tf.data.Dataset API非常丰富,主要包括创建数据集、应用transform、数据迭代等。
一、Dataset类初览
最简单的方法是根据python列表来创建:
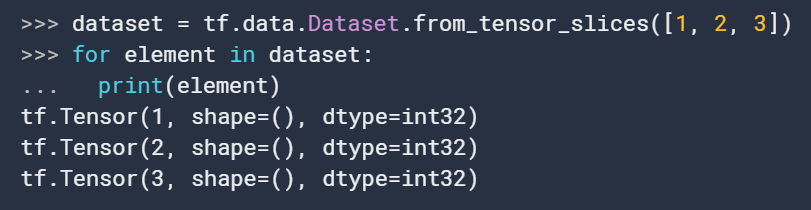
处理文件数据,利用tf.data.TextLineDataset:
对于TFRecord格式可以利用TFRecordDataset:
对于匹配所有文件格式的数据,可以利用tf.data.Dataset.list_files:

Transformations
有了数据可以利用map函数来transform数据:

Dataset支持哪些类型:
包括嵌套的元组、具名元组、字典等。元素可以为任何类型:
tf.Tensor, tf.data.Dataset, tf.SparseTensor,tf.RaggedTensor, 和 tf.TensorArray. 
从上面可以看到,Dataset有一个参数:variant_tensor, 具有一个表示元素类型的属性: element_spec
下面详细介绍Dataset类方法
二、Dataset类的方法(共26个)
1. __iter__
顾名思义,返回该数据集的迭代器。并可以在eager模式下使用。
2. apply
apply(
transformation_func
)对数据应用transformation

3. as_numpy_iterator(貌似2.0.0版本没有该方法)
返回一个将数据元素转换为numpy的迭代器,方便只查看元素。这个操作比直接打印print少了元素类型和类型:

这个方法需要在eager模式下才行, 只显示数据本身:
as_numpy_iterator() 将保留数据元素的原始嵌套格式:

如果数据中含有非Tensor值报错TypeError,若在非eager模式下用会报错RuntimeError。
4. batch
batch(
batch_size, drop_remainder=False
)该方法将数据组成批量。

参数drop_remainder类似于pytorch中的drop_last:

5. cache
cache(
filename=''
)缓存数据,当前据迭代完成,元素会在特定地方实现缓存,后续迭代会利用缓存的数据。

当缓存到文件时,在整个运行过程缓存数据将保持,首次迭代 也将从缓存文件中读取数据。如果在.cache()调用之前改变了数据源,将不会有任何影响。除非cache文件被移除或者文件名更换:
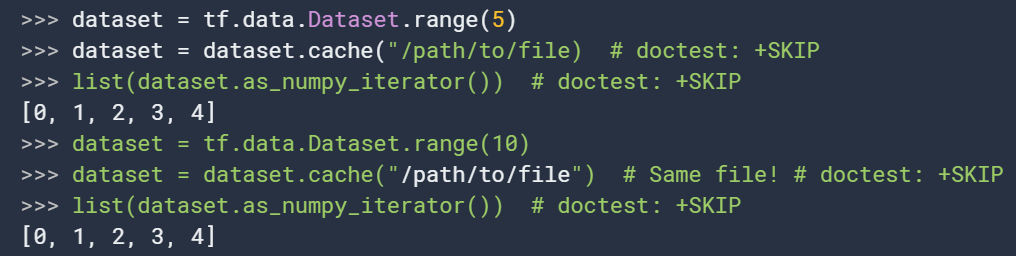
第二次虽然改变了源数据,仍打印出原始数据的内容。 如果调用该函数时没有提供文件名,则数据将缓存到memory中。
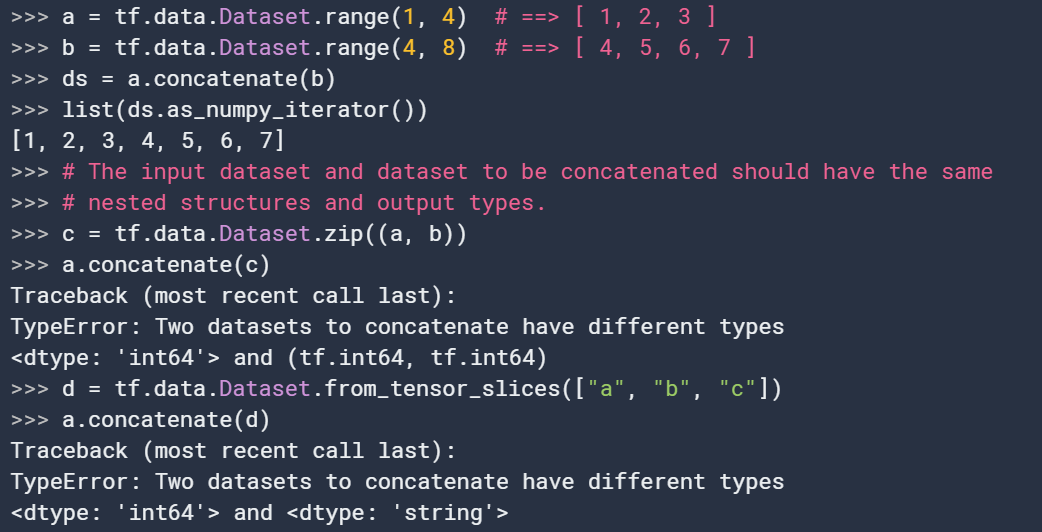
6. concatenate
concatenate(
dataset
)通过连接给定的数据集得到新数据集,注意类型要一致。
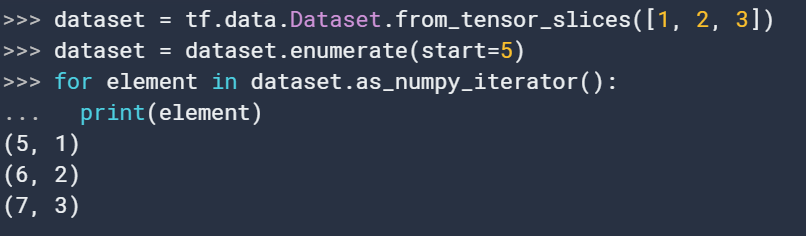
7. enumerate
enumerate(
start=0
)按要求枚举数据,和python的enumerate类似。

8. filter
filter(
predicate
)过滤数据集,输入为函数(映射数据为布尔类型)
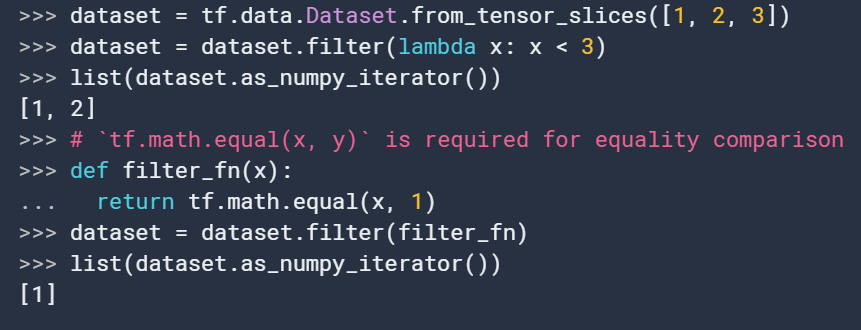
9. flat_map
flat_map(
map_func
)拉伸数据。如果要确保数据集的顺序保持不变可以用该函数,例如将批量数据拉伸至元素级别:

10. from_generator
@staticmethod
from_generator(
generator, output_types, output_shapes=None, args=None
)建立一个数据集,其中的元素由生成器generator产生。generator的参数必须是可callable的类,返回支持iter()的类。产生的元素必须与output_types一致,output_shapes参数可选。

