一、模拟登录案例(识别验证码)
1、打码平台 - 云打码:www.yundama.com
使用步骤:
- 注册两个账户,普通用户和开发者用户;
- 登录
普通用户查看余额;
登录开发者用户;
创建一个软件:我的软件 -> 创建软件;
下载示例代码:开发者中心 -> 下载最新云打码DLL -> PythonHTTP示例下载
- 下载后解压缩,如下:



import http.client, mimetypes, urllib, json, time, requests ###################################################################### class YDMHttp: apiurl = 'http://api.yundama.com/api.php' username = '' password = '' appid = '' appkey = '' def __init__(self, username, password, appid, appkey): self.username = username self.password = password self.appid = str(appid) self.appkey = appkey def request(self, fields, files=[]): response = self.post_url(self.apiurl, fields, files) response = json.loads(response) return response def balance(self): data = {'method': 'balance', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey} response = self.request(data) if (response): if (response['ret'] and response['ret'] < 0): return response['ret'] else: return response['balance'] else: return -9001 def login(self): data = {'method': 'login', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey} response = self.request(data) if (response): if (response['ret'] and response['ret'] < 0): return response['ret'] else: return response['uid'] else: return -9001 def upload(self, filename, codetype, timeout): data = {'method': 'upload', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey, 'codetype': str(codetype), 'timeout': str(timeout)} file = {'file': filename} response = self.request(data, file) if (response): if (response['ret'] and response['ret'] < 0): return response['ret'] else: return response['cid'] else: return -9001 def result(self, cid): data = {'method': 'result', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey, 'cid': str(cid)} response = self.request(data) return response and response['text'] or '' def decode(self, filename, codetype, timeout): cid = self.upload(filename, codetype, timeout) if (cid > 0): for i in range(0, timeout): result = self.result(cid) if (result != ''): return cid, result else: time.sleep(1) return -3003, '' else: return cid, '' def report(self, cid): data = {'method': 'report', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey, 'cid': str(cid), 'flag': '0'} response = self.request(data) if (response): return response['ret'] else: return -9001 def post_url(self, url, fields, files=[]): for key in files: files[key] = open(files[key], 'rb'); res = requests.post(url, files=files, data=fields) return res.text ###################################################################### # 用户名 username = 'username' # 密码 password = 'password' # 软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得! appid = 1 # 软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得! appkey = '22cc5376925e9387a23cf797cb9ba745' # 图片文件 filename = 'getimage.jpg' # 验证码类型,# 例:1004表示4位字母数字,不同类型收费不同。请准确填写,否则影响识别率。在此查询所有类型 http://www.yundama.com/price.html codetype = 1004 # 超时时间,秒 timeout = 60 # 检查 if (username == 'username'): print('请设置好相关参数再测试') else: # 初始化 yundama = YDMHttp(username, password, appid, appkey) # 登陆云打码 uid = yundama.login(); print('uid: %s' % uid) # 查询余额 balance = yundama.balance(); print('balance: %s' % balance) # 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果 cid, result = yundama.decode(filename, codetype, timeout); print('cid: %s, result: %s' % (cid, result)) ######################################################################
2、案例一:模拟登录人人网,爬取个人中心页面数据
def getCodeData(username, pwd, codePath, codeType): username = username # 用户名(云打码普通用户用户名) password = pwd # 普通用户对应的密码 appid = 6003 # 软件代码,开发者分成必要参数。登录开发者后台【我的软件】获得! appkey = '1f4b564483ae5c907a1d34f8e2f2776c' # 通讯密钥,开发者分成必要参数。登录开发者后台【我的软件】获得! filename = codePath # 识别的图片的路径 codetype = codeType # 识别的类型,在帮助文档可查看对应验证码类型 timeout = 20 if (username == 'username'): print('请设置好相关参数再测试') else: # 初始化 yundama = YDMHttp(username, password, appid, appkey) # 登陆云打码 uid = yundama.login(); # print('uid: %s' % uid) # 查询余额 balance = yundama.balance(); # print('balance: %s' % balance) # 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果 cid, result = yundama.decode(filename, codetype, timeout); # print('cid: %s, result: %s' % (cid, result)) return result
# 人人网的模拟登陆 import requests import urllib from lxml import etree # 获取session对象 session = requests.Session() # 下载验证码图片 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } url = 'http://www.renren.com' page_text = requests.get(url=url, headers=headers).text tree = etree.HTML(page_text) code_img_url = tree.xpath('//*[@id="verifyPic_login"]/@src')[0] urllib.request.urlretrieve(url=code_img_url, filename='code.jpg') # 识别验证码图片中的数据值,2004表示4位纯汉字,其他类型代码参考云打码帮助文档 code_data = getCodeData(云打码用户名', '云打码密码', './code.jpg', 2004) # print(code_data) # code_data为识别结果 login_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2019141727367' data = { "email":"1547360919@qq.com", "icode":code_data, "origURL":"http://www.renren.com/home", "domain":"renren.com", "key_id":"1", "captcha_type":"web_login", "password":"38ce96b6b81595f845e55c1dd4e712ad6f1efe50fe31dbd5bf517b273d7c3b6e", "rkey":"07a9f1810ecf9b507634a45447a628e7", "f":"" } # 如果请求成功,产生的cookie会自动保存在session对象中 session.post(url=login_url, data=data, headers=headers) url = 'http://www.renren.com/448850039/profile' page_text = session.get(url=url, headers=headers).text with open('renren.html', 'w', encoding='utf8') as f: f.write(page_text)
3、案例二:模拟登录古诗文网
# 模拟登陆古诗文网 from lxml import etree import requests s = requests.Session() headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } login_url = 'https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx' page_text = requests.get(url=login_url, headers=headers, verify=False).text # verify=False是解决请求https协议问题,SSL错误 tree = etree.HTML(page_text) img_code_url = 'https://so.gushiwen.org' + tree.xpath('//*[@id="imgCode"]/@src')[0] # 验证码图片请求也会有session产生,因此不能使用urllib的urlretrieve方法 img_data = s.get(url=img_code_url, headers=headers, verify=False).content with open('./gs_code_img.jpg','wb') as f: f.write(img_data) # 识别验证码 code_data = getCodeData('bobo328410948', 'bobo328410948', './gs_code_img.jpg', 1004) relogin_url = 'https://so.gushiwen.org/user/login.aspx?from=http%3a%2f%2fso.gushiwen.org%2fuser%2fcollect.aspx' # 当有些参数是动态变化的时,我们可以去网页源代码中找找 data = { "__VIEWSTATE":"u+DzAnizDr8zKG7K/Q/OHyl4Kae1i0R5uxnuMk+EONOCJb5GTyGoJgnx1n/wlOx4XePU+CN5dRcmV/ptirBjyW6SyzcQqdOMuyeIbuFfEWNcUm7K00I9RH7g5gA=", "__VIEWSTATEGENERATOR":"C93BE1AE", "from":"http://so.gushiwen.org/user/collect.aspx", "email":"1547360919@qq.com", "pwd":"512abc...", "code":code_data, "denglu":"登录" } page_data = s.post(url=relogin_url, data=data, headers=headers, verify=False).text with open('./gushici.html', 'w', encoding='utf8') as f: f.write(page_data)
4、随机获取User-Agent
# 但是因其服务器不稳定,有时候获取不到,因此我们很少用 from fake_useragent import UserAgent ua = UserAgent(verify_ssl=False,use_cache_server=False).random headers = { 'User-Agent':ua }
# fake_useragent的安装方式为 pip install fake-useragent
二、selenium
参考博客:https://www.cnblogs.com/bobo-zhang/p/9685362.html
selenium是一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化操作。可用于获取动态加载的数据。
1、环境搭建
- 安装
pip install selenium
- 获取某一款浏览器的驱动程序(以谷歌浏览器为例)
谷歌浏览器驱动下载地址:http://chromedriver.storage.googleapis.com/index.html
注意:下载的驱动程序必须和浏览器版本统一,大家可以根据 http://blog.csdn.net/huilan_same/article/details/51896672 中提供的版本映射表进行对应
2、编码流程
- 导包:from selenium import webdriver
- 实例化某一款浏览器对象
- 自制定自动化操作代码
PS:本人在导包的时候遇到了如下错误:
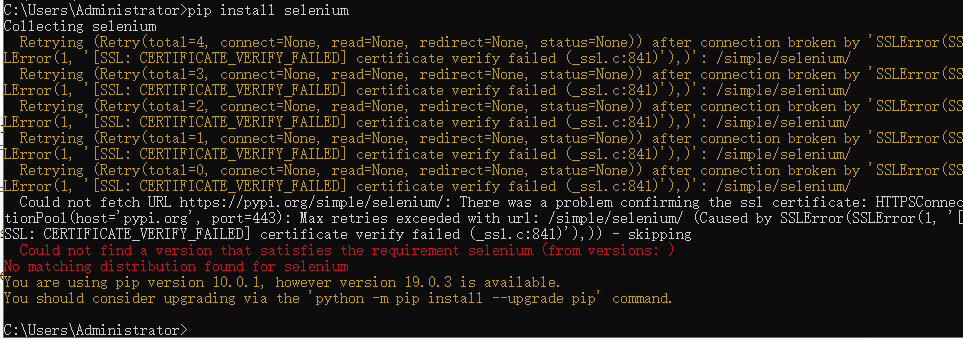
查了半天,尝试了各种都不管用,原来是我开着fiddler抓包软件了,将其关掉就可以了,[尴尬]!
