阅读目录
函数名的本质
函数名本质上就是函数的内存地址
1.可以被引用


def func():
print('in func')
f = func
print(f)
2.可以被当作容器类型的元素
def f1():
print('f1')
def f2():
print('f2')
def f3():
print('f3')
l = [f1,f2,f3]
d = {'f1':f1,'f2':f2,'f3':f3}
调用
3.可以当作函数的参数和返回值
第一类对象(first-class object)指
1.可在运行期创建
2.可用作函数参数或返回值
3.可存入变量的实体。
*不明白?那就记住一句话,就当普通变量用
闭包函数
def func(): name = 'eva' def inner(): print(name)
闭包函数定义:
内部函数包含对外部作用域而非全剧作用域名字的引用,该内部函数称为闭包函数
#函数内部定义的函数称为内部函数
由于有了作用域的关系,我们就不能拿到函数内部的变量和函数了。如果我们就是想拿怎么办呢?返回呀!
我们都知道函数内的变量我们要想在函数外部用,可以直接返回这个变量,那么如果我们想在函数外部调用函数内部的函数呢?
是不是直接就把这个函数的名字返回就好了?
def func(): name = 'eva' def inner(): print(name) return innerf = func()
f()
判断闭包函数的方法__closure__
#输出的__closure__有cell元素 :是闭包函数 def func(): name = 'eva' def inner(): print(name) print(inner.__closure__) return innerf = func()
f()#输出的__closure__为None :不是闭包函数
name = 'egon'
def func2():
def inner():
print(name)
print(inner.closure)
return innerf2 = func2()
f2()
装饰器函数
装饰器是python中一个非常又特色的知识点。它在不改变原函数的调用方式的情况下,完成了给函数前后添加功能的效果。
比如我们已经写好了一个函数,需要计算这个函数的执行时间,这个时候该怎么办呢?
import time def timer(func): start = time.time() func() print(time.time() - start)def func1():
print('in func1')def func2():
print('in func2')timer(func1)
timer(func2)
这样看起来是不是简单多啦?不管我们写了多少个函数都可以调用这个计时函数来计算函数的执行时间了。。。尽管现在修改成本已经变得很小很小了,但是对于同事来说还是改变了这个函数的调用方式,假如某同事因为相信你,在他的代码里用你的方法用了2w多次,那他修改完代码你们友谊的小船也就彻底地翻了。
你要做的就是,让你的同事依然调用func1,但是能实现调用timer方法的效果。这个时候就用到了装饰器。
import time def timer(func): def inner(*args,**kwargs): start = time.time() re = func(*args,**kwargs) print(time.time() - start) return re return inner@timer #==> func2 = timer(func2)
def func2(a):
print('in func2 and get a:%s'%(a))
return 'fun2 over'func2('aaaaaa')
print(func2('aaaaaa'))
刚刚那个装饰器已经非常完美了,但是正常我们情况下查看函数的一些信息的方法在此处都会失效
def index(): '''这是一个主页信息''' print('from index')print(index.doc) #查看函数注释的方法
print(index.name) #查看函数名的方法
为了不让他们失效,我们还要在装饰器上加上一点来完善它:
from functools import wrapsdef deco(func):
#@wraps(func) #加在最内层函数正上方
def wrapper(args,**kwargs):
return func(args,**kwargs)
return wrapper@deco
def index():
'''哈哈哈哈'''
print('from index')print(index.doc)
print(index.name)
1.对扩展是开放的
为什么要对扩展开放呢?
我们说,任何一个程序,不可能在设计之初就已经想好了所有的功能并且未来不做任何更新和修改。所以我们必须允许代码扩展、添加新功能。
2.对修改是封闭的
为什么要对修改封闭呢?
