转http://www.datadependence.com/2016/05/scientific-python-pandas/
一、 Pandas简介
1、Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
2、Pandas 是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
3、数据结构:
import pandas as pd from pandas import Series
2、Series
Series 就如同列表一样,一系列数据,每个数据对应一个索引值。
- Series 就是“竖起来”的 list:
s=Series([1,4,'ww','tt']) print(s)
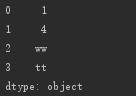
另外一点也很像列表,就是里面的元素的类型,由你任意决定(其实是由需要来决定)。
- 这里,我们实质上创建了一个 Series 对象,这个对象当然就有其属性和方法了。比如,下面的两个属性依次可以显示 Series 对象的数据值和索引:
print(s.index) print(s.values)

- 列表的索引只能是从 0 开始的整数,Series 数据类型在默认情况下,其索引也是如此。不过,区别于列表的是,Series 可以自定义索引:
s2=Series(['Wangwei','man',24], index=['name','sex','age']) print(s2)
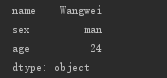
每个元素都有了索引,就可以根据索引操作元素了。还记得 list 中的操作吗?Series 中,也有类似的操作。先看简单的,根据索引查看其值和修改其值:
s2['name'] = 'wudadiao'
这是不是又有点类似 dict 数据了呢?的确如此。看下面就理解了。
读者是否注意到,前面定义 Series 对象的时候,用的是列表,即 Series() 方法的参数中,第一个列表就是其数据值,如果需要定义 index,放在后面,依然是一个列表。除了这种方法之外,还可以用下面的方法定义 Series 对象:
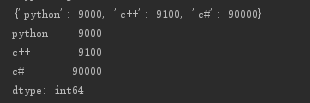
s3={'python':9000,'c++':9100,'c#':9000}
s3pivot=Series(s3)
print(s3)
print(s3pivot)
在 Pandas 中,如果没有值,都对齐赋给 NaN。
Pandas 有专门的方法来判断值是否为空。
print(pd.isnull(s4))
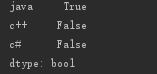
此外,Series 对象也有同样的方法:
print(s4.isnull())
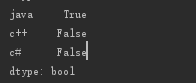
其实,对索引的名字,是可以从新定义的:
s4.index=['语文','数学','英语'] print(s4)
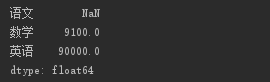
对于 Series 数据,也可以做类似下面的运算(关于运算,后面还要详细介绍):
print(s4 * 2) print(s4[s4>9000])
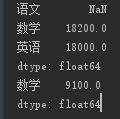
Series就先简要写到这,下面看pandas的另一种数据结构DataFrame.
DataFrame
DataFrame 是一种二维的数据结构,非常接近于电子表格或者类似 mysql 数据库的形式。它的竖行称之为 columns,横行跟前面的 Series 一样,称之为 index,也就是说可以通过 columns 和 index 来确定一个主句的位置。
- 导入模板并输出二维数据
首先来导入模块
dataframe1={"name":['google','baidu','yahoo'],"marks":[100,200,300],"price":[1,2,3]}
print(dataframe1)
f1=DataFrame(dataframe1)
print(f1)

这是定义一个 DataFrame 对象的常用方法——使用 dict 定义。字典的“键”("name","marks","price")就是 DataFrame 的 columns 的值(名称),字典中每个“键”的“值”是一个列表,它们就是那一竖列中的具体填充数据。上面的定义中没有确定索引,所以,按照惯例(Series 中已经形成的惯例)就是从 0 开始的整数。从上面的结果中很明显表示出来,这就是一个二维的数据结构(类似 excel 或者 mysql 中的查看效果)。
- 固定Columns的顺序
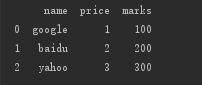
上面的数据显示中,columns 的顺序没有规定,就如同字典中键的顺序一样,但是在 DataFrame 中,columns 跟字典键相比,有一个明显不同,就是其顺序可以被规定,向下面这样做:
f2=DataFrame(dataframe1,columns=['name','price','marks']) print(f2)
- 自定义DataFrame索引
跟 Series 类似的,DataFrame 数据的索引也能够自定义
f2=DataFrame(dataframe1,columns=['name','price','marks'],index=['a','b','c']) print(f2)

- 字典套字典
定义 DataFrame 的方法,除了上面的之外,还可以使用“字典套字典”的方式。
newdata={'lang':{'first':'python','second':'java'},'price':{'first':'5000','second':'2000'}}
f4 = DataFrame(newdata)
print(f4)

在字典中就规定好数列名称(第一层键)和每横行索引(第二层字典键)以及对应的数据(第二层字典值),也就是在字典中规定好了每个数据格子中的数据,没有规定的都是空。
DataFrame对象的columns属性
DataFrame 对象的 columns 属性,能够显示素有的 columns 名称。并且,还能用下面类似字典的方式,得到某竖列的全部内容(当然包含索引):
>>> newdata = {"lang":{"firstline":"python","secondline":"java"}, "price":{"firstline":8000}}
>>> f4 = DataFrame(newdata)
>>> f4
lang price
firstline python 8000
secondline java NaN >>> DataFrame(newdata, index=["firstline","secondline","thirdline"])
lang price
firstline python 8000
secondline java NaN
thirdline NaN NaN
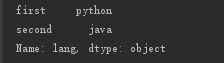
输出某一列
DataFrame 对象的 columns 属性,能够显示素有的 columns 名称。并且,还能用下面类似字典的方式,得到某竖列的全部内容(当然包含索引):
print(f4['lang'])
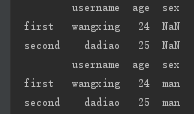
下面操作是给同一列赋值
newdata1 = {'username':{'first':'wangxing','second':'dadiao'},'age':{'first':24,'second':25}}
f6=DataFrame(newdata1,columns=['username','age','sex'])
print(f6)
f6['sex']='man'
print(f6)
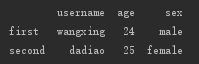
也可以单独的赋值,除了能够统一赋值之外,还能够“点对点”添加数值,结合前面的 Series,既然 DataFrame 对象的每竖列都是一个 Series 对象,那么可以先定义一个 Series 对象,然后把它放到 DataFrame 对象中。如下:
f6['sex']=Series(['male','female'],index=['first','second']) print(f6)
还可以更精准的修改数据吗?当然可以,完全仿照字典的操作:
In [74]: f6['age']['second'] = 30
In [75]: f6
Out[75]:
username age sex
first wangxing 24 男
second dadiao 30 女