feature study within neural network
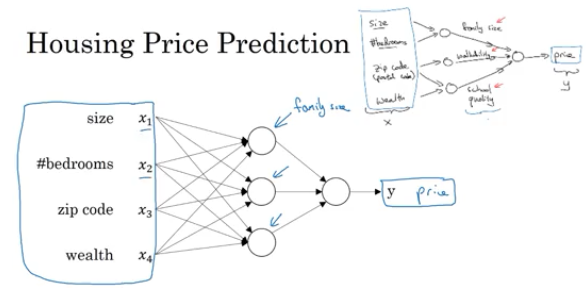
在regression问题中,根据房子的size, #bedrooms原始特征可能演算出family size(可住家庭大小), zip code可能演算出walkable(可休闲去处),富人比例和zip code也可能决定了学区质量,这些个可住家庭大小,可休闲性,学区质量实际上对于房价预测有着至关重要的影响,但是他们都无法直接从原始数据输入获取,而是进过hidden layer学习抽象得出的特征。
loss function .vs. cost function
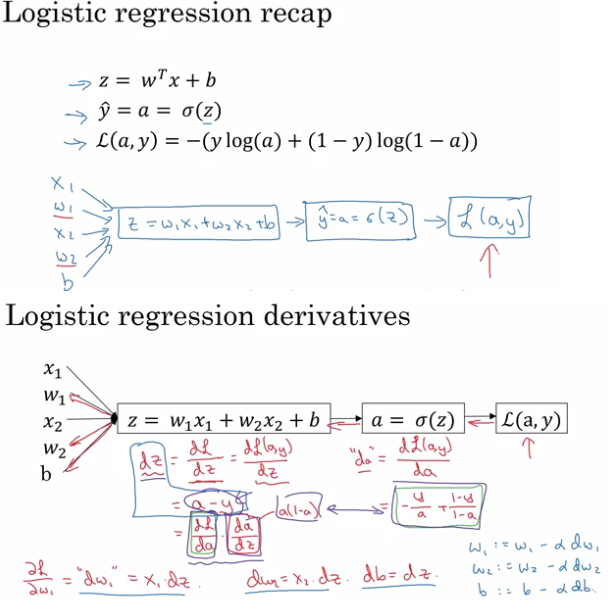
loss function是对任一个样本点定义的损失函数,而cost function则是对整个数据样本集来说,将各个样本点的具体数值带入进去后计算得出的值。
比如,以逻辑回归为例:
$$L(hat y,y) = -(y loghat y + (1-y)log(1-hat y))$$
$$J(w,b) = frac{1}{m}sum_{i=1}^{m} L(hat y ^{(i)},y^{(i)}) = - frac {1}{m} sum_{i=1}^{m} [y^{(i)} loghat y^{(i)} + (1-y^{(i)})log(1-hat y^{(i)})]$$
在logistic(binary)regression问题中,我们往往不用(y-y~)2方差作为loss函数,其中一个重要的原因是这个函数不是convex函数,因而使用另外一个凸函数作为loss function并使用梯度下降法来训练w,b参数:

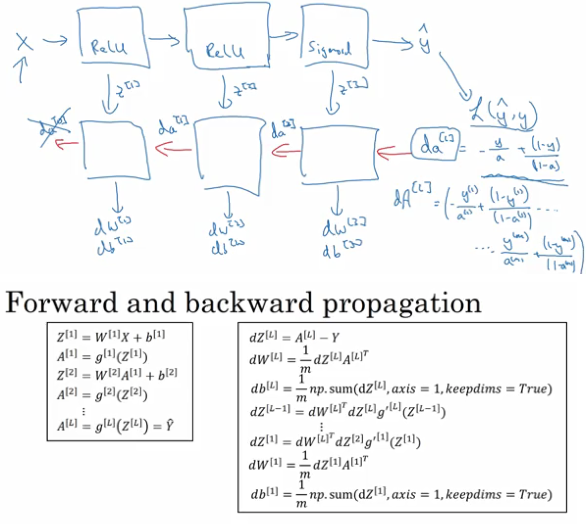
神经网络前向传递和后向传播
前向传递根据w,b参数以及dataset来计算出当前参数下的神经网络的输出及当前模型输出对应的loss函数值,后向传播则层层求导计算为参数更新打下基础,在下一次前向传递时,更新w,b参数后继续计算神经网络的输出以及对应的loss函数值,最终使得loss值达到最小
上面示例只是给出了梯度下降法在针对一个数据时前向和后向计算过程,下面综合考察所有数据集取平均数之后的计算方法以及编码方法:

vectorization
上面的代码中,直接使用两个for loop,但是在深度学习中,一般我们的数据集非常大,这时如果直接用for loop来写梯度下降发的计算,则效率非常底下,这时我们就要使用numpy的向量化函数来提高效率:

broadcasting

generalize neural network from logistic regression model:
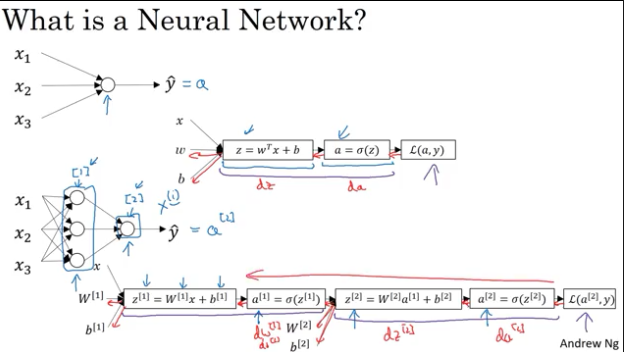
neural network representation
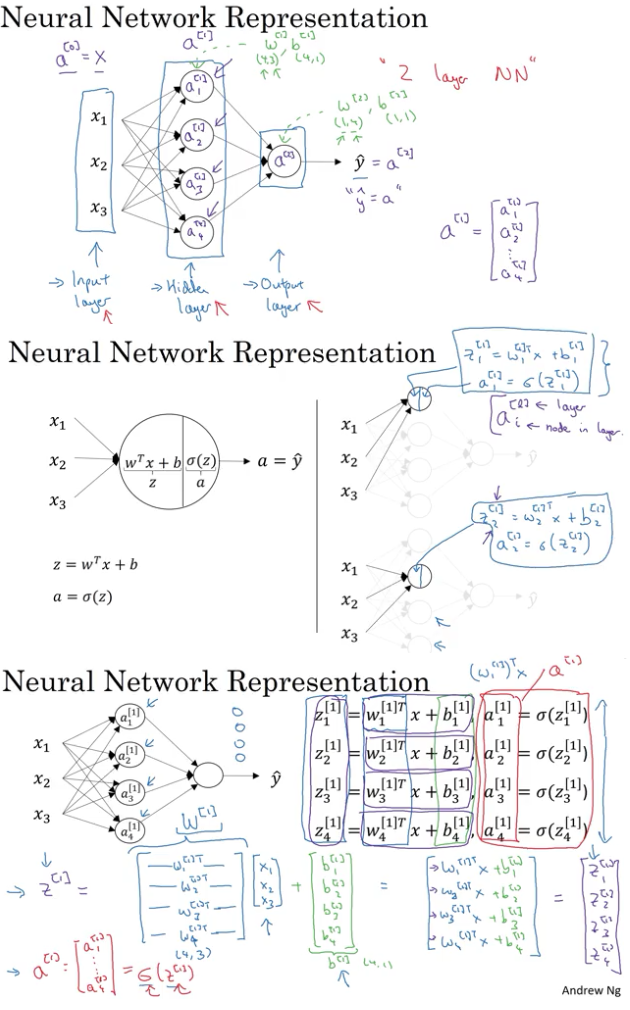
vectorize on neural network

activation functions:
一般在隐藏层,我们使用RELU,或者变种的RELU,而对于罗辑回归的输出层,可能要使用sigmoid函数输出0,1的概率
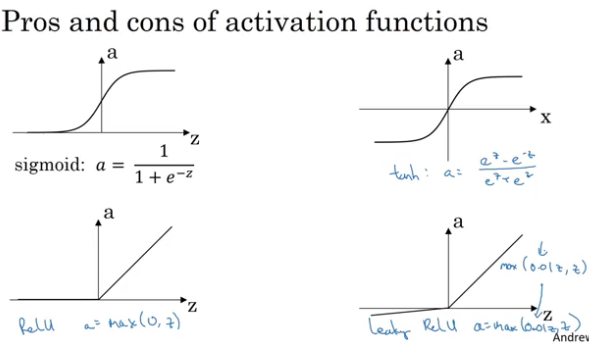
为何我们在神经网络中使用非线性激活函数?
因为如果我们不使用非线性激活函数,那么即使有再多的隐藏层数,输出y实际上就是输入x的线性函数,而这完全可以用线性回归模型来表达,完全没有必要使用神经网络。
也正因为神经网络中的非线性激活函数的引入,随着多层网络复杂度的增加,神经网络能够表达几乎任何复杂的非线性关系,这就是神经网络的强大之处
神经网络中的矩阵shape:
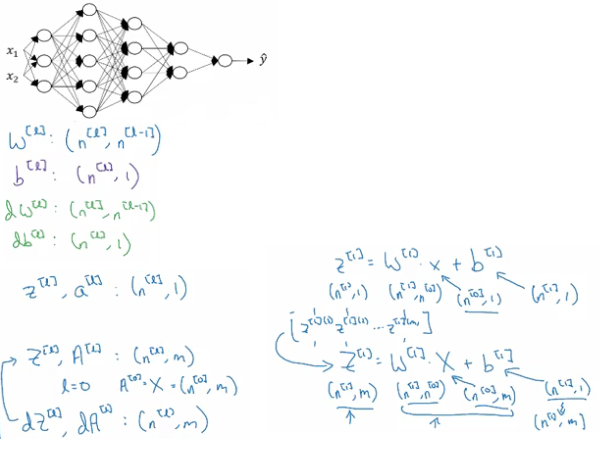
calculation path forward and backward
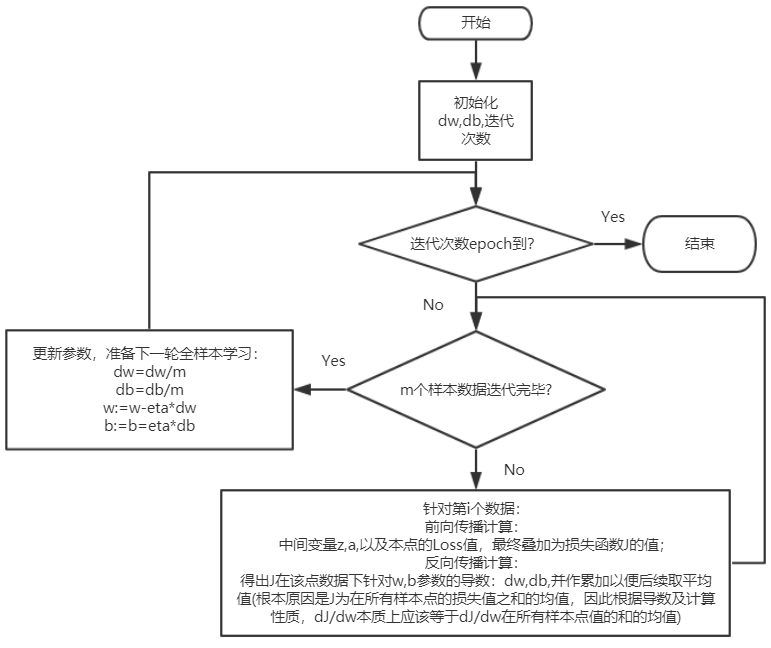
batch梯度下降算法流程(未向量化)图
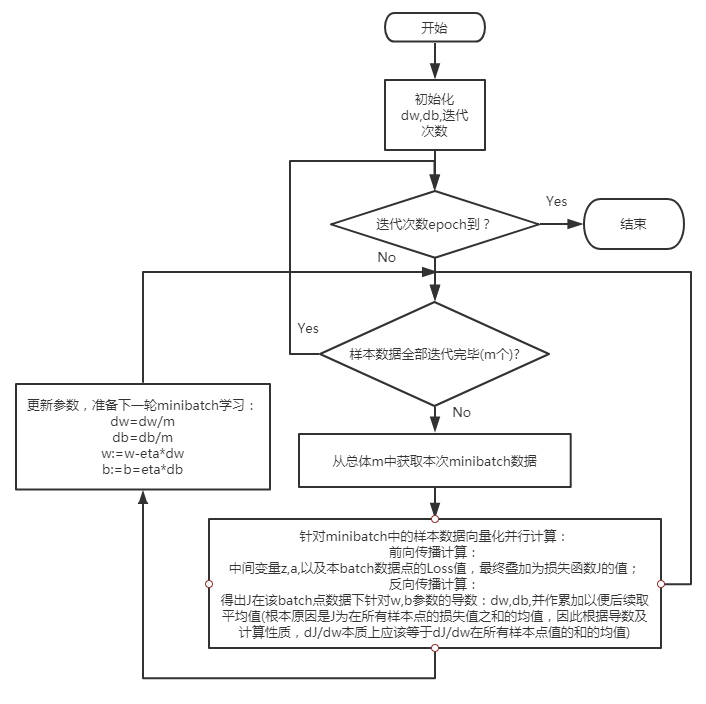
mini batch梯度下降算法
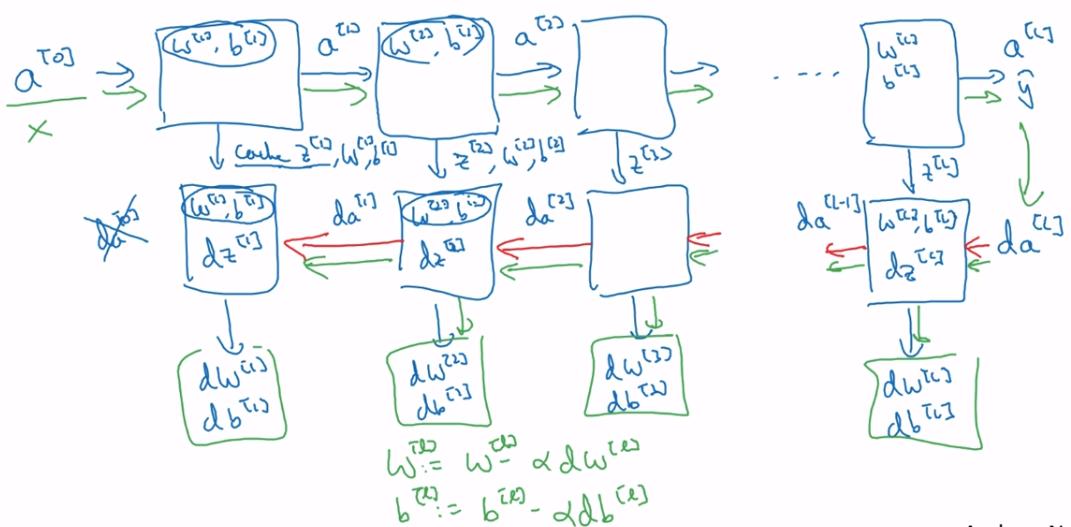
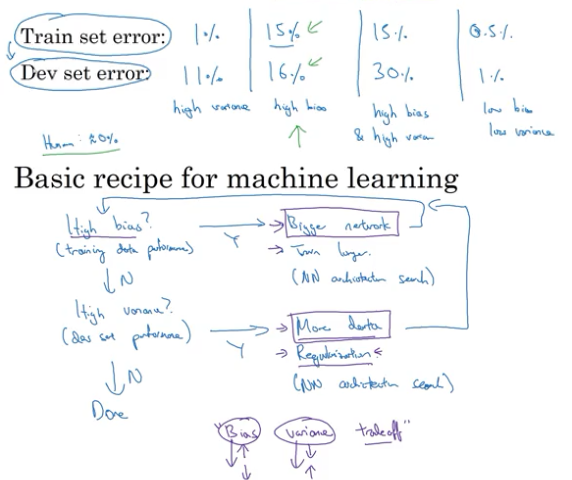
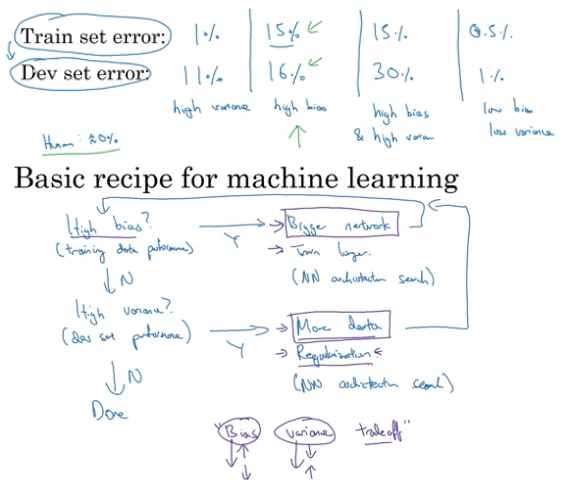
