(一)安装JDK
1. 下载JDK,解压到相应的路径
2. 修改 /etc/profile 文件(文本末尾添加),保存
sudo vi /etc/profile
# 配置 JAVA_HOME
export JAVA_HOME=/home/komean/workspace/JDK/jdk1.8.0_181
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
# 设置PATH
export PATH=${JAVA_HOME}/bin:$PATH:
3. 让修改后的配置立即生效
# 让修改的配置立即生效
source /etc/profile

(二)初步搭建Hadoop
1. 下载hadoop-2.7.7.tar.gz,解压到相应的路径下
2. 修改 hadoop-2.7.7/etc/hadoop 路径下的:slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 、mapred-env.sh、hadoop-env.sh、yarn-env.sh
(1)文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。
localhost
slave1
slave2
(2)文件 core-site.xml 改为下面的配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/komean/workspace/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
(3)文件 hdfs-site.xml,dfs.replication 一般少于节点数,所以这里 dfs.replication 的值还是设为 2:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/komean/workspace/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/komean/workspace/hadoop/tmp/dfs/data</value>
</property>
</configuration>
(4)文件 mapred-site.xml ,需要先拷贝mapred-site.xml.template:
cp mapred-site.xml.template mapred-site.xml
然后mapred-site.xml配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
(5)文件 yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(6)mapred-env.sh、hadoop-env.sh、yarn-env.sh 文件 修改相应的JAVA_HOME
export JAVA_HOME=/home/komean/workspace/JDK/jdk1.8.0_181
3. 修改 /etc/profile 文件(文本末尾添加),保存
# set JAVA_HOME
export JAVA_HOME=/home/komean/workspace/JDK/jdk1.8.0_181
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
# set HADOOP_HOME
export HADOOP_HOME=/home/komean/workspace/hadoop/hadoop-2.7.7
export PATH=${JAVA_HOME}/bin:$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
让修改后的配置立即生效
# 让修改的配置立即生效
source /etc/profile
(三)克隆两台节点虚拟机
