%>% 管道函数读"then",即然后
- 把左边值发送到右边的表达式,并作为右边表达式函数的第一个参数。
- 当操作多个数据集或函数时,使用%>%会更方便,更逻辑性。
- R 其他含义的管道符号用的少,包括:
- %<>% 在%>%基础上,把右边的最终返回值返回给左边
- %T>% 把左边值传入后,不产生任何返回值(可对计算的中间过程画个图,再接着计算)
- %$% 选取左边任意变量名来操作,但左边原数据不会保存,仅保留剩下计算后的值
注意:%>%不是base自带,需要先libray(tydiverse) 。否则报: 没有"%>%"这个函数
dplyr五个核心函数:filter()筛选行 arrange()排列行 select()选择列 mutate()基于现有变量创建新变量列 summarise()计算摘要统计量
dplyr五个核心函数:
- filter()筛选行
- arrange()排列行
- select()选择列
- mutate()基于现有变量创建新变量列
- summarise()计算摘要统计量。
上面五个函数搭配group_by()可以对每个变量水平操作,高效解决数据框转换。
他们都是生成新数据框,不改变原数据。通用的参数结构:
- 第一个参数是数据框,待处理的数据集
- 变量名(不带引号),描述怎么处理
函数:
- filter()函数筛选符合条件的观测行。
-
-
- 常用到比较运算符 == != > >= < <= 搭配逻辑运算符 & | ! 。
-
- filter()多个condition时,表示“与”的关系,筛选同时满足这些条件的行。如flights%>% filter(dep_delay>120,arr_delay<=120)
- x %in% y 表示x被包含于y,返回True.
- flights %>%filter(month==11 |month==12) ,等同于flights %>%filter(month %in% c(11,12))
