本篇主要是通过对豆瓣图书《平凡的世界》短评进行抓取并进行分析,并用snowNLP对其进行情感分析。
用到的模块有snowNLP,是一个python库,用来进行情感分析。
1.抓取数据
我们把抓取到的数据存储到sqlite,先建表,结构如下:
CREATE TABLE comment( id integer PRIMARY KEY autoincrement NOT NULL, commentator VARCHAR(50) NOT NULL, star INTEGER NOT NULL, time VARCHAR(50) NOT NULL, content TEXT NOT NULL );
然后写python代码进行抓取,如下:
import sys from os import path import time import urllib3 import requests import numpy as np import sqlite3 from bs4 import BeautifulSoup from urllib import parse from snownlp import SnowNLP import matplotlib.pyplot as plt import jieba from wordcloud import WordCloud from PIL import Image headers=[{'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}, {'User-Agent':'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'}, {'User-Agent': 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)'}] def get_comment(): page_num = 0; total_num = 0; while(1): page_num +=1 url = "https://book.douban.com/subject/1200840/comments/hot?p="+str(page_num) print(url) http = urllib3.PoolManager() time.sleep(np.random.rand()*5) try: r = http.request("GET", url, headers=headers[page_num%len(headers)]) plain_text = r.data.decode() print(plain_text) except Exception as e: print(e) continue soup = BeautifulSoup(plain_text, features="lxml") ligroup = soup.find_all("li", class_="comment-item") for item in ligroup: try: commentator = item.find("div", class_="avatar").a.get("title") spanlists = list(item.find("div", class_="comment").find("span", class_="comment-info")) while " " in spanlists: spanlists.remove(" ") if (len(spanlists) == 3) : stars = spanlists[1].get("title") stars = switch_case(stars) commenttime = spanlists[2].string else: stars = 0 commenttime = spanlists[1].string content = item.find("span", class_="short").get_text() add_comment(commentator, stars, commenttime, content) except Exception as e: print(e) continue page_num+=1 if page_num > 999: break def switch_case(value): switcher = { "力荐":5, "推荐":4, "还行":3, "较差":2, "很差":1 } return switcher.get(value, 0) def add_comment(commentator, star, time, content): conn = sqlite3.connect("spider.db") cursor = conn.cursor() cursor.execute("insert into comment values (null, ?, ?, ?, ?)", (commentator, star, time, content)) cursor.close() conn.commit() conn.close()
抓取完之后可以在表中看到数据
sqlite> select count(1) from comment; 8302 sqlite> select star,count(1) from comment group by star; 0|1359 1|58 2|133 3|643 4|1875 5|4234 sqlite> select * from comment order by id desc limit 5; 8302|燊栎|4|2014-11-19|经典中的经典 8301|Jerryhere|4|2016-03-08|平凡中的不平凡 8300|麦田睡觉者|5|2012-08-12|这部小说是我上大学看的第一本小说,它带给我的震撼是无与伦比的。彻底将我从高中时看的那些yy小说里震醒。同时,它真的是一部非常好看的小说,平凡的世界里不平凡的人生,生命总是充满苦痛伤悲,这些苦难让生命愈发的沉重厚实 8299|朔望|0|2013-07-29|人生就是如此平凡 8298|mindinthesky|0|2012-09-17|不错,中国就是这样子
2.简单分析
数据抓取完了之后我们进行简单分析,看下各个星的占比
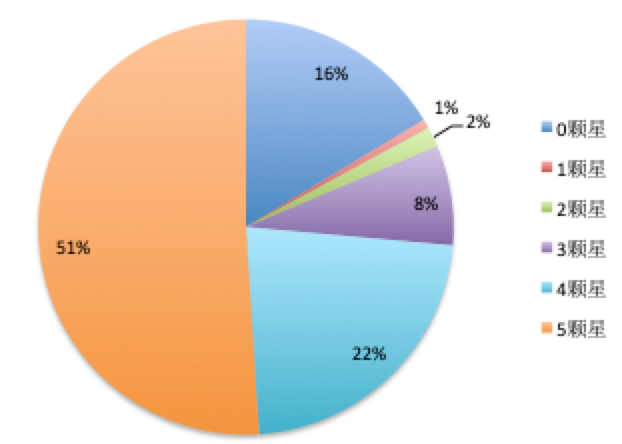
然后在把所有的comment导到文件中,进行词云分析
导出如下:
>sqlite3 -header -csv spider.db "select content from comment;" > commentall.csv
完了就会在当前目录下生成一个commentall.csv的文件
然后可以对其词云分析,代码如下:
def make_cloud(): text = open('commentall.txt', 'r', encoding='utf-8').read() cut_text = jieba.cut(text) result = " ".join(cut_text) wc = WordCloud( font_path='Deng.ttf', #字体路劲 background_color='white', #背景颜色 width=2000, height=1200, max_font_size=100, #字体大小 min_font_size=10, mask=plt.imread('timg.jpeg'), #背景图片 max_words=1000 ) wc.generate(result) wc.to_file('jielun.png') #图片保存 plt.figure('jielun') #图片显示的名字 plt.imshow(wc) plt.axis('off') #关闭坐标 plt.show()
分析完之后的图片输出是下图:

3.情感分析
我们从打的五星和一星能清楚的看到情感,但是对零星的就不太好判断,现在主要是用snowNLP对零星的做情感分析。要想分析,就先得训练,因为目前的是针对电商的评论,不适合现在的场景,怎么训练呢?