就像我们刚刚提到的,因为我们写的一个函数,很有可能已经交付给其他人使用了,如果这个时候我们对其进行了修改,很有可能影响其他已经在使用该函数的用户。
迭代器和生成器
可迭代和迭代器
dir函数可以帮我们查看一个变量能够调用的所有方法。
可以被迭代要满足的要求就叫做可迭代协议。可迭代协议的定义非常简单,就是内部实现了__iter__方法。
迭代器遵循迭代器协议:必须拥有__iter__方法和__next__方法。
介绍range和for
range本身就是可迭代的
range(10000000) 当我们写range(10000000)的时候不会真的在内存中生成10000000个数字 而是当用户要用一个的时候才从range(10000000)中取一个。
那么是用什么方式来取的呢?就是利用for循环来获取的。
for循环的对象必须是一个可迭代类型,因为for循环取值的方式就是利用迭代器的取值方式来进行的。

r = range(100000) print(r) iterator = r.__iter__() print(iterator) print(iterator.__next__()) print(iterator.__next__()) print(iterator.__next__()) print(iterator.__next__()) print(iterator.__next__()) ...执行结果:
range(0, 100000)
<range_iterator object at 0x10849b9c0>
0
1
2
3
4
for循环的本质,就是把一个可迭代类型通过iter方法转换成迭代器,然后再每一次循环中使用next取值就可以了。
那么迭代器的优势是什么呢?很简单,节省内存就是迭代器最大的优势!
生成器
既然迭代器这么好,那么我们自己可不可以写一个迭代器呢?当然可以啦,python专门为我们提供了自定义迭代器的语法,并且我们自己写的迭代器还有一个新名字,叫做生成器。
Python中提供的生成器:
1.生成器函数:常规函数定义,但是,使用yield语句而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次重它离开的地方继续执行
2.生成器表达式:类似于列表推导,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
初识生成器
一个包含yield关键字的函数就是一个生成器函数。yield可以为我们从函数中返回值,但是yield又不同于return,return的执行意味着程序的结束,调用生成器函数不会得到返回的具体的值,而是得到一个可迭代的对象。每一次获取这个可迭代对象的值,就能推动函数的执行,获取新的返回值。直到函数执行结束。
import time def genrator_fun1(): a = 1 print('现在定义了a变量') yield a b = 2 print('现在又定义了b变量') yield bg1 = genrator_fun1()
print('g1 : ',g1) #打印g1可以发现g1就是一个生成器
print('-'*20) #我是华丽的分割线
print(next(g1))
time.sleep(1) #sleep一秒看清执行过程
print(next(g1))
生成器有什么好处呢?就是不会一下子在内存中生成太多数据
假如我想让工厂给学生做校服,生产2000000件衣服,我和工厂一说,工厂应该是先答应下来,然后再去生产,我可以一件一件的要,也可以根据学生一批一批的找工厂拿。
而不能是一说要生产2000000件衣服,工厂就先去做生产2000000件衣服,等回来做好了,学生都毕业了。。。
#初识生成器二def produce():
"""生产衣服"""
for i in range(2000000):
yield "生产了第%s件衣服"%iproduct_g = produce()
print(product_g.next()) #要一件衣服
print(product_g.next()) #再要一件衣服
print(product_g.next()) #再要一件衣服
num = 0
for i in product_g: #要一批衣服,比如5件
print(i)
num +=1
if num == 5:
break#到这里我们找工厂拿了8件衣服,我一共让我的生产函数(也就是produce生成器函数)生产2000000件衣服。
剩下的还有很多衣服,我们可以一直拿,也可以放着等想拿的时候再拿
实际应用
import timedef tail(filename):
f = open(filename)
f.seek(0, 2) #从文件末尾算起
while True:
line = f.readline() # 读取文件中新的文本行
if not line:
time.sleep(0.1)
continue