- between(x,left.right) 判断x是否落在 [left,right]区间内 。flights %>% filter(between(month,11,12))
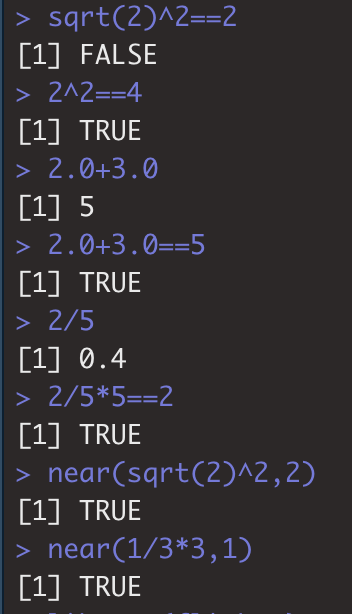
- 注意出现无理数时,计算机会存储为有限位数。因此在这无理数基础上进一步计算、做判断时会False.在比较时需要用near()来比较是否近似相等。
-
1.1 slice ()按行号筛选。对应filter()函数的row_number()参数
-
- slice(mtcars,1) #取第一行 filter(mtcats,row_number()==1)
- slice(mtcars,n()) #取最后一行 filter(mtcats,row_number()==n())
- slice(mtcars,5:n()) #取第5行到最后一行 filter(mtcars,between(row_number(),5,n()))
- mtcars %>% slice_head(n=5) #基于现有顺序筛选前5行