首先,我们把5颗星的评论导出存为pos.txt,作为积极的评论,把1颗星的评论导出存为neg.txt作为消极的评论;
然后,利用pos.txt和neg.txt进行训练
最后,在利用训练完的模型对0颗星的进行分析
好了,开始吧
首先导出
>sqlite3 -header -csv spider.db "select conent from comment where star = 5 limit 100;" > pos.csv >sqlite3 -header -csv spider.db "select conent from comment where star = 1 limit 100;" > neg.csv
然后找到snownlp的安装路径,如下方法:
kumufengchunMacBook-Pro:douban kumufengchun$ python Python 3.6.4 (default, Jun 6 2019, 17:59:50) [GCC 4.2.1 Compatible Apple LLVM 10.0.0 (clang-1000.10.44.4)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import snownlp >>> snownlp <module 'snownlp' from '/Users/kumufengchun/.pyenv/versions/3.6.4/lib/python3.6/site-packages/snownlp/__init__.py'>
找到了之后,把刚才的pos.scv和neg.csv拷贝到
/Users/kumufengchun/.pyenv/versions/3.6.4/lib/python3.6/site-packages/snownlp/sentiment/下边的pos.txt和neg.txt,为了保持名字一致,我们可以把之前的csv后缀的改为txt
然后开始用刚才导出的数据进行训练,训练完之后的输出保存为commentsentiment.marshal
from snownlp import sentiment sentiment.train('neg.txt', 'pos.txt') sentiment.save('commentsentiment.marshal')
然后把训练完输出的文件,在init文件中修改,文件训练完之后输出的是commentsentiment.marshal.3,后缀3是版本的意思,不用管他,在引用的时候不要加3,否则会报错,修改代码如下:
/Users/kumufengchun/.pyenv/versions/3.6.4/lib/python3.6/site-packages/snownlp/sentiment/__init__.py
data_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'commentsentiment.marshal')
好了,训练完之后,我们可以进行简单的测试
from snownlp import SnowNLP str = "好很好" s = SnowNLP(str) print(s.words) print(s.tags) print(s.sentiments)
输出如下:
['好', '很', '好'] <zip object at 0x124963588> 0.6088772592136402
4.用训练的模型进行情感分析
代码如下:
def get_comment_bypage(offset, limit): conn = sqlite3.connect("spider.db") cursor = conn.cursor() cursor.execute('select content from comment where star=0 limit ?,?', (offset, limit)) values = cursor.fetchall() cursor.close() conn.close() return values def analyse_sentiment(): offset = 0 limit = 50 commentcounts = {} while (offset < 1400): comments = get_comment_bypage(offset, limit) for comment in comments: s = SnowNLP(''.join(comment)) print(s.sentiments) sentiment = round(s.sentiments, 2) if sentiment in commentcounts: commentcounts[sentiment] += 1 else: commentcounts[sentiment] = 1 offset+=limit print(commentcounts) return commentcounts
然后我们把所有的输出做个图如下:
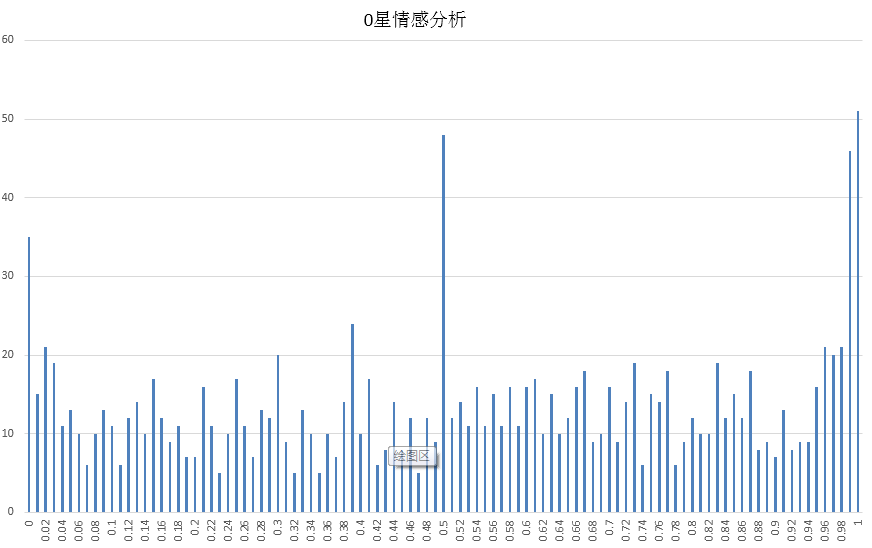
可以看到每个输出所占的数量,如何判断是积极还是消极呢,一般采取0.3,大于0.3的为积极,否则为消极,也可以把之前的数据都跑一遍,定义个区间。
完整的代码如下:
import sys from os import path import time import urllib3 import requests import numpy as np import sqlite3 from bs4 import BeautifulSoup from urllib import parse from snownlp import SnowNLP import matplotlib.pyplot as plt import jieba from wordcloud import WordCloud from PIL import Image headers=[{'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}, {'User-Agent':'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.12 Safari/535.11'}, {'User-Agent': 