mutate()添加新变量列,保留之前。注:如果没有赋予新值,则在原列基础操作,这种情况多在管道符。 注:新增列与已有列的行数会一致,也要求一致。
transmute() 添加新变量列,并删除现有列。
当与现有具相同变量名,则会覆盖现有变量名
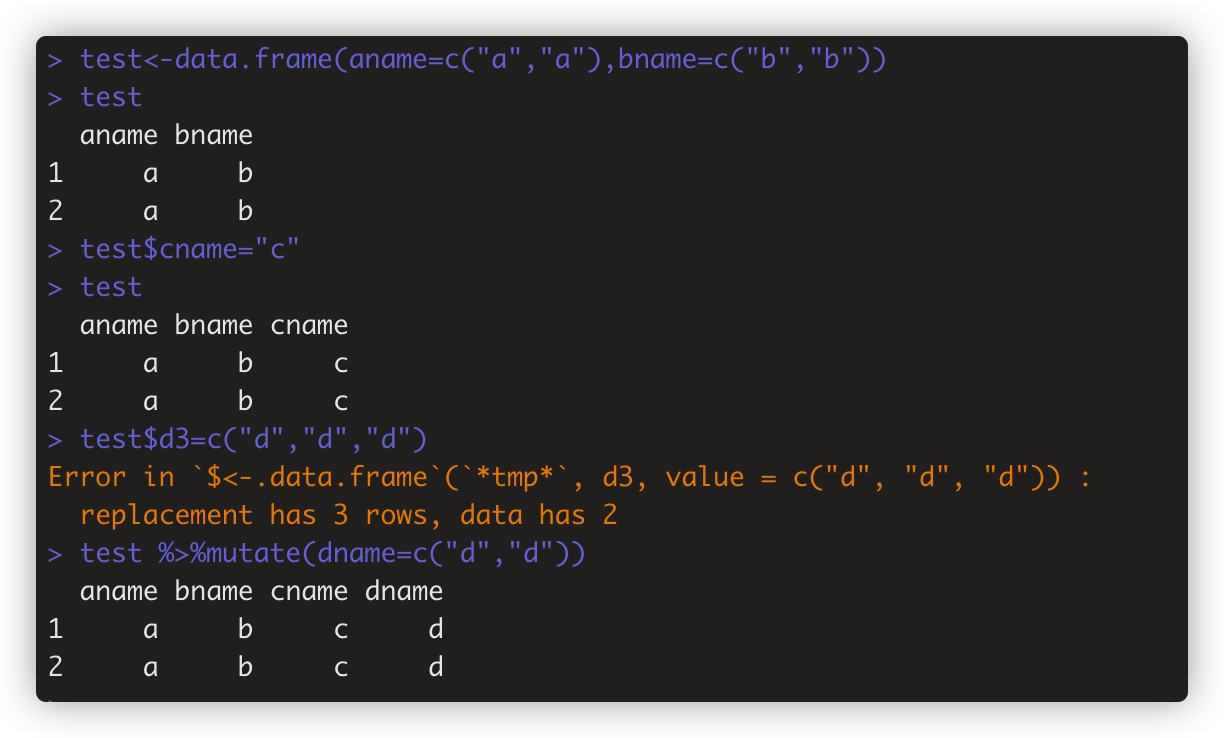
mutate() 增加新列,可以基于现有列运算新列的值,也可以定义。如 test %>%mutate(dname=c("d","d")) 这种情况下,就等同于test$dname=c("d","d")
强在通过管道符来实现多个计算。
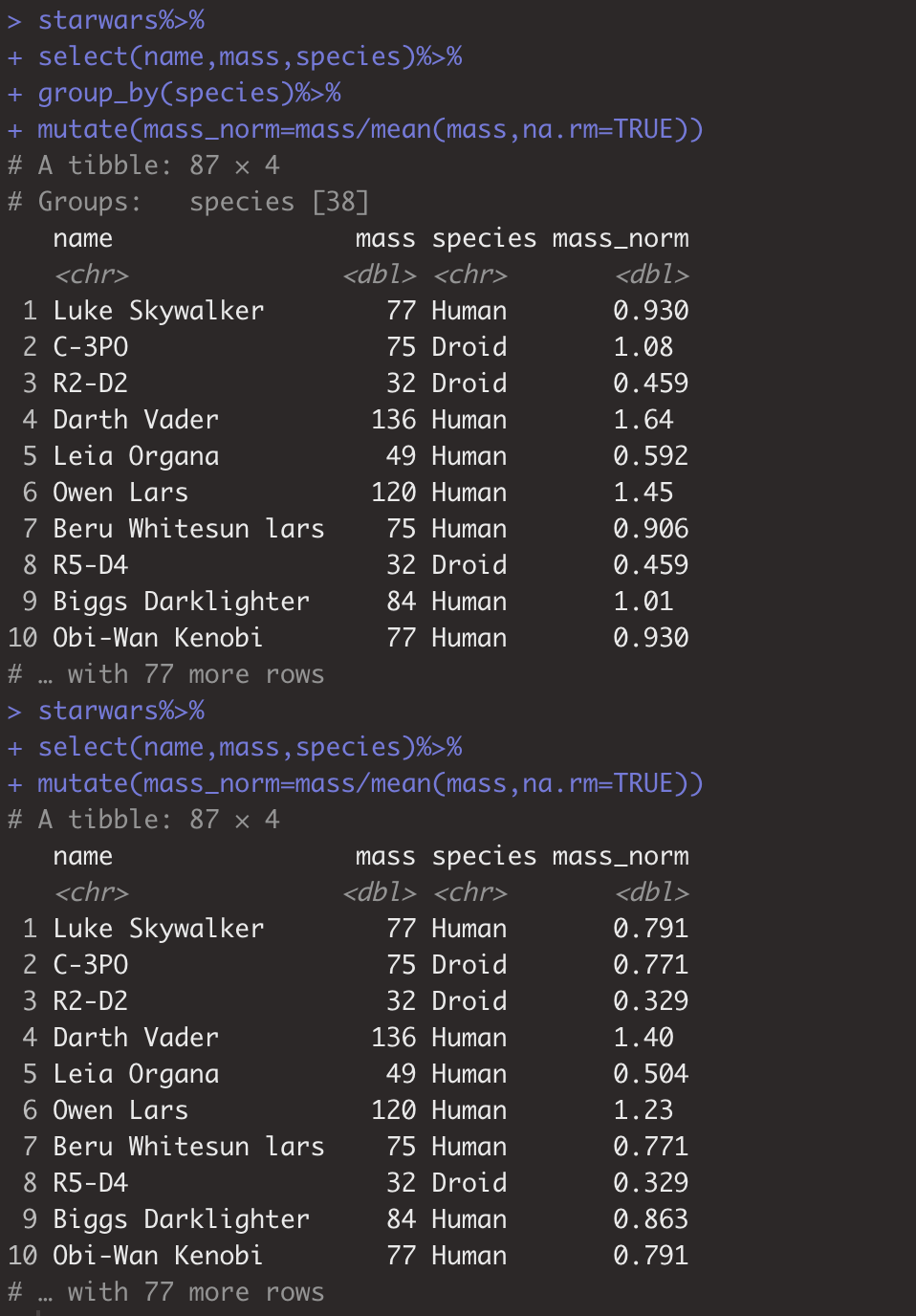
1.搭配group,计算本变量在分组内的平均值。
> starwars%>% + select(name,mass,species)%>%
+ group_by(species)%>%
+ mutate(mass_norm=mass/mean(mass,na.rm=TRUE)) # 下图,前者除以在对应观测分组内均值,后者处以所有观测值均值。
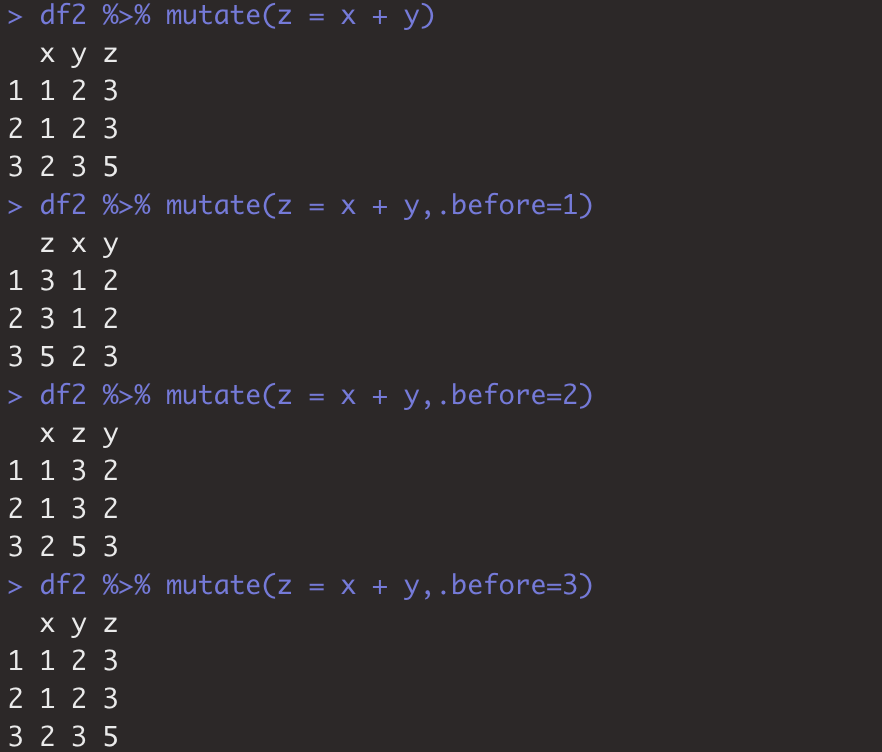
2 通过设置.before,.after参数设置新增列位于正数(倒数)第几列如: df2 %>% mutate(z = x + y,.before=1)
3 还可以设置保留输入列/非输入列。如
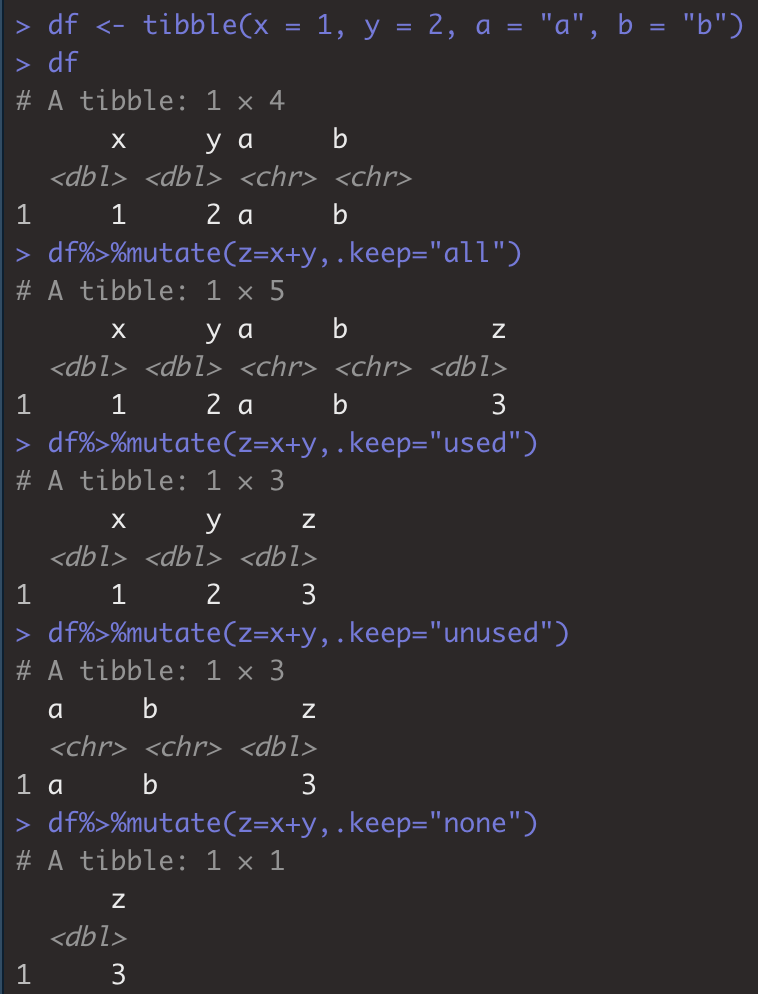
df <- tibble(x = 1, y = 2, a = "a", b = "b") # tibble是tidyverse的新数据类型,是data.frame的子类型。