- mtcars %>% slice_tail(n=5) #基于现有顺序筛选后5行
- mtcars%>%slice_max(order_by = mpg,n=5) # 取出mpg最大的5行
- mtcars %>% slice_min(order_by = mpg,prop=0.05,with_ties = FALSE) # 取出mpg前0.05小的行,with_tiles=FALSE表示,mpg值相同时只取一行。
- mtcars %>% slice_sample(n=5,replace=TRUE) #对数据抽样,replace为TRUE表示可以重复取样。
2.arrange()函数对行排序。
参数: 数据集、一组作为排序依据的列名或表达式。列名多个的话,用后面的列在前面列排序基础上继续排序。
-
- 比slice_head/tail排序更精准
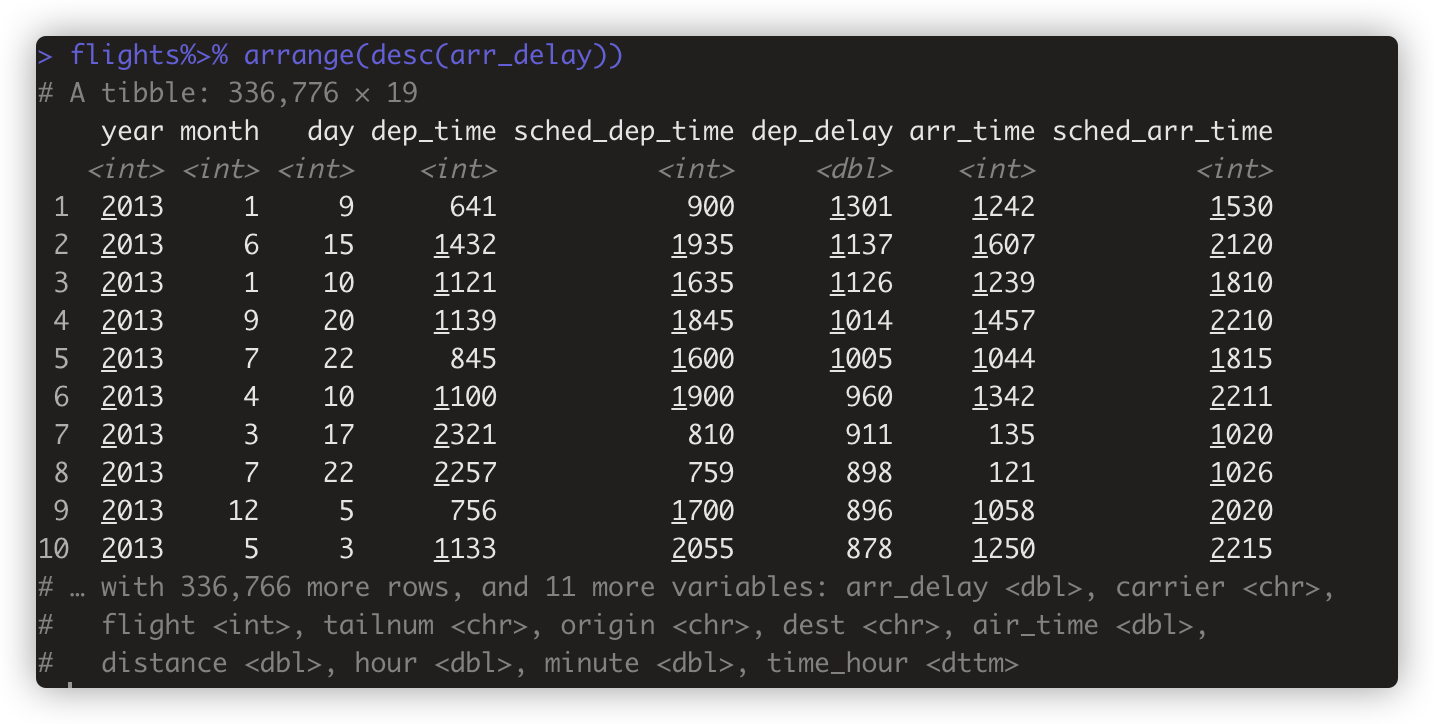