high bias vs high variance及神经网络最常用食谱
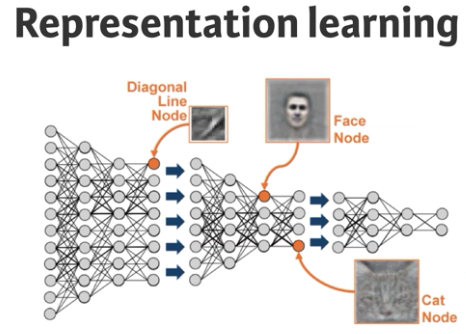
deep learning 特征学习(representation learning)
一般地,在机器学习中,非常重要的一环是特征工程,也就是从输入数据中变换构造出能够用数据来有效表达输入数据的"特征",将这些特征作为机器学习算法的输入,并且应用学习算法训练出捕捉到输入到输出映射的"模型"。而在deep learning中,我们有很多hidden layer,每一层hidden layer通过训练,实际上其系数data以及应用在前一层输入数据上后执行非线性激励的输出data,这些data就包含着数据中的pattern,越靠后的隐蔽层越能构造出更加抽象的特征。因此在神经网络中,我们甚至可以剔除特征工程这一步骤,让网络自己去学习获得特征,并且将学习到的这些特征作为后续网络的输入继续学习,直到获得较好的预测效果。
反向传播到底在干什么?
在神经网络训练过程中,反向传播的本质是要计算coss function针对所有的系数对应的偏导数,从而使得在下一轮的前向传播训练中可以正确地同时更新所有的权重系数以达到损失函数值梯度不断递减这个目标。 反向传播计算导数过程中,为了计算方案,我们需要前向计算时已经算得的z,a,prediction等值
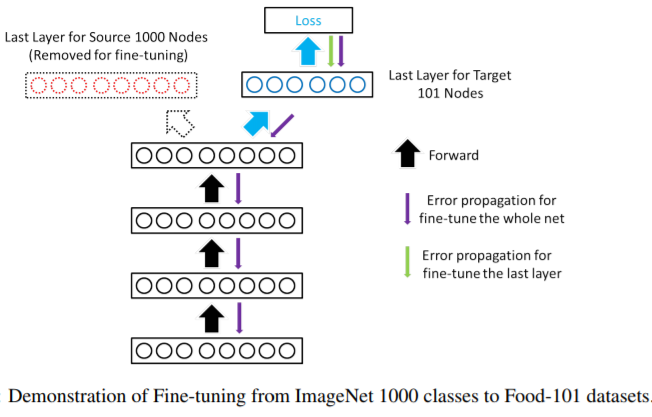
transfer learning
在计算机视觉中,一个大的问题是训练数据不足,而要获得一个比较好的模型,往往需要成千上万甚至数百万以上的图片数据,同时深度网络训练的时间非常长,如何克服这两个问题同时又能够快速解决我们感兴趣的领域的问题呢?迁移学习就提供了一个非常好的思路。
我们可以使用开源的数据集,比如imageNet 1000 class,有非常多的优秀的网络已经针对该数据集做了训练,相应的代码,权重都可以方便获得。我们要做的就是站在前人的肩膀上:
1. 基于开源网络结构和权重参数外接我们感兴趣的softmax分类器,就好像武林高手内功传递一样将相应知识(比如底层特征学习能力)传给后面的网络,而数据则使用我们自己的数据集仅针对后面我们自己增加的网络来做训练。
2.甚至可以使用预先训练好的网络针对我们自己的数据集预先做好计算输出对应的activation作为特征,来训练后面我们自己的网络
3.当然,如果我们领域内的图片也很庞大,则可以从后往前开放部分隐藏层也参与训练,最终和我们自己加的网络层共同组成model
https://ir.lib.uwo.ca/cgi/viewcontent.cgi?article=6225&context=etd
two sources of knowledge for model to train
labeled data
hand engineered features/network architecture/other components
deep learning networks
梯度gradient计算的两种方式互补:数值算法和解析算法
在网络训练时,我们需要使用梯度下降法,而梯度就是用来做参数更新的最重要数据。梯度如何获取呢?一般有两种方式:
一种是通过数值方法,根据梯度导数的定义
$$frac{df(x)}{dx} = lim_{h ightarrow 0}frac{f(x+h)-f(x)}{h}$$
这种方法简单不会出错,并且总能算得,但是缺点是非常慢,因此常常用来对解析方式结算得来的梯度做检验,确认解析求导的算法正确;
另一种方式是通过解析方法,也就是如果我们能够得到loss函数对各个参数$omega$的解析表达式,使用高等数学求导的知识写出梯度的解析表达式,然后带入数据就能快速算出其梯度。
解析方式有点是快速,准确,缺点是由于得到函数表达式并不容易,非常容易犯错。而在神经网络中,往往借用导数的链式法则来一步步求得loss针对各层参数的梯度
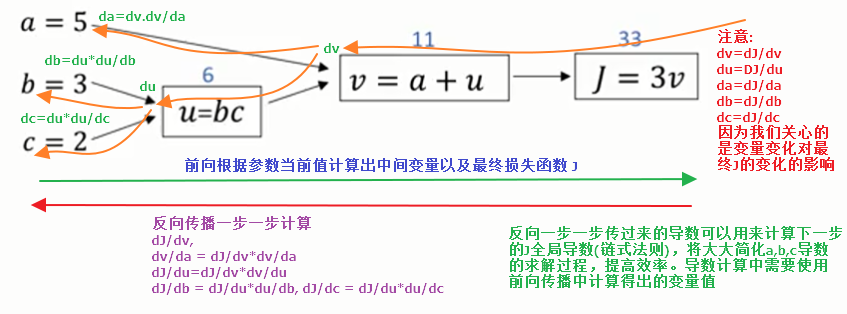
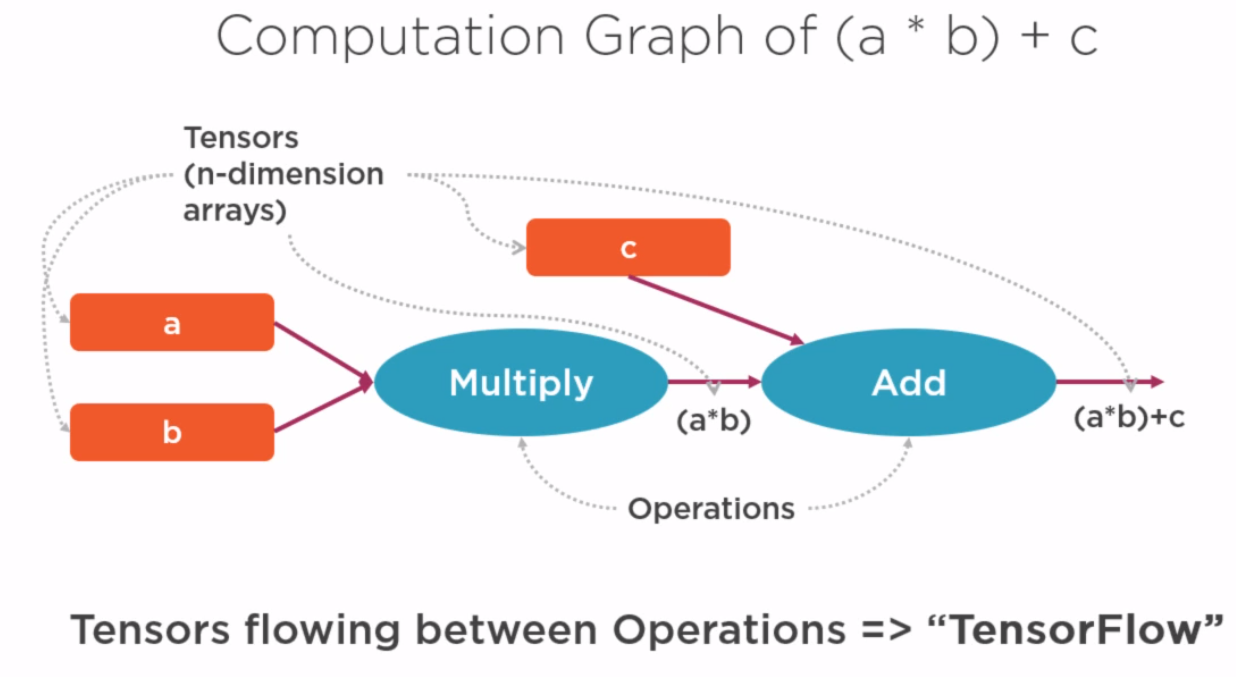
梯度解析求解利器-compution graph:计算图
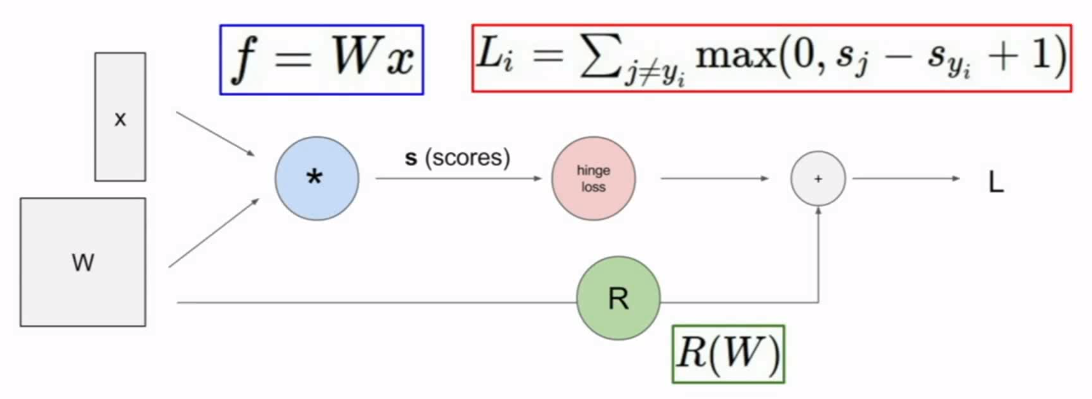
使用计算图的好处是只要我们能够将loss的表达式使用计算图来表达,那么就可以再借用链式求导法则,使用反向传播算法来求解各处的导出。比如卷积神经网络中,loss的求得是经过输入层的图片和各层网络权重参数相乘,再经过池化,激活函数等层层计算最终才能得到Loss函数的表达式,要得到解析式是非常困难的,但是我们却可以使用计算图轻易表达这个前向求解过程。因此,我们只要弄清楚了计算图中导数求解,就可以借助链式法则一步步求解梯度。
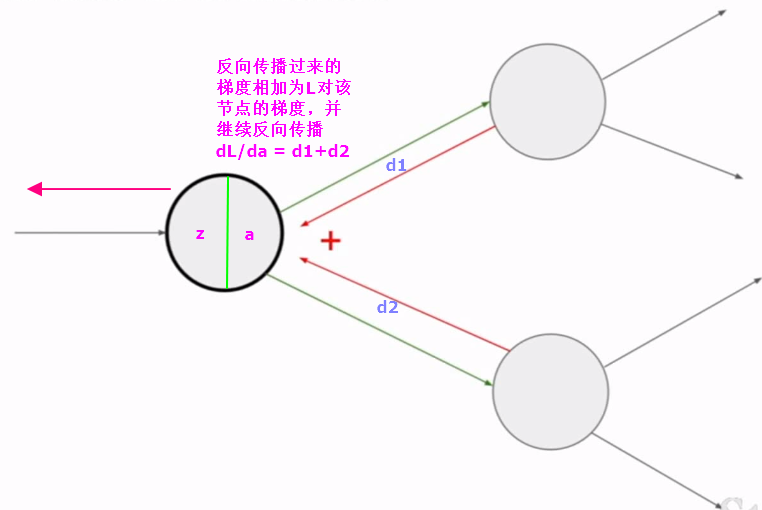
还需要注意的一点是:如果一个节点和后续多个节点直接相连,则从该节点来看反向传播过来的梯度就有多个,我们需要把这些梯度相加后形成Loss对该节点输出a的总梯度
dev set和test set必须来自同一个distribution
假如我们在做一个图片分类的应用,首先我们可能会从web上爬取大量图片,这些图片分辨率,质量层次不齐但是可能又是必须的。而随后我们使用的应用上线后,可能由用户使用手机拍摄的图片直接上传来做分类。这时需要注意的是:dev数据集(validataion set)须要和test set来自同一个分布。也就是说,在验证网络性能时直接使用手机拍摄的图片来做分类验证。
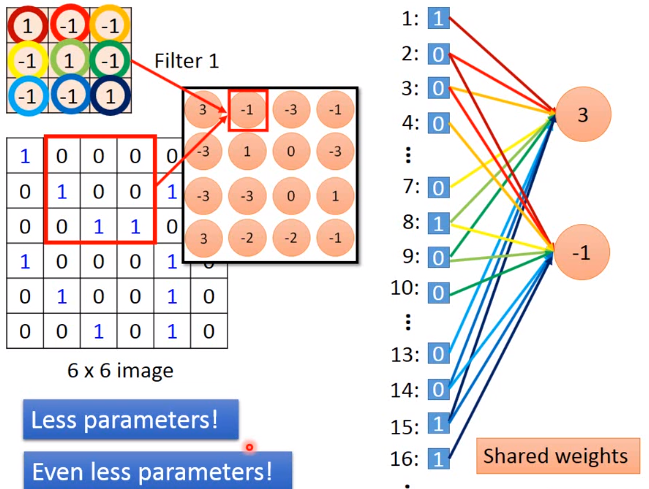
CNN中filter(kernel)和neuron的连接
CNN中各种常见filter效果比对