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Trident/6.0)'}] def get_comment(): page_num = 0; total_num = 0; while(1): page_num +=1 url = "https://book.douban.com/subject/1200840/comments/hot?p="+str(page_num) print(url) http = urllib3.PoolManager() time.sleep(np.random.rand()*5) try: r = http.request("GET", url, headers=headers[page_num%len(headers)]) plain_text = r.data.decode() print(plain_text) except Exception as e: print(e) continue soup = BeautifulSoup(plain_text, features="lxml") ligroup = soup.find_all("li", class_="comment-item") for item in ligroup: try: commentator = item.find("div", class_="avatar").a.get("title") spanlists = list(item.find("div", class_="comment").find("span", class_="comment-info")) while " " in spanlists: spanlists.remove(" ") if (len(spanlists) == 3) : stars = spanlists[1].get("title") stars = switch_case(stars) commenttime = spanlists[2].string else: stars = 0 commenttime = spanlists[1].string content = item.find("span", class_="short").get_text() add_comment(commentator, stars, commenttime, content) except Exception as e: print(e) continue page_num+=1 if page_num > 999: break def switch_case(value): switcher = { "力荐":5, "推荐":4, "还行":3, "较差":2, "很差":1 } return switcher.get(value, 0) def add_comment(commentator, star, time, content): conn = sqlite3.connect("spider.db") cursor = conn.cursor() cursor.execute("insert into comment values (null, ?, ?, ?, ?)", (commentator, star, time, content)) cursor.close() conn.commit() conn.close() def get_comment_bypage(offset, limit): conn = sqlite3.connect("spider.db") cursor = conn.cursor() cursor.execute('select content from comment where star=0 limit ?,?', (offset, limit)) values = cursor.fetchall() cursor.close() conn.close() return values def analyse_sentiment(): offset = 0 limit = 50 commentcounts = {} while (offset < 1400): comments = get_comment_bypage(offset, limit) for comment in comments: s = SnowNLP(''.join(comment)) print(s.sentiments) sentiment = round(s.sentiments, 2) if sentiment in commentcounts: commentcounts[sentiment] += 1 else: commentcounts[sentiment] = 1 offset+=limit print(commentcounts) return commentcounts def make_cloud(): text = open('commentall.txt', 'r', encoding='utf-8').read() cut_text = jieba.cut(text) result = " ".join(cut_text) wc = WordCloud( font_path='Deng.ttf', #字体路劲 background_color='white', #背景颜色 width=2000, height=1200, max_font_size=100, #字体大小 min_font_size=10, mask=plt.imread('timg.jpeg'), #背景图片 max_words=1000 ) wc.generate(result) wc.to_file('jielun.png') #图片保存 plt.figure('jielun') #图片显示的名字 plt.imshow(wc) plt.axis('off') #关闭坐标 plt.show() if __name__=='__main__': get_comment() analyse_sentiment() make_cloud()
参考资料:
https://github.com/isnowfy/snownlp
https://www.cnblogs.com/mylovelulu/p/9511369.html
https://blog.csdn.net/oYeZhou/article/details/82868683