3、简单示例代码
from selenium import webdriver from time import sleep bro = webdriver.Chrome(executable_path=r'D:@Lilymyprojectpachongchromedriver.exe') bro.get(url='https://www.baidu.com/') sleep(2) text_input = bro.find_element_by_id('kw') # 获取到输入框 text_input.send_keys('人民币') sleep(2) search_btn = bro.find_element_by_id('su').click() # 获取到搜索按钮,并点击 sleep(2) # 获取当前的页面源码数据 page_text = bro.page_source print(page_text) bro.quit() # 关闭浏览器
4、示例:获取豆瓣电影更多详情数据
from selenium import webdriver from time import sleep url = 'https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=' bro = webdriver.Chrome(executable_path=r'D:@Lilymyprojectpachongchromedriver.exe') bro.get(url=url) sleep(2) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') # 浏览器向下滚动一屏的距离 sleep(2) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') # 浏览器向下滚动一屏的距离 sleep(2) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') # 浏览器向下滚动一屏的距离 sleep(2) page_text = bro.page_source with open('./douban.html','w',encoding='utf8') as f: f.write(page_text) bro.quit()
5、示例:模拟登陆爬取QQ空间示例(嵌套iframe框架)
#qq空间 bro = webdriver.Chrome(executable_path=r'D:@Lilymyprojectpachongchromedriver.exe') url = 'https://qzone.qq.com/' bro.get(url=url) sleep(2) #定位到一个具体的iframe bro.switch_to.frame('login_frame') bro.find_element_by_id('switcher_plogin').click() sleep(2) bro.find_element_by_id('u').send_keys('QQ空间用户名') bro.find_element_by_id('p').send_keys('QQ空间密码') bro.find_element_by_id('login_button').click() sleep(5) page_text = bro.page_source with open('qq.html','w',encoding='utf-8') as fp: fp.write(page_text) bro.quit()
6、PhantomJs(无界面浏览器)
# 以获取豆瓣电影为例,仅仅在实例化浏览器对象时有区别,其他并无区别 from selenium import webdriver from time import sleep url = 'https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=' bro = webdriver.Chrome(executable_path=r'D:@Lilymyprojectpachongphantomjs.exe') bro.get(url=url) sleep(2) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') # 浏览器向下滚动一屏的距离 sleep(2) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') # 浏览器向下滚动一屏的距离 sleep(2) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') # 浏览器向下滚动一屏的距离 sleep(2) page_text = bro.page_source with open('./douban.html','w',encoding='utf8') as f: f.write(page_text) bro.quit()
7、谷歌无头浏览器
由于PhantomJs最近已经停止了更新和维护,所以推荐使用谷歌的无头浏览器,是一款无界面的谷歌浏览器。
示例代码如下:
#谷歌无头浏览器 from selenium.webdriver.chrome.options import Options
# 创建一个参数对象,用来控制chrome以无界面方式打开 chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') #获取豆瓣电影中更多电影详情数据 url = 'https://movie.douban.com/typerank?type_name=%E6%83%8A%E6%82%9A&type=19&interval_id=100:90&action=' bro = webdriver.Chrome(executable_path=r'D:@Lilymyprojectpachongchromedriver.exe',chrome_options=chrome_options) bro.get(url) sleep(3) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(3) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(3) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(2) page_text = bro.page_source with open('./douban.html','w',encoding='utf-8') as fp: fp.write(page_text) print(page_text) sleep(1) bro.quit()
三、线程池
1、示例:爬取梨视频热门视频
# 爬取梨视频数据 import requests import re from lxml import etree from multiprocessing.dummy import Pool import random # 实例化一个线程池对象 pool = Pool(5) url = 'https://www.pearvideo.com/category_1' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' } page_text = requests.get(url=url,headers=headers).text tree = etree.HTML(page_text) li_list = tree.xpath('//div[@id="listvideoList"]/ul/li') video_url_list = [] for li in li_list: detail_url = 'https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0] detail_page = requests.get(url=detail_url,headers=headers).text video_url = re.findall('srcUrl="(.*?)",vdoUrl',detail_page,re.S)[0] video_url_list.append(video_url)
video_data_list = pool.map(getVideoData, video_url_list) pool.map(saveVideo, video_data_list) def getVideoData(url): return requests.get(url=url,headers=headers).content def saveVideo(data): fileName = str(random.randint(0,5000))+'.mp4' with open(fileName,'wb') as fp: fp.write(data)
四、总结
本篇涉及到的反爬机制:
- 验证码
- 动态加载