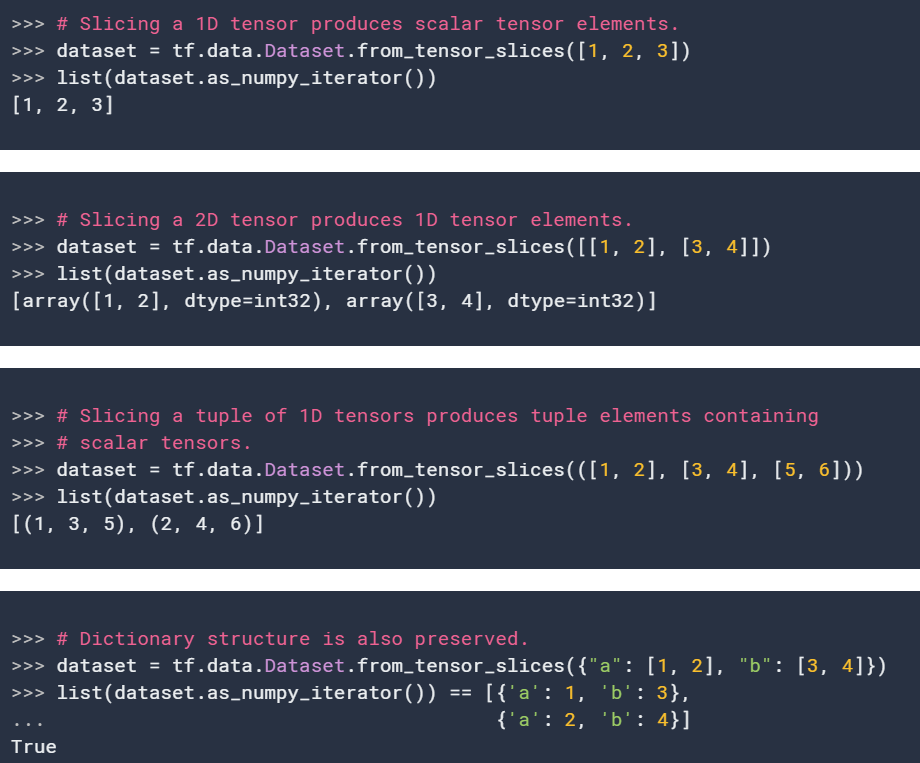
11. from_tensor_slices
@staticmethod
from_tensor_slices(
tensors
)这个方法早在前面许多例子中用到了,从给定tensor切片中创建数据集。从第一维度进行slice,保留了输入tensor的结构,移除每个tensor的第一维度并作为数据集的维度。所有的输入tensor必须有相同的第一维度。
利用zip将不同dataset打包到一起:

输出:
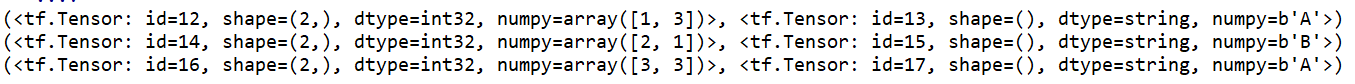
两个tensor只要第一维一样就可以结合到一个dataset中:

12. from_tensor
@staticmethod
from_tensors(
tensors
)与上面不同的是不含切片,只是将整个tensor作为一个dataset。例如:
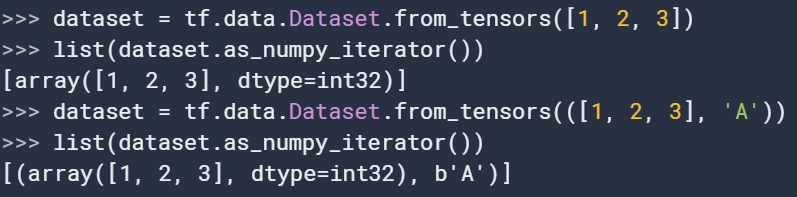
和上一个方法的一个共同点:如果输入tensors中包含numpy数组,并且eager模型未开启,则将会被嵌入到graphs中作为一个或多个tf.constant.对于大型数据集(>1GB),这可能会浪费存储。如果tensors中包含一个或多个大型numpy数组,可以考虑利用这里this guide.的操作。
13. interleave
interleave(
map_func, cycle_length=-1, block_length=1, num_parallel_calls=None
)将map_func映射到整个数据集。并分发结果。

14. list_files
@staticmethod
list_files(
file_pattern, shuffle=None, seed=None
)匹配一个或更多的glob模式,file_pattern参数应当小于glob patterns,否则可以用Dataset.from_tensor_slices(filenames) 就好。