192.168.105.25 slave1
192.168.105.35 slave2
(1)配置IP (保持在一个网段下)(参照虚拟机中CentoOs配置ip且连网 第4点)
(2)修改 /etc/hosts 文件 (注意:克隆的,第一个是localhost.localdomain,重复了,修改为localhost)
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.105.15 master
192.168.105.25 slave1
192.168.105.35 slave2
(四)配置SSH无密登录
1. 安装SSH(所有节点都需要)
# 安装
sudo yum install openssh-server
# 重启
service sshd restart
2. 对master节点生成密钥对(只是master节点)运行 ssh-keygen -t rsa 后,不要输入密码,回车
# 生产密钥
cd .ssh
ssh-keygen -t rsa
# 将公钥id_rsa.pub追加到授权的key中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 修改authorized_keys的权限
chmod 600 ~/.ssh/authorized_keys
3. 将authorized_keys文件以及id_rsa文件用scp命令分别复制到其他2个节点(依旧是在master上操作)
scp ~/.ssh/authorized_keys komean@192.168.105.25:~/.ssh
scp ~/.ssh/authorized_keys komean@192.168.105.35:~/.ssh
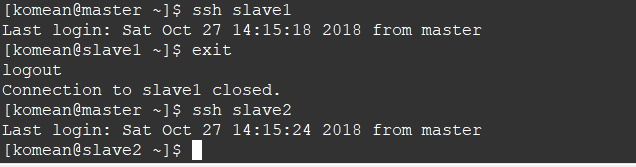
4. 测试 ssh slave1 或者ssh slave2
(五)关闭防火墙(所有节点),在开启 Hadoop 集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping 得通但 telnet 端口不通,从而导致 DataNode 启动了,但 Live datanodes 为 0 的情况。
关闭防火墙
sudo service iptables stop # 关闭防火墙服务
sudo chkconfig iptables off # 禁止防火墙开机自启,就不用手动关闭了
(六)Hadoop初始化,启动所有节点
1. 启动节点(初始化别总用)
# 进入"workspace/hadoop/hadoop-2.7.7" 路径下
cd workspace/hadoop/hadoop-2.7.7
# Hadoop初始化(第一次)
# bin/hdfs namenode -format
# Hadoop启动
sbin/start-all.sh
# 验证
jps

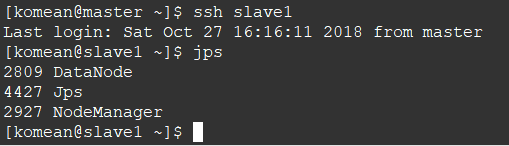
2. 查看两个从节点的情况
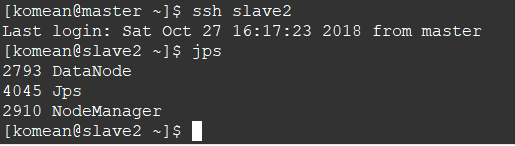
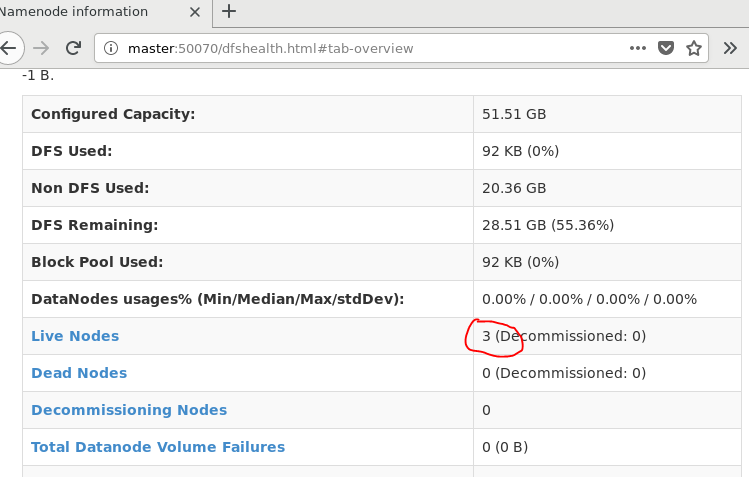
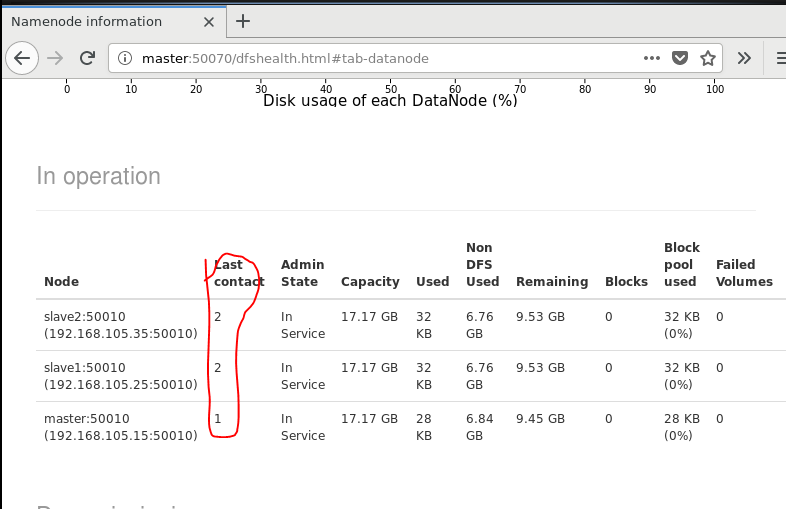
3. 查看节点信息 (或者通过Web 页面看到查看 DataNode 和 NameNode 的状态:http://master:50070/)
hdfs dfsadmin -report
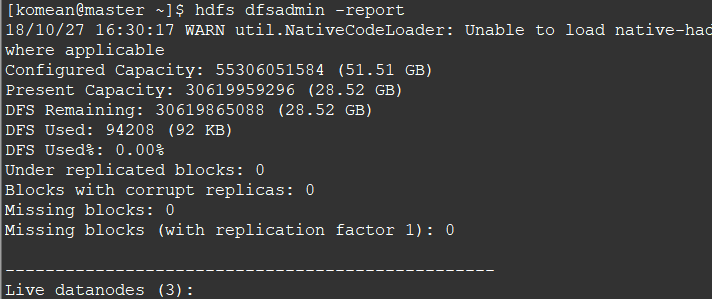
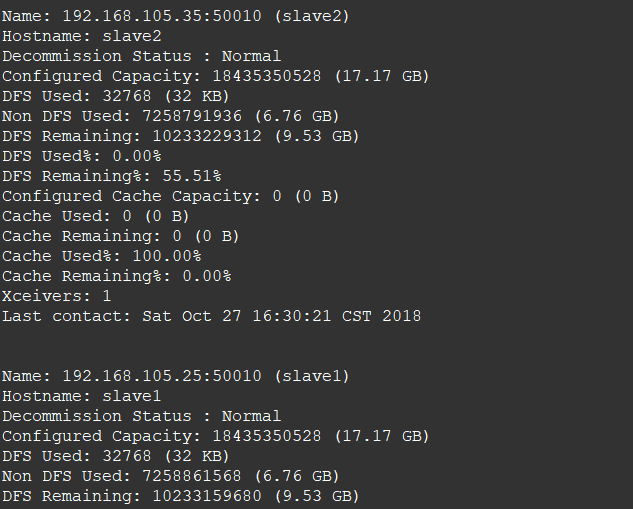
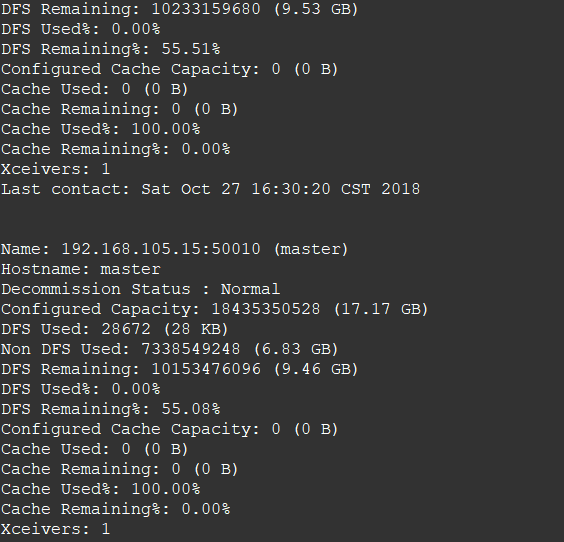
通过Web 页面看到查看 DataNode 和 NameNode 的状态:http://master:50070/