.1 引导现有表
一个重要的用例可能是必须对现有数据库表进行 CDC 摄取。在流式传输更改之前我们可以通过两种方式获取现有数据库数据:
- 默认情况下,Debezium 在初始化时执行数据库的初始一致快照(由 config snapshot.mode 控制)。在初始快照之后它会继续从正确的位置流式传输更新以避免数据丢失。
- 虽然第一种方法很简单,但对于大型表,Debezium 引导初始快照可能需要很长时间。或者我们可以运行 Deltastreamer 作业,使用 JDBC 源直接从数据库引导表,这为用户定义和执行引导数据库表所需的更优化的 SQL 查询提供了更大的灵活性。引导作业成功完成后,将执行另一个 Deltastreamer 作业,处理来自 Debezium 的数据库更改日志,用户必须在 Deltastreamer 中使用检查点来确保第二个作业从正确的位置开始处理变更日志,以避免数据丢失。
3.2 例子
以下描述了使用 AWS RDS 实例 Postgres、基于 Kubernetes 的 Debezium 部署和在 Spark 集群上运行的 Hudi Deltastreamer 实施端到端 CDC 管道的步骤。
3.3 数据库
RDS 实例需要进行一些配置更改才能启用逻辑复制。
SET rds.logical_replication to 1 (instead of 0)
psql --host=<aws_rds_instance> --port=5432 --username=postgres --password -d <database_name>;
CREATE PUBLICATION <publication_name> FOR TABLE schema1.table1, schema1.table2;
ALTER TABLE schema1.table1 REPLICA IDENTITY FULL;
3.4 Debezium 连接器
Strimzi 是在 Kubernetes 集群上部署和管理 Kafka 连接器的推荐选项,或者可以选择使用 Confluent 托管的 Debezium 连接器。
kubectl create namespace kafka
kubectl create -f https://strimzi.io/install/latest?namespace=kafka -n kafka
kubectl -n kafka apply -f kafka-connector.yaml
kafka-connector.yaml 的示例如下所示:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: debezium-kafka-connect
annotations:
strimzi.io/use-connector-resources: "false"
spec:
image: debezium-kafka-connect:latest
replicas: 1
bootstrapServers: localhost:9092
config:
config.storage.replication.factor: 1
offset.storage.replication.factor: 1
status.storage.replication.factor: 1
可以使用以下包含 Postgres Debezium 连接器的 Dockerfile 构建 docker 映像 debezium-kafka-connect
FROM confluentinc/cp-kafka-connect:6.2.0 as cp
RUN confluent-hub install --no-prompt confluentinc/kafka-connect-avro-converter:6.2.0
FROM strimzi/kafka:0.18.0-kafka-2.5.0
USER root:root
RUN yum -y update
RUN yum -y install git
RUN yum -y install wget
RUN wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/1.6.1.Final/debezium-connector-postgres-1.6.1.Final-plugin.tar.gz
RUN tar xzf debezium-connector-postgres-1.6.1.Final-plugin.tar.gz
RUN mkdir -p /opt/kafka/plugins/debezium && mkdir -p /opt/kafka/plugins/avro/
RUN mv debezium-connector-postgres /opt/kafka/plugins/debezium/
COPY --from=cp /usr/share/confluent-hub-components/confluentinc-kafka-connect-avro-converter/lib /opt/kafka/plugins/avro/
USER 1001
一旦部署了 Strimzi 运算符和 Kafka 连接器,我们就可以启动 Debezium 连接器。
curl -X POST -H "Content-Type:application/json" -d @connect-source.json http://localhost:8083/connectors/
以下是设置 Debezium 连接器以生成两个表 table1 和 table2 的更改日志的配置示例。
connect-source.json 的内容如下
{
"name": "postgres-debezium-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "localhost",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname": "database",
"plugin.name": "pgoutput",
"database.server.name": "postgres",
"table.include.list": "schema1.table1,schema1.table2",
"publication.autocreate.mode": "filtered",
"tombstones.on.delete":"false",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "<schema_registry_host>",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "<schema_registry_host>",
"slot.name": "pgslot"
}
}
3.5 Hudi Deltastreamer
接下来我们使用 Spark 运行 Hudi Deltastreamer,它将从 kafka 摄取 Debezium 变更日志并将它们写入 Hudi 表。 下面显示了一个这样的命令实例,它适用于 Postgres 数据库。 几个关键配置如下:
- 将源类设置为 PostgresDebeziumSource。
- 将有效负载类设置为 PostgresDebeziumAvroPayload。
- 为 Debezium Source 和 Kafka Source 配置模式注册表 URL。
- 将记录键设置为数据库表的主键。
- 将源排序字段 (dedup) 设置为 _event_lsn
spark-submit \\
--jars "/home/hadoop/hudi-utilities-bundle_2.12-0.10.0.jar,/usr/lib/spark/external/lib/spark-avro.jar" \\
--master yarn --deploy-mode client \\
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer /home/hadoop/hudi-packages/hudi-utilities-bundle_2.12-0.10.0-SNAPSHOT.jar \\
--table-type COPY_ON_WRITE --op UPSERT \\
--target-base-path s3://bucket_name/path/for/hudi_table1 \\
--target-table hudi_table1 --continuous \\
--min-sync-interval-seconds 60 \\
--source-class org.apache.hudi.utilities.sources.debezium.PostgresDebeziumSource \\
--source-ordering-field _event_lsn \\
--payload-class org.apache.hudi.common.model.debezium.PostgresDebeziumAvroPayload \\
--hoodie-conf schema.registry.url=https://localhost:8081 \\
--hoodie-conf hoodie.deltastreamer.schemaprovider.registry.url=https://localhost:8081/subjects/postgres.schema1.table1-value/versions/latest \\
--hoodie-conf hoodie.deltastreamer.source.kafka.value.deserializer.class=io.confluent.kafka.serializers.KafkaAvroDeserializer \\
--hoodie-conf hoodie.deltastreamer.source.kafka.topic=postgres.schema1.table1 \\
--hoodie-conf auto.offset.reset=earliest \\
--hoodie-conf hoodie.datasource.write.recordkey.field=”database_primary_key” \\
--hoodie-conf hoodie.datasource.write.partitionpath.field=partition_key \\
--enable-hive-sync \\
--hoodie-conf hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor \\
--hoodie-conf hoodie.datasource.write.hive_style_partitioning=true \\
--hoodie-conf hoodie.datasource.hive_sync.database=default \\
--hoodie-conf hoodie.datasource.hive_sync.table=hudi_table1 \\
--hoodie-conf hoodie.datasource.hive_sync.partition_fields=partition_key
4. 总结
这篇文章介绍了用于 Hudi Deltastreamer 的 Debezium 源,以将 Debezium 更改日志提取到 Hudi 表中。 现在可以将数据库数据提取到数据湖中,以提供一种经济高效的方式来存储和分析数据库数据。
请关注此 JIRA 以了解有关此新功能的更多信息。

