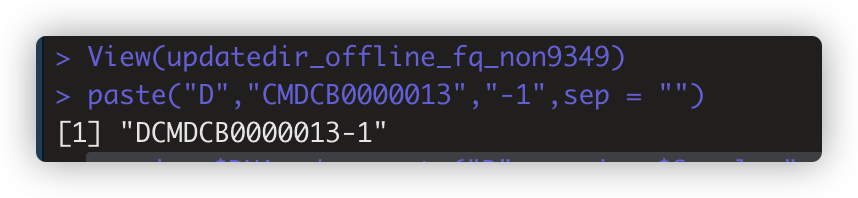
paste("D","CMDCB0000013","-1",sep = "") 拼接字符串,可以用于新增列non_json$DNAcode<-paste("D",non_json$Sample,"-1",sep="") ,当然搭配mutate用也一样
stringR 包对字符串切分 替换 匹配提取 位置提取 如下
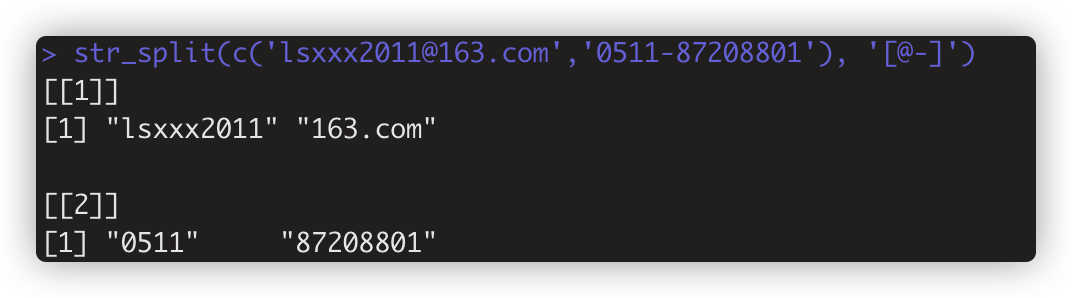
str_split(string,pattern,n=Inf,simplify=FALSE) 把字符串拆分为片 。如str_split(c('lsxxx2011@163.com','0511-87208801'), '[@-]')
string 输入字符串向量
pattern 分隔符,适用正则表达式
n 指定切成片的数量
simplify 默认FALSE,返回字符向量列表,如果是TRUE,返回字符矩阵。
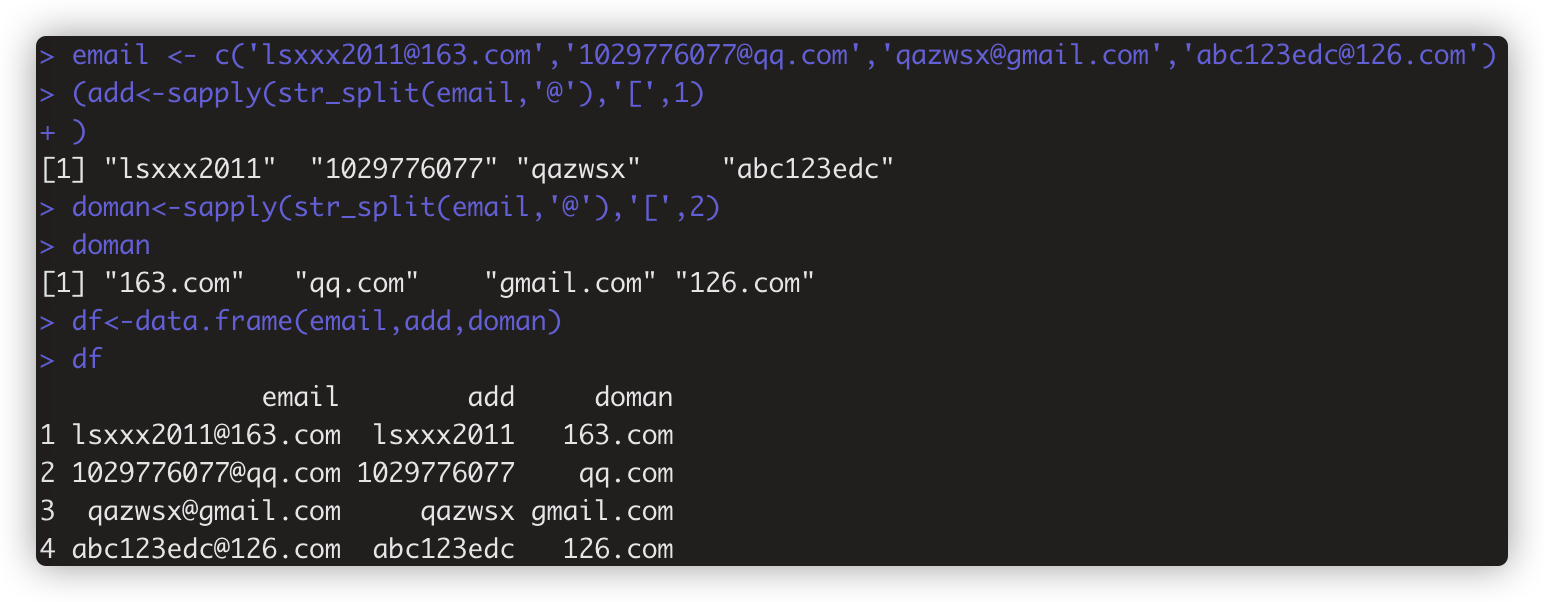