yield linetail_g = tail('tmp')
for line in tail_g:
print(line)
生成器表达式
#老男孩由于峰哥的强势加盟很快走上了上市之路,alex思来想去决定下几个鸡蛋来报答峰哥 egg_list=['鸡蛋%s' %i for i in range(10)] #列表解析#峰哥瞅着alex下的一筐鸡蛋,捂住了鼻子,说了句:哥,你还是给我只母鸡吧,我自己回家下
laomuji=('鸡蛋%s' %i for i in range(10))#生成器表达式
print(laomuji)
print(next(laomuji)) #next本质就是调用__next__
print(laomuji.next())
print(next(laomuji))
总结:
1.把列表解析的[]换成()得到的就是生成器表达式
2.列表解析与生成器表达式都是一种便利的编程方式,只不过生成器表达式更节省内存
3.Python不但使用迭代器协议,让for循环变得更加通用。大部分内置函数,也是使用迭代器协议访问对象的。例如, sum函数是Python的内置函数,该函数使用迭代器协议访问对象,而生成器实现了迭代器协议,所以,我们可以直接这样计算一系列值的和:
sum(x ** 2 for x in range(4))
而不用多此一举的先构造一个列表:
sum([x ** 2 for x in range(4)])
更多精彩请见——迭代器生成器专题:https://www.cnblogs.com/l-hf/p/11532243.html
ƒ
匿名函数
匿名函数:为了解决那些功能很简单的需求而设计的一句话函数
#这段代码 def calc(n): return n**n print(calc(10))#换成匿名函数
calc = lambda n:n**n
print(calc(10))
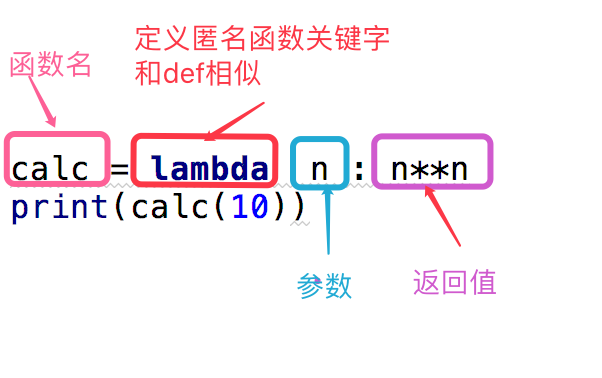
上面是我们对calc这个匿名函数的分析,下面给出了一个关于匿名函数格式的说明
函数名 = lambda 参数 :返回值参数可以有多个,用逗号隔开
匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值
返回值和正常的函数一样可以是任意数据类型
我们可以看出,匿名函数并不是真的不能有名字。
匿名函数的调用和正常的调用也没有什么分别。 就是 函数名(参数) 就可以了~~~
练一练:
请把以下函数变成匿名函数
def add(x,y):
return x+y
递归函数
https://www.cnblogs.com/l-hf/p/11532281.html
内置函数
https://www.cnblogs.com/l-hf/p/11532309.html
练习
1、整理装饰器的形成过程,背诵装饰器的固定格式
2、编写装饰器,在每次执行被装饰函数之前打印一句’每次执行被装饰函数之前都得先经过这里,这里根据需求添加代码’
3、编写装饰器,在每次执行被装饰函数之后打印一句’每次执行完被装饰函数之后都得先经过这里,这里根据需求添加代码’
4、编写装饰器,在每次执行被装饰函数之前让用户输入用户名,密码,给用户三次机会,登录成功之后,才能访问该函数.
5、编写装饰器,为多个函数加上认证的功能(用户的账号密码来源于文件,只支持单用户的账号密码,给用户三次机会),要求登录成功一次,后续的函数都无需再输入用户名和密码
6、编写装饰器,为多个函数加上认证的功能(用户的账号密码来源于文件,可支持多账号密码),要求登录成功一次(给三次机会),后续的函数都无需再输入用户名和密码。
7、给每个函数写一个记录日志的功能,
功能要求:每一次调用函数之前,要将函数名称,时间节点记录到log的日志中。
所需模块:
import time
struct_time = time.localtime()
print(time.strftime("%Y-%m-%d %H:%M:%S",struct_time))
8、lambda是什么?试着把简单的需求写成lambda函数。
作业
模拟博客园登录:
1),启动程序,首页面应该显示成如下格式:
欢迎来到博客园首页 1:请登录 2:请注册 3:文章页面 4:日记页面 5:评论页面 6:收藏页面 7:注销 8:退出程序
2),用户输入选项,3~6选项必须在用户登录成功之后,才能访问成功。
3),用户选择登录,用户名密码从register文件中读取验证,三次机会,没成功则结束整个程序运行,成功之后,可以选择访问3~6项,访问页面之前,必须要在log文件中打印日志,日志格式为-->用户:xx 在xx年xx月xx日 执行了 %s函数,访问页面时,页面内容为:欢迎xx用户访问评论(文章,日记,收藏)页面
4),如果用户没有注册,则可以选择注册,注册成功之后,可以自动完成登录,然后进入首页选择。
5),注销用户是指注销用户的登录状态,使其在访问任何页面时,必须重新登录。
6),退出程序为结束整个程序运行。