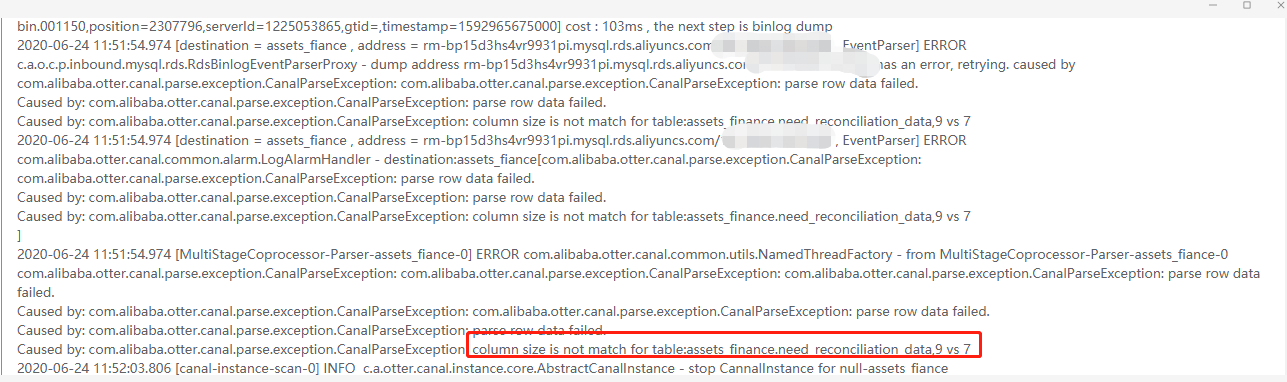
一、异常现象截图
二、解决方式:
1、背景
早期的canal版本(<=1.0.24),在处理表结构的DDL变更时采用了一种简单的策略,在内存里维护了一个当前数据库内表结构的镜像(通过desc table获取)。
这样的内存表结构镜像的维护存在问题,如果当前在处理的binlog为历史时间段T0,当前时间为T1,存在的一些异常分支情况:
- 假如在T0~T1的时间内,表结构A发生过增加列的DDL操作,那在处理T0时间段A表的binlog时,拿到的表结构为T1的镜像,就会出现列不匹配的情况. 比如之前的异常: column size is not match for table: xx , 12 vs 13
- 假如在T0~T1发生了增加 C1列、删除了C2列,此时拿到的列的总数还是和T0时保持一致,但是对应的列会错位
- 假如在T0~T1发生了drop table的DDL,此时拿表结构时会出现无法找到表的异常,一直阻塞整个binlog处理,比如not found [xx] in db
补充一下MySQL binlog的一些技术背景:
本文作者:张永清,转载请注明出处:https://www.cnblogs.com/laoqing/p/13187324.html
- MySQL的在记录DML(INSERT/UPDATE/DELETE)的binlog时,会由一个当前表结构snapshot的TableMap binlog来描述,然后跟着一条DML的binlog
- TableMap对象里,会记录一些基本信息:列的数量、列类型精度、后续DML binlog里的数据存储格式等,但唯独没有记录列名信息、列编码、列类型,这也是大众业务理解binlog的基本诉求(但MySQL binlog只做同构重放,可以不关注这些),所以canal要做的一件事就是补全对应的列信息.