15. map
map(
map_func, num_parallel_calls=None
)这个函数也已经用了多次,将map_func 应用到整个数据集中。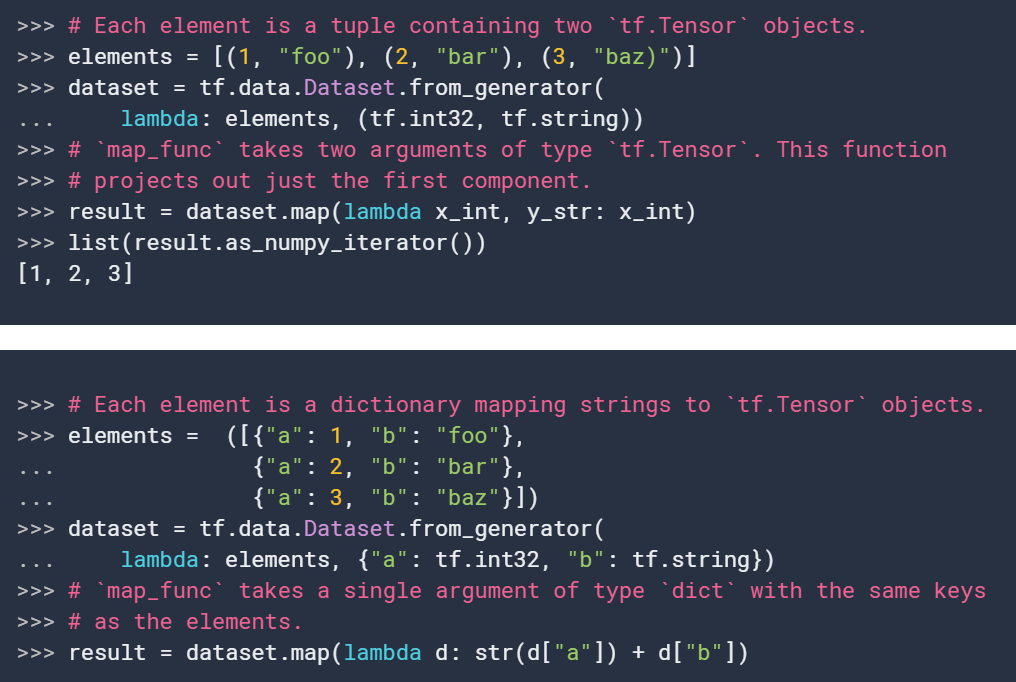


16. padded_batch
padded_batch(
batch_size, padded_shapes, padding_values=None, drop_remainder=False
)此转换将输入数据集的多个连续元素合并为一个元素。类似于tf.data.Dataset.batch,将会有一个新增的batch维度,不同的是此时输入的元素可能shape不同,该转换将会pad每个元素来得到应有的padding_shapes。这个参数决定了最后的输出批量维度。如果维度是一个常数e.g. tf.compat.v1.Dimension(37),元素将会在该维度被pad到该长度,如果维度是未知的e.g. tf.compat.v1.Dimension(None),将会被pad到所有元素的最大长度。
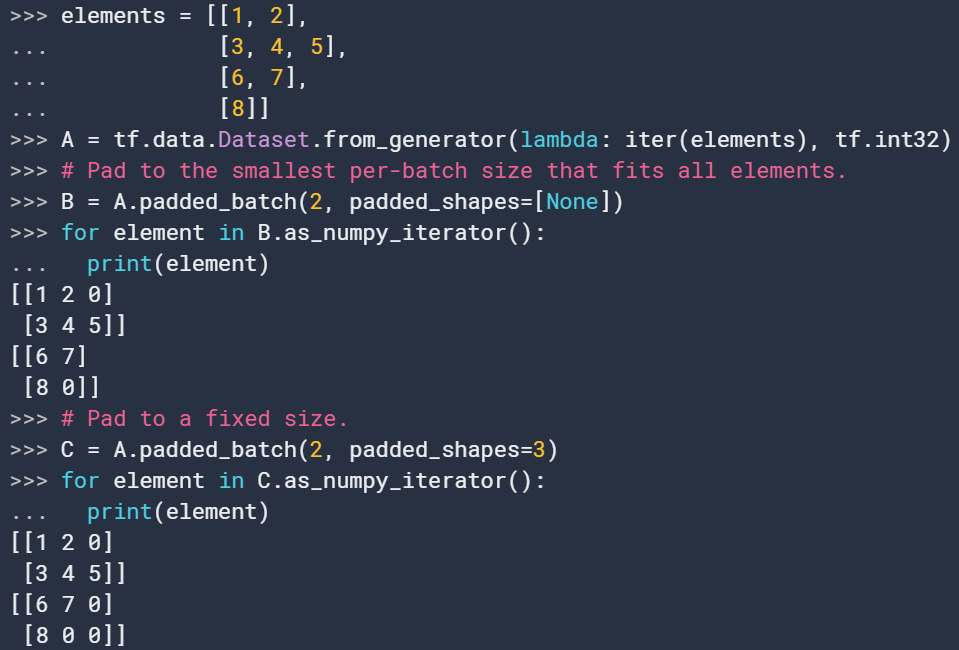
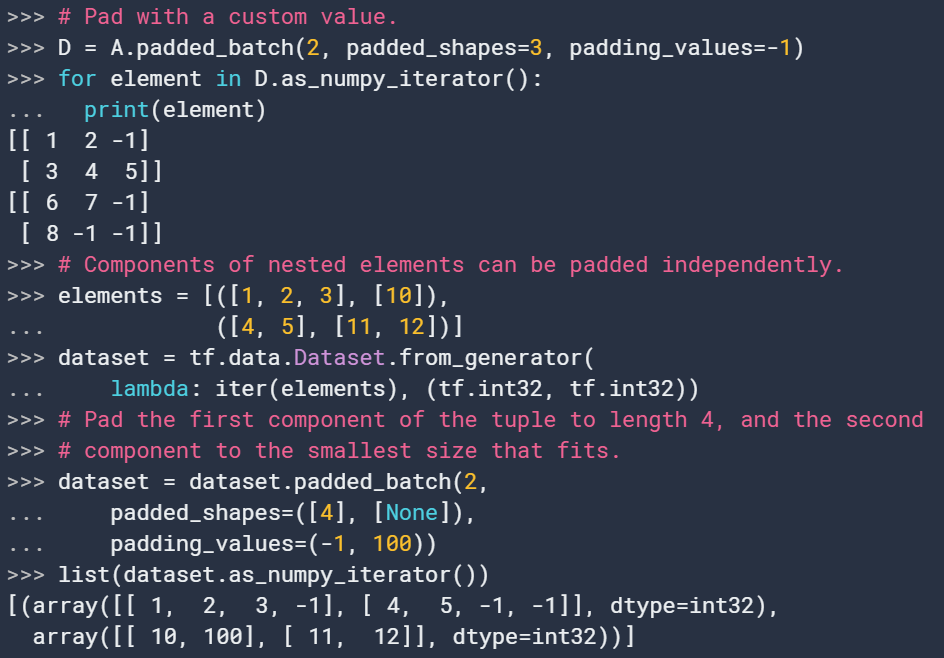
17. prefetch
prefetch(
buffer_size
)从数据集中建立预读取元素。大多数数据集输入结构都应该以预读取prefetch结束。这允许在处理当前元素时准备后面的元素。这通常会提高延迟和吞吐量,代价是使用额外的内存来存储预取的元素。

和batch方法一起使用:
examples.prefetch(2) will prefetch two elements (2 examples), while examples.batch(20).prefetch(2) will prefetch 2 elements (2 batches, of 20 examples each).
利用prefetch和num_parallel_calls 参数,模型训练的时间可缩减至原来的一半甚至更低:


1 train_dataset = tf.data.Dataset.from_tensor_slices((train_filenames, train_labels)) 2 train_dataset = train_dataset.map( 3 map_func=_decode_and_resize, 4 num_parallel_calls=tf.data.experimental.AUTOTUNE) 5 # 取出前buffer_size个数据放入buffer,并从其中随机采样,采样后的数据用后续数据替换 6 train_dataset = train_dataset.shuffle(buffer_size=23000) 7 train_dataset = train_dataset.batch(batch_size) 8 train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE)

tf.data 的并行化策略性能测试(纵轴为每 epoch 训练所需时间,单位:秒)
18. range
@staticmethod
range(
*args
)也已经用过多次了:建立一定范围内的元素数据集

19. reduce
reduce(
initial_state, reduce_func
)将输入元素整合成单一元素。该转换将会已知在每个元素上调用reduce_func函数,直到遍历数据集结束。initial_state参数用于初始状态。

注意reduce_func参数需要两个参数为 (old_state, input_element),这两个茶树会被映射到new_state,当然最开始的old_state就是initial_state,所以这些state的格式应当一致。最终返回的就是final state。这样就好理解上图中的例子了。
20. repeat
repeat(
count=None
)就是按照重复次数来重复输入元素。

21. shard
shard(
num_shards, index
)创建一个仅包含1/num_shards原有数据集大小的数据集。 index实现开始索引。

在分布式训练的时候很有用,因为者可以划分给每个设备一个子集。当读取到一个单一的输入文件时,可以这样做:

重要注意事项:在使用任何随机化操作符(如shuffle)之前,一定要切分。通常,最好在数据集管道的早期使用shard操作符。例如,从一组TFRecord文件中读取时,在将数据集转换为输入样本之前切分。这样就避免了读取每个工人的每个文件。下面是一个完整管道内高效分片策略的示例:

21. shuffle
shuffle(
buffer_size, seed=None, reshuffle_each_iteration=None
)随即打散输入数据。数据填buffer_size大小的元素到buffer中,然后在该buffer中进行随机采样。对于完美的打散计划,buffer尺寸应大于等于所需的数据集尺寸。例如你的数据集有10000个元素,但是buffer_size设置为1000,然后仅会从这1000个元素中进行随机选择。一旦某个元素被选定,其位置就会被下个(额外的)元素取代从而保持buffer大小为1000。参数reshuffle_each_iteration 控制是否不同epoch保持相同的shuffle顺序。在TF1.X版本中,惯用的方法是通过repeat转换:

在TF2.0版本中,tf.data.Dataset是python可迭代的,所以通过python迭代也可以创建批量: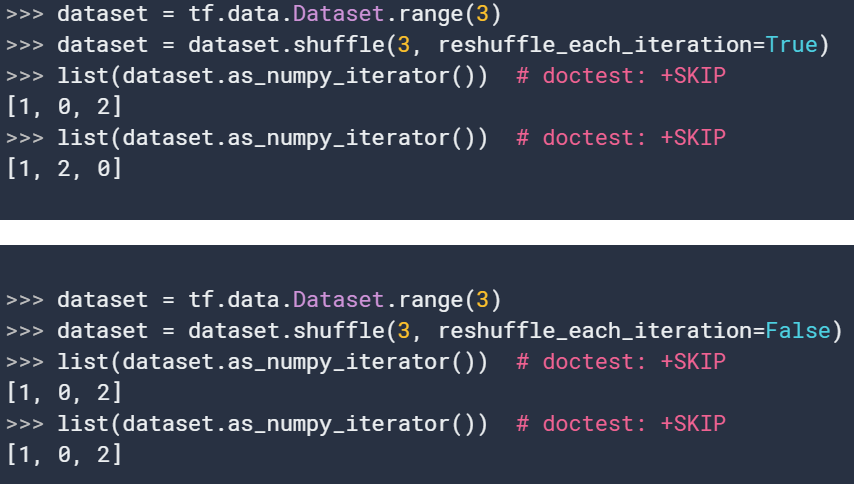
22. skip
skip(
count
)创建一个数据集:跳过count参数之前的元素:
如果count参数大于当前数据集的大小,新的数据集将不包含任何数据。如果将其设为-1,则包含整个数据。
23. take
take(
count
)创建一个数据集:最多包含count数目大小的数据集:

如果count=-1 或者count大于整个数据集尺寸,新的数据集将包含整个数据集。
24. unbatch
将数据集划分到多个元素。就是batch的反向操作,最后结果是分解掉了batch的维度:

25. window
window(
size, shift=None, stride=1, drop_remainder=False
)结合输入元素到windows,windows指的是一个有限的数据集,尺寸为size或更小:如果没有足够输入元素来填充这个window或者drop_remainder参数为False。stride参数决定了输入元素的步长,shift参数决定window的偏移。后三个参数都是可选。size表示形成window所需要结合的数据元素数目(窗口大小)。shift表示每次迭代的滑动数目。stride表示每个窗口中元素步长。最后一个参数表示是否丢弃当前窗口,如果其尺寸小于指定的size。


26. zip
@staticmethod
zip(
datasets
)打包多个数据集,用到多次了。和python基本一样,差别在于datasets参数可以实任意嵌套的Dataset类。

整理编辑自:https://www.tensorflow.org/api_docs/python/tf/data/Dataset