搭配sapply 使用获得向量的前/后缀 如:add<-sapply(str_split(email,'@'),'[',1)
str_replace(string,pattern,replacement) 只替换首次满足条件的子字符串
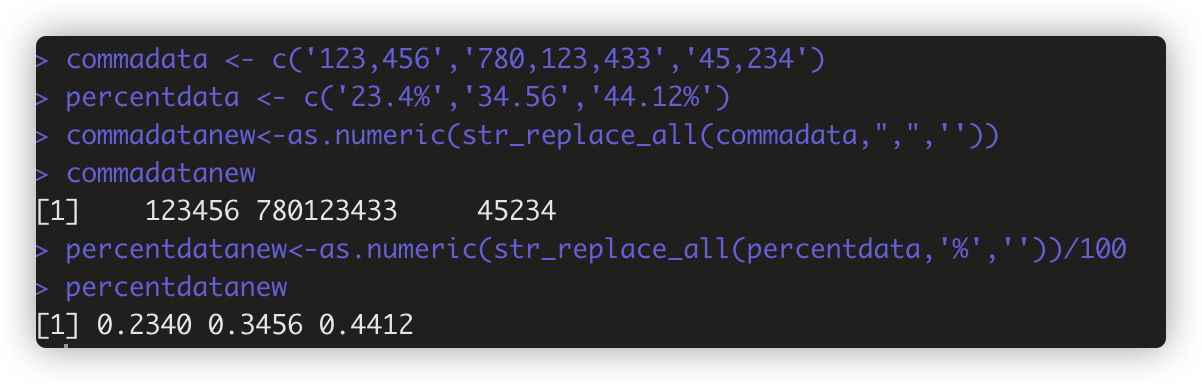
str_replace_all(string,pattern,replacement) 替换掉所有满足条件的字符串, 如 str_replace_all(commadata, ',', ''
string 字符串向量
pattern 待替换的字符串,试用正则表达式
replacement 用来替换的字符串
匹配提取字符串 str_extract(string,patterm) #只提取首次满足条件的子字符串
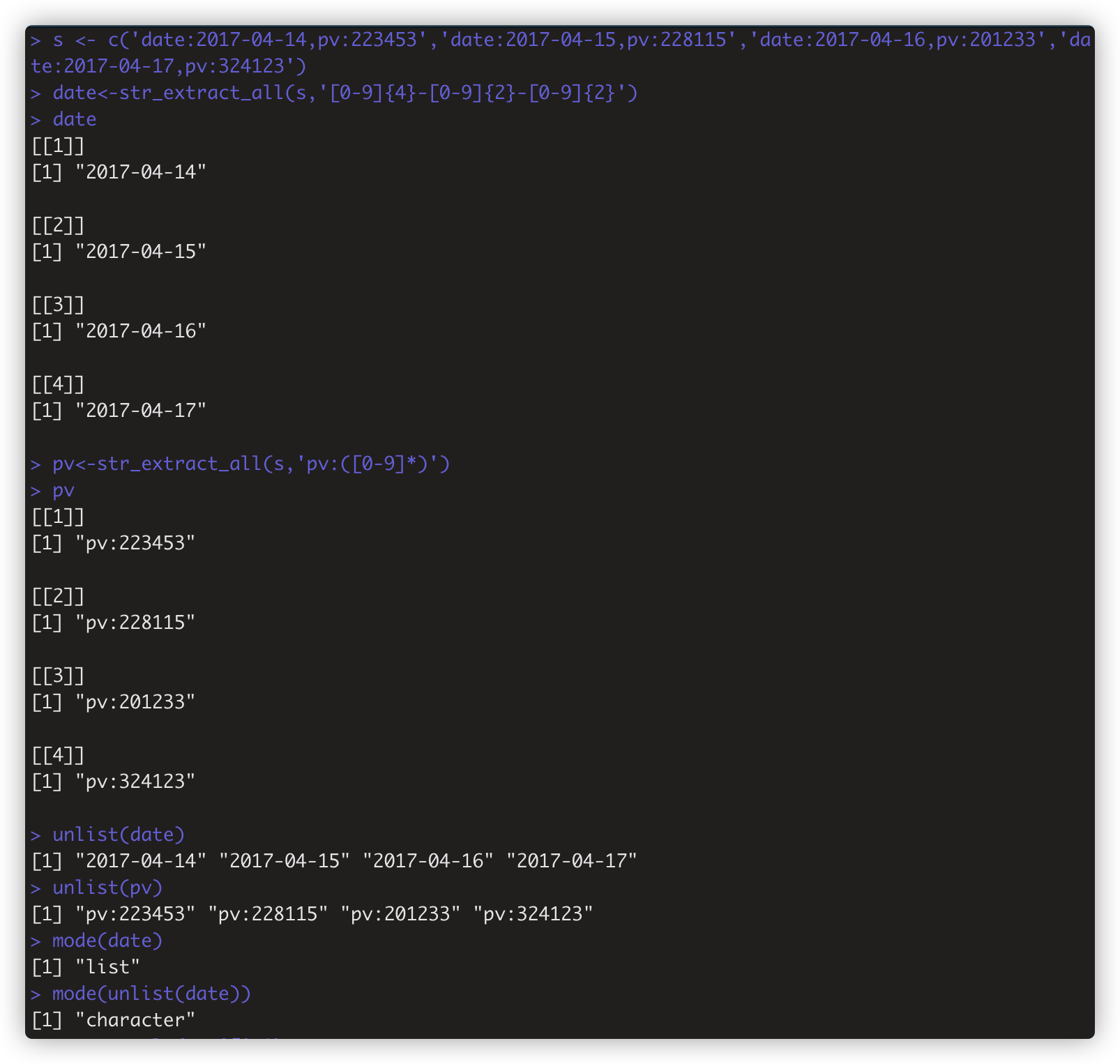