ps. 针对复杂的一条update中包含多张表的更新时,大家可以观察一下Table_map的特殊情况,留待有兴趣的同学发挥
2、方案
扯了一堆的背景之后,再来看一下我们如何解决canal上一版本存在的表结构一致性的问题,这里会把我们的思考过程都记录出来,方便大家辩证的看一下方案.
思考一
解决这个问题,第一个最直接的思考:canal在订阅binlog时,尽可能保持准实时,不做延迟回溯消费. 这样的方式会有对应的优点和缺点:
- canal要做准实时解析,业务上可能有failover的需求,假如在业务处理离线时,原本canal基于内存ringBuffer的模型,会出现延迟解析,如果要解决这个问题,必须在canal store上支持了持久化存储的能力,比如实现或者转存到kafka/rocketmq等.
- canal准实时解析,如果遇到canal本身的failover,比如zookeeper挂、网络异常,出现分钟级别以上的延迟,DDL变化的概率会比较高,此时就会陷入之前一样的表结构一致性的问题
整个方案上,基本是想避开表结构的问题,在遇到一些容灾场景下一定也会遇上,不是一个技术解决的方案,废弃.
思考二
经过了第一轮辩证的思考,基本确定想通过迂回的方式,简单绕过一致性的问题不是正解,所以这次的思考主要就是如何正面解决一致性的问题. 基本思路:基于binlog中DDL的变化,来动态维护一份表结构,比如DDL中增加一个列,在本地表结构中也动态增加一列,解析binlog时都从本地表结构中获取
实现方案:
- 本地表结构的维护,每个canal进程可以带着一个二进制的MySQL版本,把收到的每条DDL,在本地MySQL中进行重放,从而维护一个本地的MySQL表结构
- 每个canal第一次订阅或者回滚到指定位点,刚启动时需要拉取一份表结构基线,存入本地表结构MySQL库,然后在步骤1的方案上维护一个增量DDL.
整个方案上,可以绝大部分的解决DDL的问题,但也存在一些缺点:
- 每个canal进程,维护一个隔离的MySQL实例。不论是资源成本、运维成本上都有一些瑕疵,更像是一个工程的解决方案,不是一个开源+技术产品的解决方案
- 位点如果存在相对高频的位点回溯,每次都需要重新做表结构基线,做表结构基线也会概率遇上表结构一致性问题
思考三
有了之前的两次思考,思路基本明确了,在一次偶然的机会中和alibaba Druid的作者高铁,交流中得到了一些灵感,是否可以基于Druid对DDL的支持能力,来构建一份动态的表结构.
大致思路:
- 首先准备一份表结构基线数据,每条建表语句传入druid的SchemaRepository.console(),构建一份druid的初始表结构
- 之后在收到每条DDL变更时,把alter table add/drop column等,全部传递给druid,由druid识别ddl语句并在内存里执行具体的add/drop column的行为,维护一份最终的表结构
- 定时把druid的内存表结构,做一份checkpoint,之后的位点回溯,可以是checkpoint + 增量DDL重放的方式来快速构建任意时间点的表结构
最终方案示意图

- C0为初始化的checkpoint,拿到所有满足订阅条件的表结构
- D1为binlog日志流中的DDL,它会有时间戳T的标签,用于记录不同D1/D2之间的先后关系
- 定时产生一个checkpoint cm,并保存对应的checkpoint时间戳
- 用户如果回溯位点到任意时间点Tx,对应的表结构就是 checkpoint + ddl增量的结合
接口设计:
public interface TableMetaTSDB { /** * 初始化 */ public boolean init(String destination); /** * 获取当前的表结构 */ public TableMeta find(String schema, String table); /** * 添加ddl到时间表结构库中 */ public boolean apply(BinlogPosition position, String schema, String ddl, String extra); /** * 回滚到指定位点的表结构 */ public boolean rollback(BinlogPosition position); /** * 生成快照内容 */ public Map<String/* schema */, String> snapshot(); }

- 依赖了alibaba druid的DDL SQL解析能力,维护一份MemoryTableMeta,实时内存表结构
- 依赖DAO持久化存储的能力,记录WAL结果(每条DDL) + checkpoint
持久化存储的思考:
- 本地嵌入式实现(H2):提供最小化的依赖,完成时序表结构管理的能力。基于磁盘的模式,可以结合存储计算分离的技术,canal failover之后只要在另一个计算节点上拉起,并加载云盘上的DB数据,做到多机冷备。
- 中心管控存储实现(MySQL): 一般结合于规模化的管控系统,允许将DDL数据录入到中心MySQL进行统一运维。
canal中如何使用
- 打开conf/canal.properties,选择持久化存储的方案,默认为H2
canal.instance.tsdb.spring.xml=classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml=classpath:spring/tsdb/mysql-tsdb.xml
- 打开instance下的instance.properties,修改对应的参数
| 参数名 | 默认值 | 描述 |
|---|---|---|
| canal.instance.tsdb.enable | true | 是否开启时序表结构的能力 |
| canal.instance.tsdb.dir | ${canal.file.data.dir:../conf}/${canal.instance.destination:} | 默认存储到conf/$instance |
| canal.instance.tsdb.url | jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL; | jdbc链接串 |
| canal.instance.tsdb.dbUsername | canal | jdbc用户名,因为有自动创建表的能力,所以对该用户需要有create table的权限 |
| canal.instance.tsdb.dbPassword | canal | jdbc密码 |
例子:
# table meta tsdb info
canal.instance.tsdb.enable=true
canal.instance.tsdb.dir=${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url=jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
canal.instance.tsdb.dbUsername=canal
canal.instance.tsdb.dbPassword=canal三、最后
目前canal 1.0.26最新版已经默认开启了时序表结构的能力,just have fun !