df%>%mutate(z=x+y,.keep="all") #默认,原所有列都包含。
df%>%mutate(z=x+y,.keep="used") #只保留用到的x,y以及新增的z列
df%>%mutate(z=x+y,.keep="unused")# 只保留没用大的a,b和新增的z列
df%>%mutate(z=x+y,.keep="none") #只保留新增的z列。
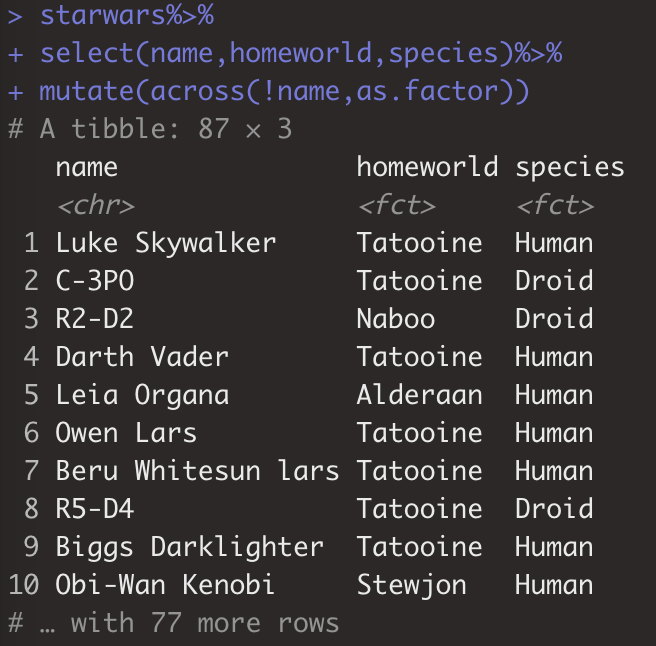
4 tidyverse包的across()函数强大在对多列运行函数。常配合muate()对多列处理。如:
> starwars%>%
+ select(name,homeworld,species)%>%
+ mutate(across(!name,as.factor))#对他两列转换成factor