CNN输出维度的计算
H = height, W = width, D = depth
- 我们有一个输入维度是 32x32x3 (HxWxD)
- 20个维度为 8x8x3 (HxWxD) 的滤波器
- 高和宽的stride(步长)都为 2。(S)
- padding 大小为1 (P)
计算新的高度和宽度的公式是:
new_height = (input_height - filter_height + 2 * P)/S + 1
new_width = (input_width - filter_width + 2 * P)/S + 1
word embedding
将独热编码的稀疏向量映射到另外一个空间中的稠密向量。训练的方法是让ML算法通过读取大量的语料来学习到词汇之间的语义
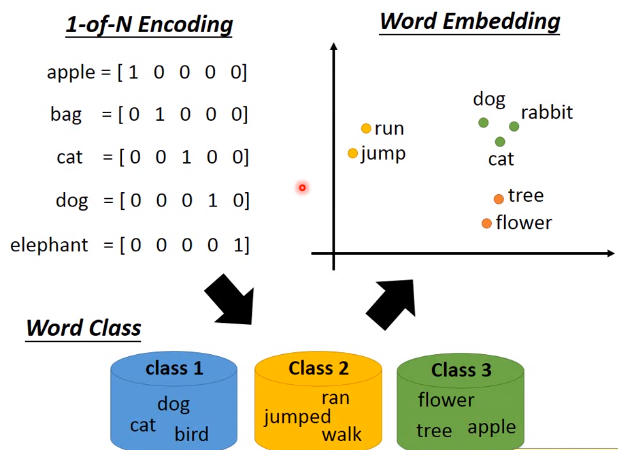
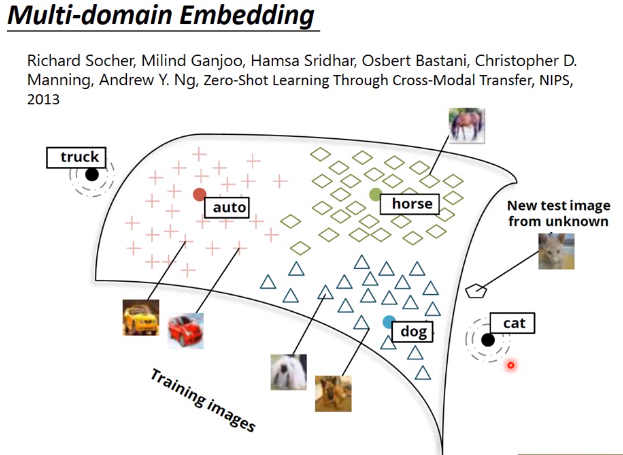
image embedding and document embedding
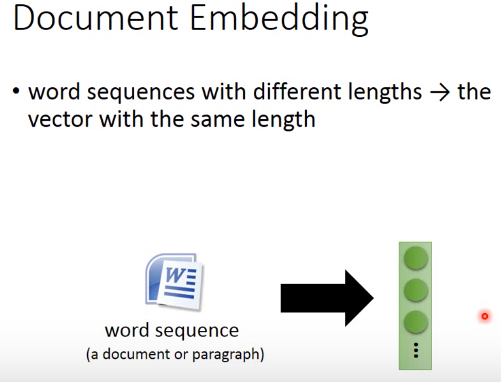
自编码器
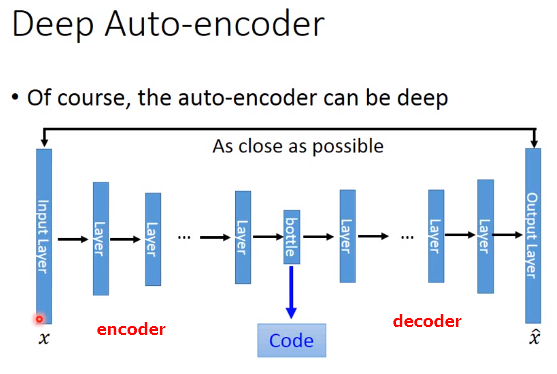
autoencoder可以用于向量化相似搜索,比如图片搜索图片
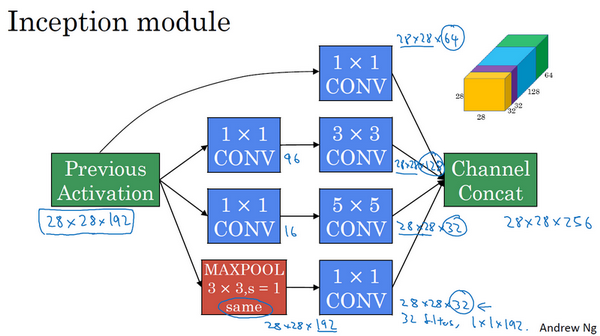
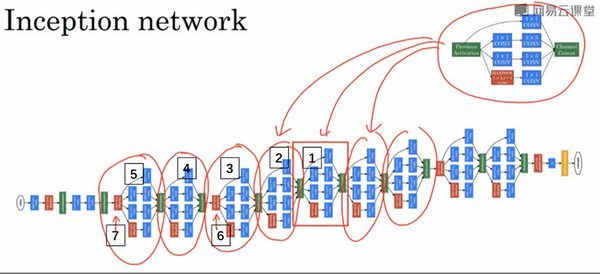
inception网络