str_extract_all(string,pattern.simplify=FALSE) #提取所有满足条件的子字符串。如date<-str_extract_all(s,'[0-9]{4}-[0-9]{2}-[0-9]{2}')
参数
string 字符串向量 ;
pattern 抽取出满足条件的字符串,适用正则表达式
simplify: 默认Flase,返回列表。
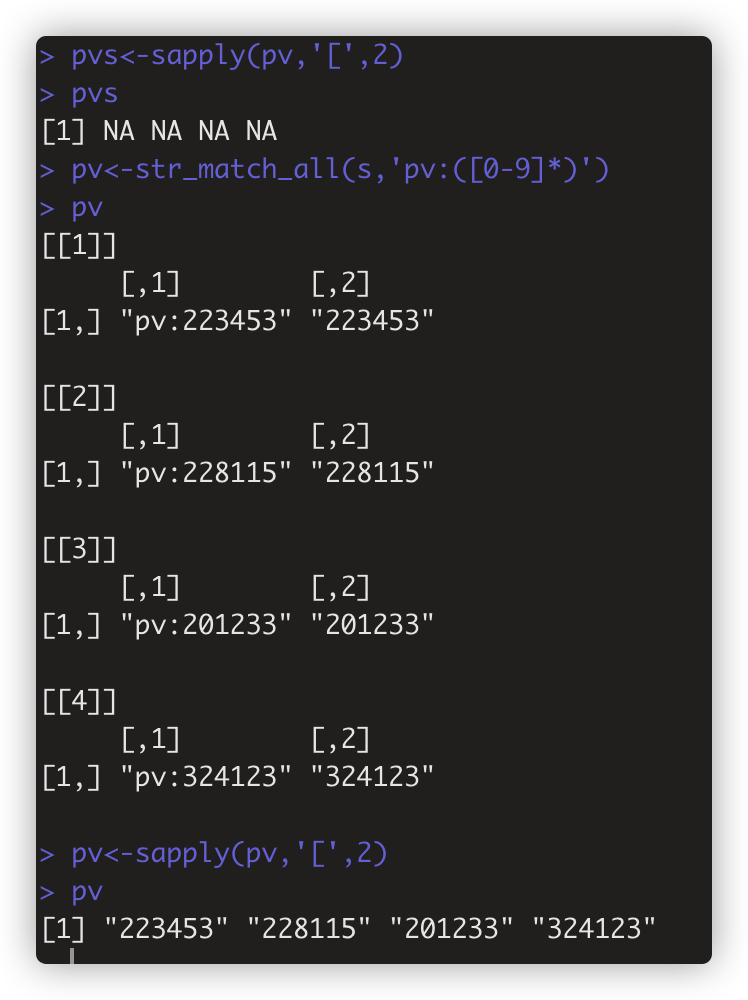
str_match(string,pattern)和str_match_all(string,pattern) 类似上面两个extract函数,但返回结果不同。如pv<-str_match_all(s,'pv:([0-9]*)')
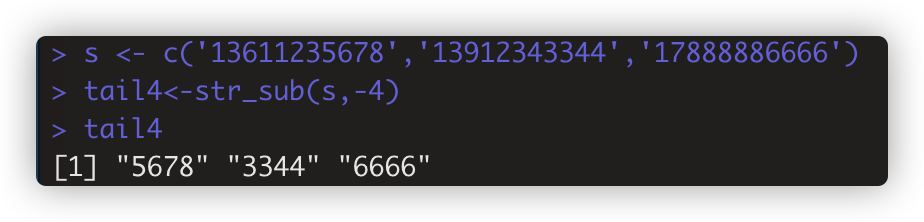
str_sub(string,start=1L,end=-1L) 按位置提取 如tail4<-str_sub(s,-4)
string 字符串向量
start 指定字符串的起始位置
end 指定字符串的终止位置
注:start 或end 为负数时,从字符串的最后一个字符串向前查找