说到python爬虫,大牛们都会不约而同地提起Scrapy。因为Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中
Scrapy最初是为了页面抓取(更确切来说,网络抓取)所设计的,也可以应用在获取API所返回的数据(例如Amazon Associates Web Services)或者通用的网络爬虫
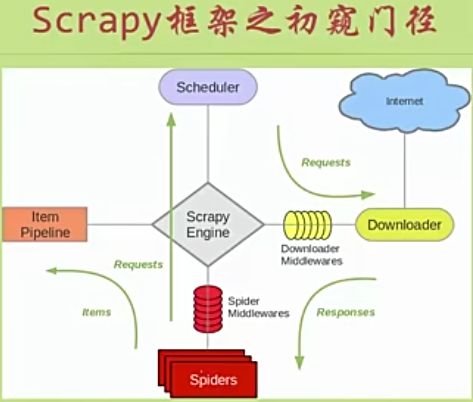
使用Scrapy抓取一个网站一共需要4个步骤:
---创建一个Scrapy项目
---定义Item容器
---编写爬虫
---存储内容
1、首先创建一个项目:scrapy startproject test0104
cd test0104,进入test0104文件夹下,可以看到test0104文件夹和scrapy.cfg文件
scrapy.cfg是项目文件,点击test0104文件夹,可以看到spiders文件夹和5个文件,如下图:

点击spiders文件夹,可以看到__init__.py文件,如下图:

Item是保存爬取到的数据的容器,其使用方法和python字典类似吗,并且提供了额外保护机制来避免拼写错误导致的未定义字段错误
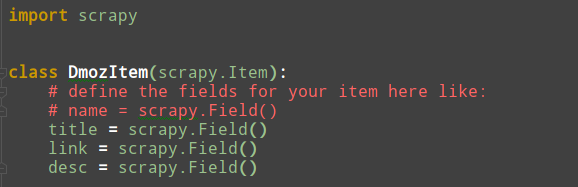
2、接下来test0104下的test0104下找到items.py文件,定义Item容器,修改代码如下图:
3、接下来是编写爬虫类Spider,Spider是用户编写用于从网站上爬取数据的类,其包含了一个用于下载的初始的URL,然后是如何跟进网页中的链接以及如何分析页面中的内容,还有提取生成item的方法
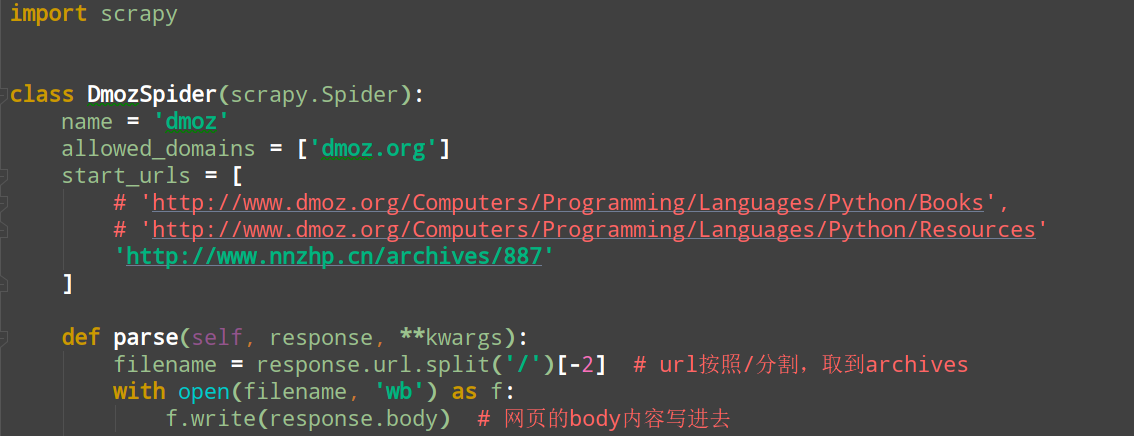
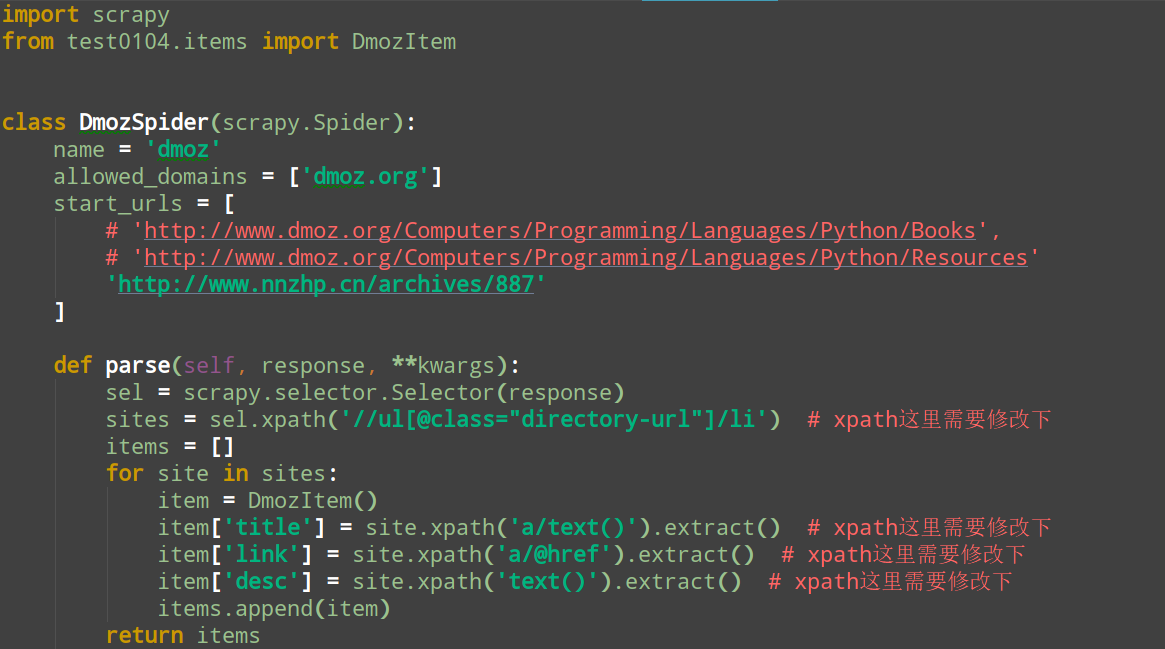
在test0104下的test0104的spiders文件夹下新建一个文件,dmoz_spider.py,代码如下:
scrapy crawl dmoz # 这个是代码里的name
在cmd里可以看到200的状态码,url也看到了,在根目录(test0104)下可以看到生成的文件archives,打开这个文件可以看到是爬到网页的代码,接下来从archives取出我们想要的title,link和desc,保存到items.py里,使用到正则表达式,在Scrapy中是使用一种基于XPath和CSS的表达式机制Scrapy Selectors。
Selector是一个选择器,它有四个基本的方法:
xpath():传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
css():传入CSS表达式,返回该表达式所对应的所有节点的selector list列表
extract():序列化该节点为unicode字符串并返回list
re():根据传入的正则表达式对数据进行提取,返回unicode字符串list列表
接下来执行scrapy shell "http://www.nnzhp.cn/archives/887"(单引号报错),进入shell页面,如下图:
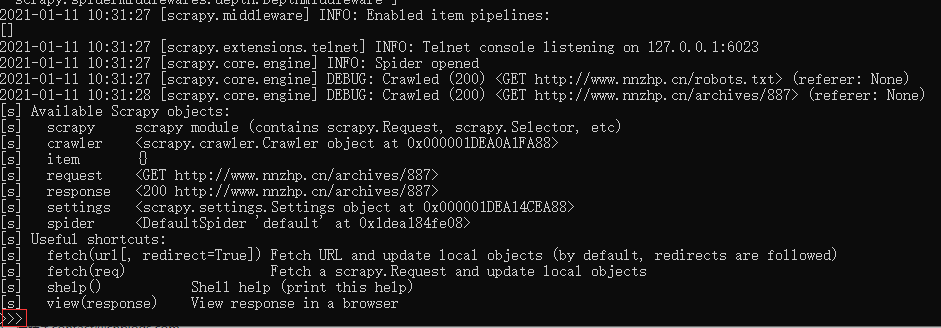
根据节点查找标题:

4、然后写代码来存储内容,代码如下图:
在test0104下执行scrapy crawl dmoz -o items.json -t json,然后在根目录下生成一个items.json文件,打开items.json文件就可以看到title,link,desc