- flights %>% arrange(year,month,day) # 依次按year -> month->day 三个变量升序排序(ascend,从小到大)。
-
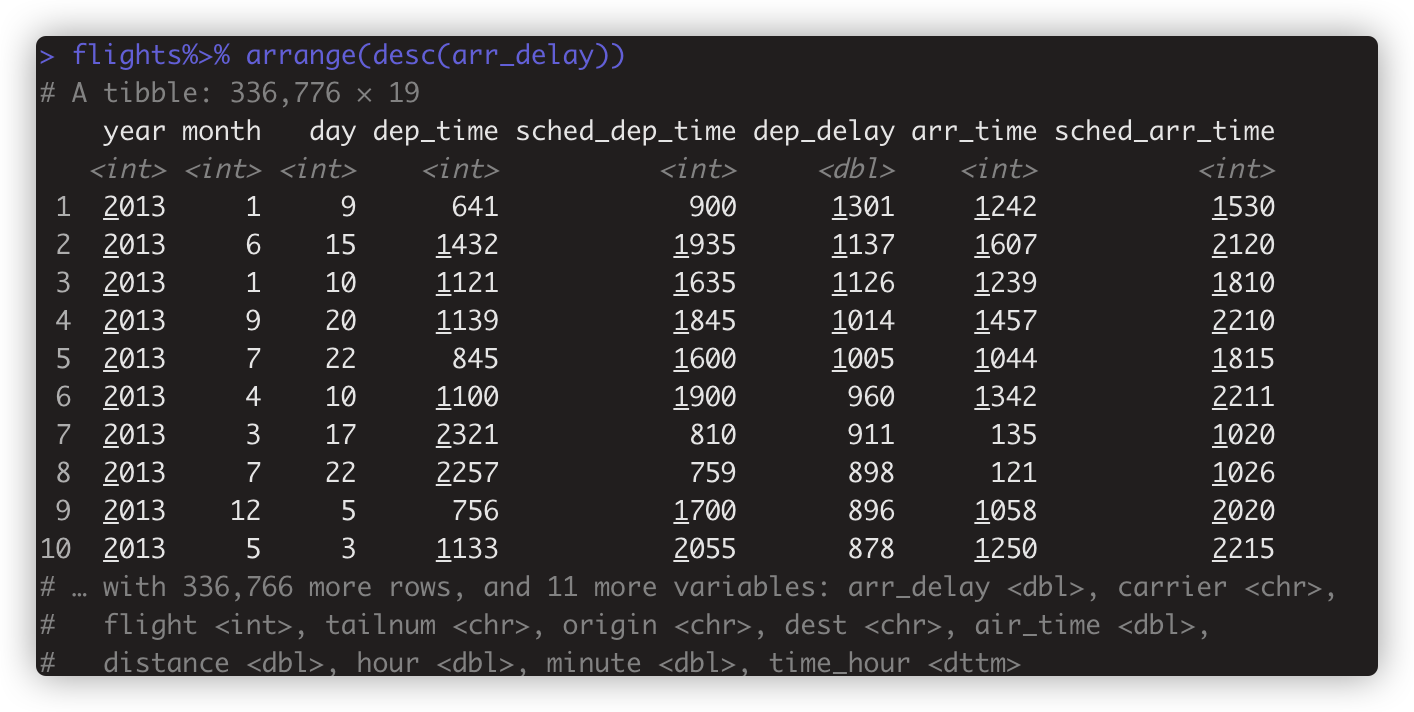
flights%>% arrange(desc(arr_delay)) #按arr_delay降序排序(descend,从大到小)
-
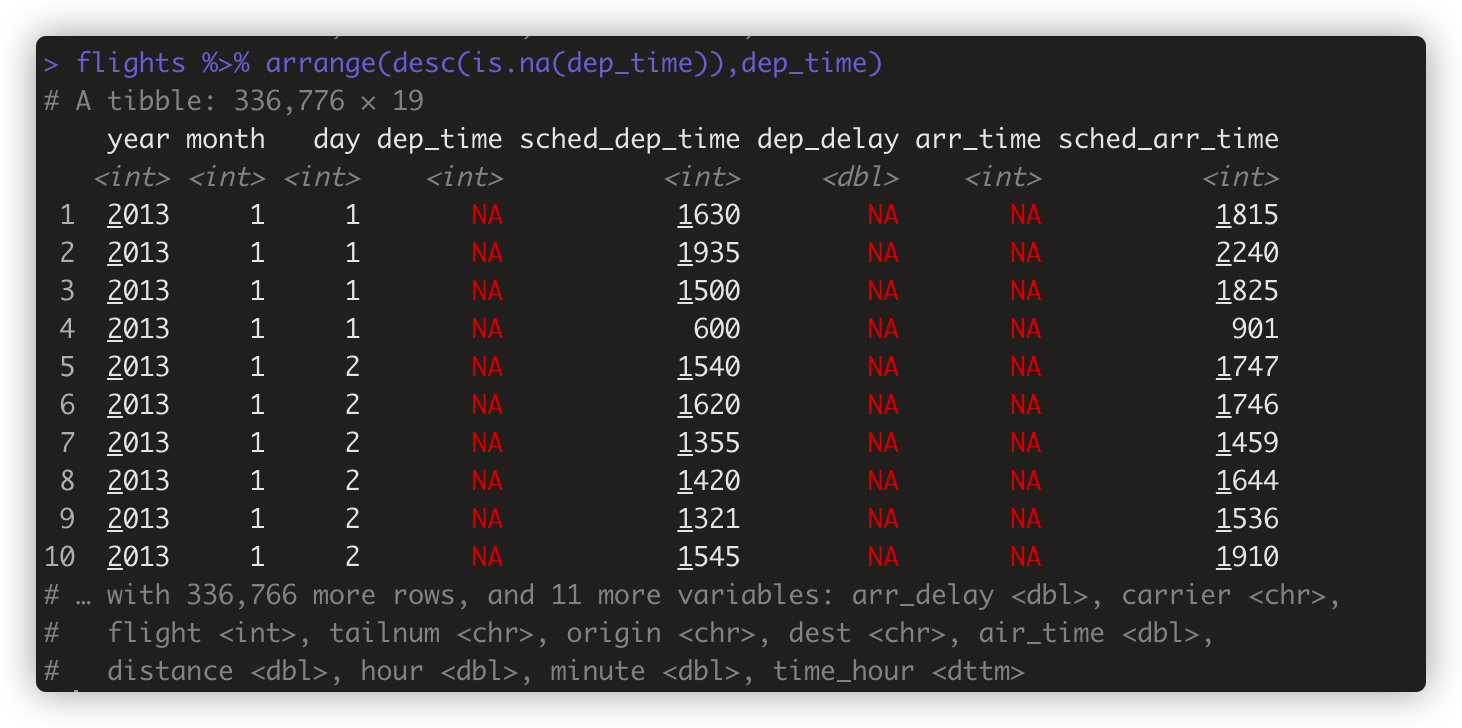
默认的缺失值NA总是排在最后 。如果想把缺失值排在前面需要 flights %>% arrange(desc(is.na(dep_time)),dep_time)
-
# is.na(dep_time) 把所有NA 转换为TRUE(1),其他数值转换为FALSE(0)。所以desc(is.na(dep_time))先排NA在前面,再把不含NA按dep_time排序。
-
- 参数是列的表达式,则按表达式取值排序。 如:
- flights %>%arrange(dep_delay**2) #按dep_delay的平方(绝对值)排序
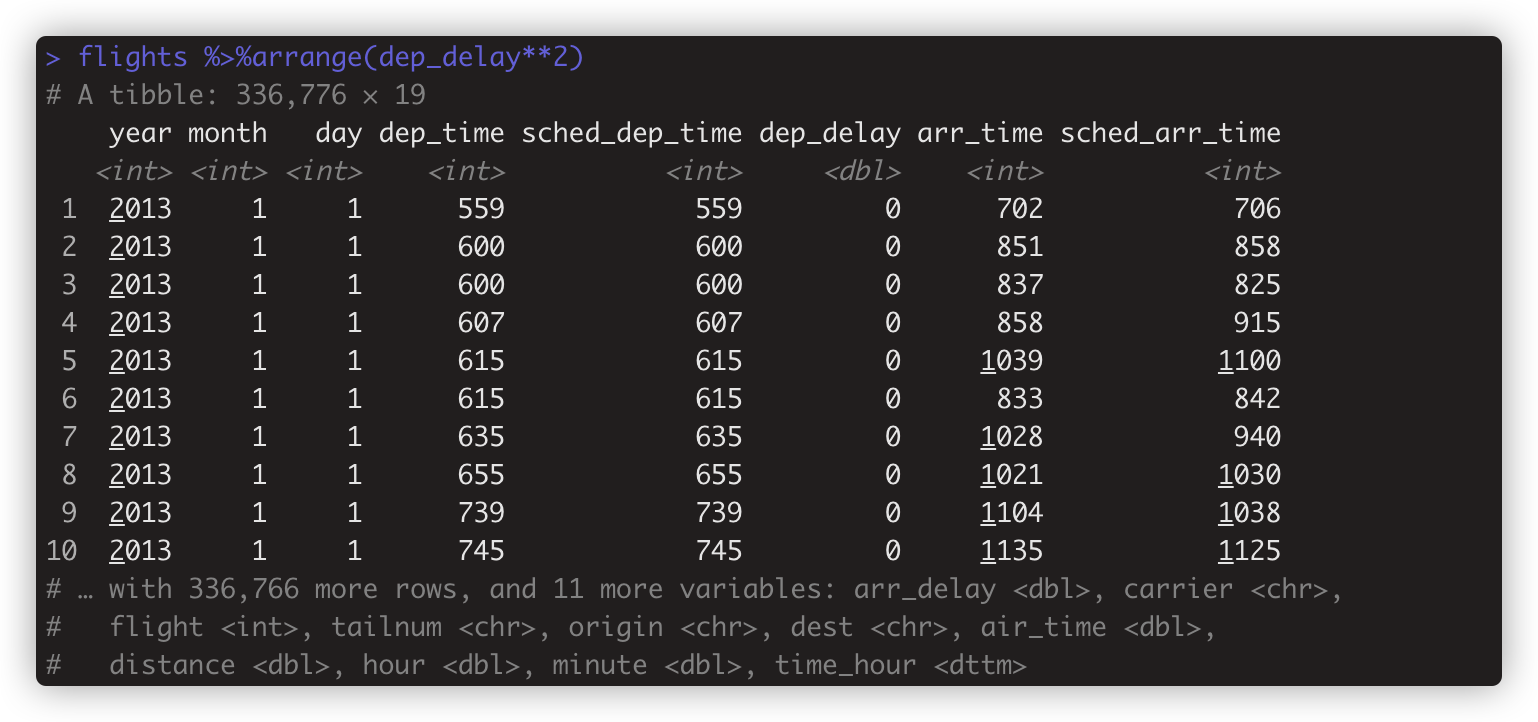
-
flights %>% arrange(desc(arr_delay+dep_delay)) 按 arr_delay+dep_delay的加和值 降序排列。
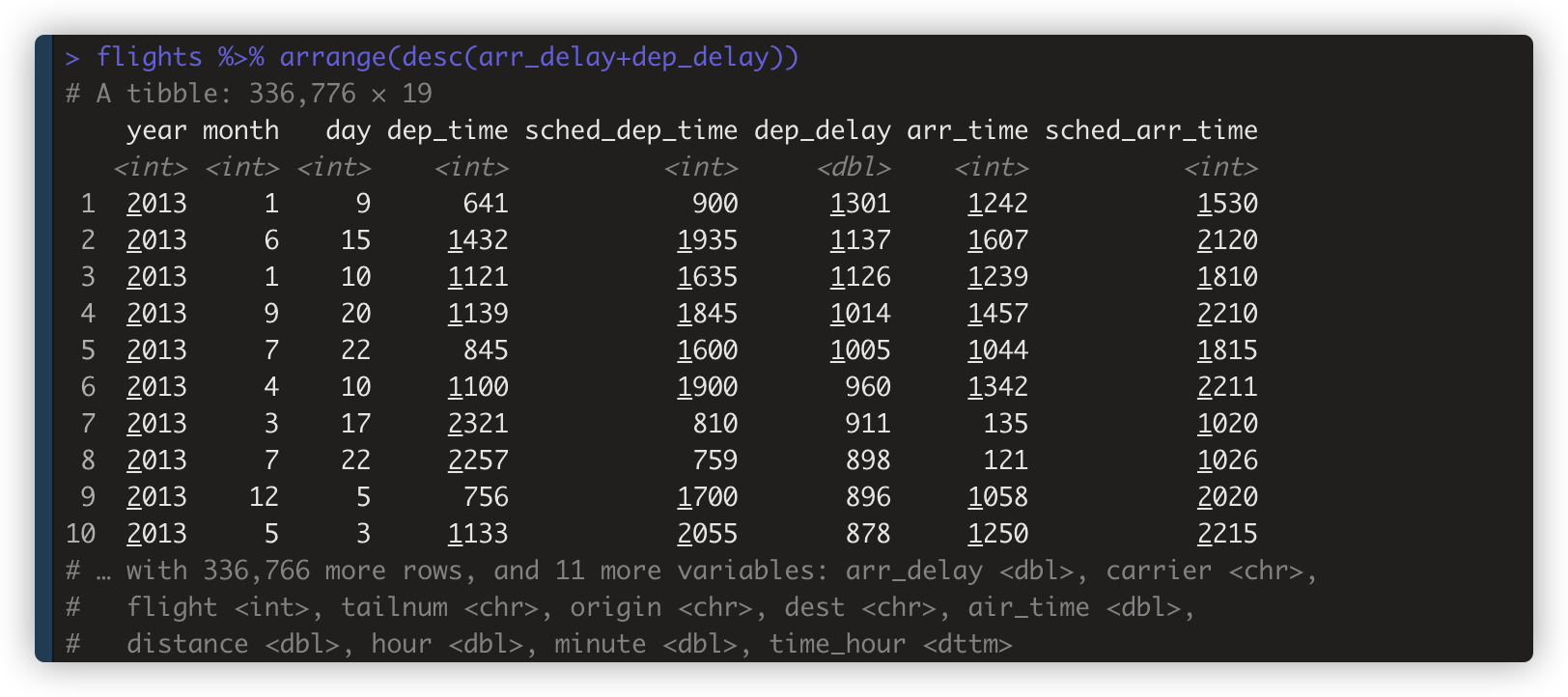
-
管道符号数据处理后赋值。如:
-
flights_start<-flights %>% select(starts_with("TIME")) ;flights_start
-
等同于(flights_start<-flights %>% select(starts_with("TIME")))
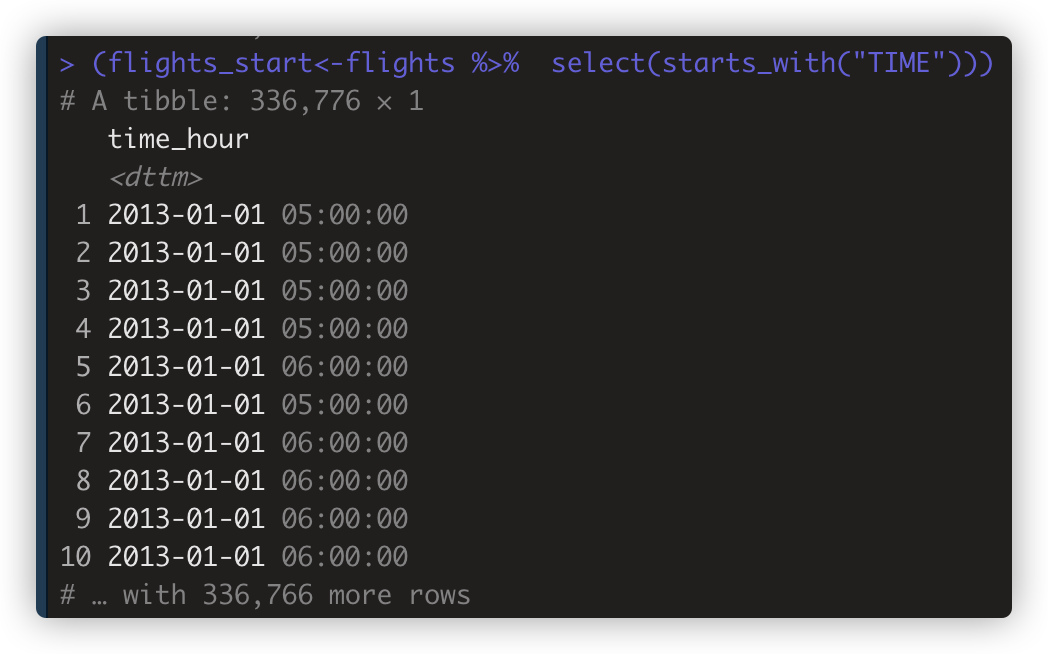
-
- 参数是列的表达式,则按表达式取值排序。 如: