kaggle比赛---房价预测
题目介绍

基本操作
该操作可以归结为先进行数据清洗,再用TensorFlow给定的线型模型去跑训练集,属于基础操作。
思路:数据探索,做一点点的修改-->数据清洗(空值的填充)-->数据预处理(数据的归一化,标准化等)-->模型构建-->训练预测--->保存提交
但是其中的数据清洗的学问值得一看
代码部分
导入相应的包
#导入相应的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns #数据可视化 类似Matplotlib
import pandas_profiling as ppf#进行数据探索性分析
import warnings#忽略警告
warnings.filterwarnings("ignore")
%matplotlib inline
plt.style.use("ggplot")
原始数据导入---这里的数据都是在比赛的官网下载得到的
train = pd.read_csv("data_set/train.csv")#读取训练数据
test = pd.read_csv("data_set/test.csv")#读取测试集数据
train.head()#默认显示前五行 该函数是显示数据表的函数
数据探索性分析---EDA
由pandas_profiling库提供的数据探索性分析,可以对数据进行预先的分析,寻找数据之间的相关性
# ppf.ProfileReport(train)# 主要是查看特征之间的相关性--Correlations 分析的时候才会用这段代码
该图就是数据探索性分析生成的数据相关性图
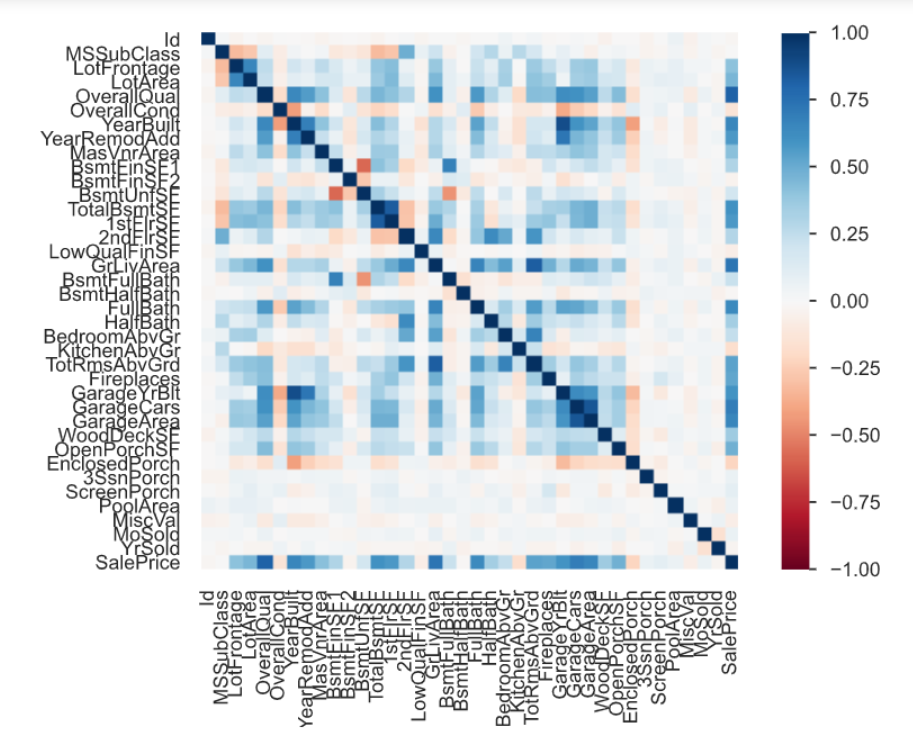
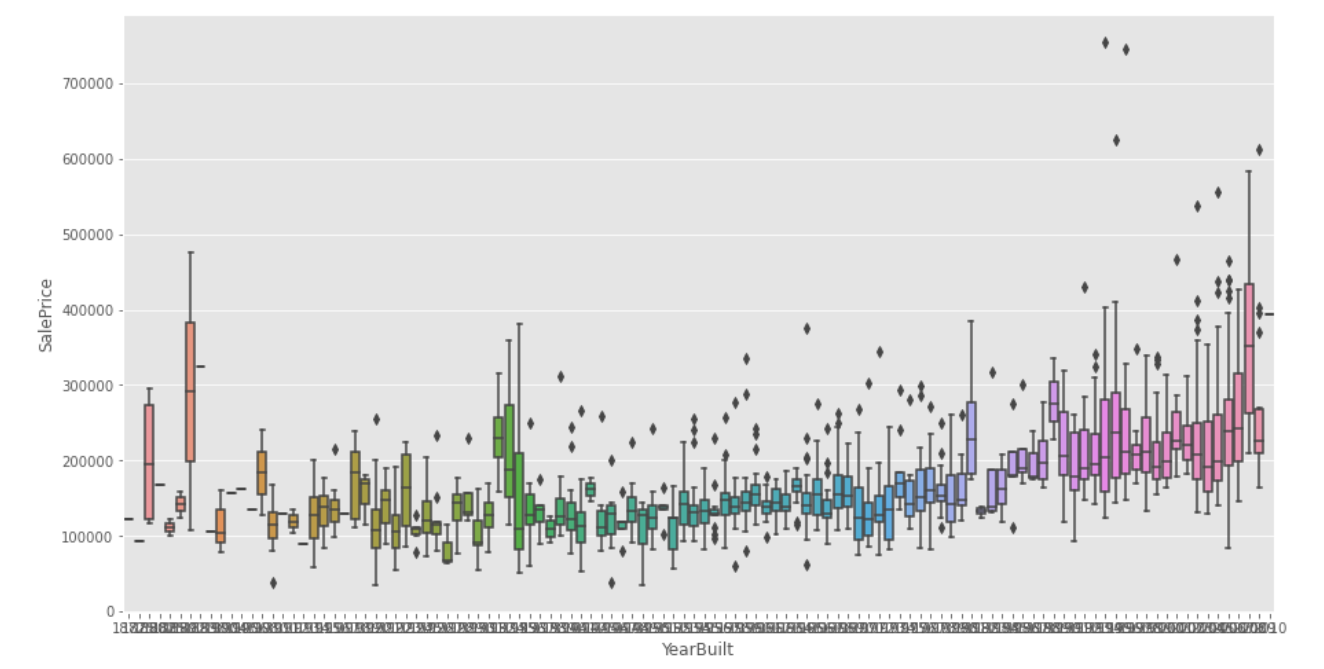
下面也可以通过绘制箱型图来看两个属性之间的关系
#属于探索性数据分析
plt.figure(figsize=(15,8))
sns.boxplot(train.YearBuilt,train.SalePrice)#统计数据可视化,绘制箱型图 看建造年份和房价之间的关系
#箱型图是看异常值的,找出离群的点
下面是散点图,用来判断是否有线性关系的
其实当我们拿到这个房价预测问题的时候,就知道他是一个线性回归的问题(因为它是连续值)
#matplotlib绘制图像的库
plt.figure(figsize=(12,6))
plt.scatter(x=train.GrLivArea,y=train.SalePrice)#散点图用来观察是否存在线性的关系
plt.xlabel("GrLivArea",fontsize=13)
plt.ylabel("SalePrice",fontsize=13)
plt.ylim(0,800000)
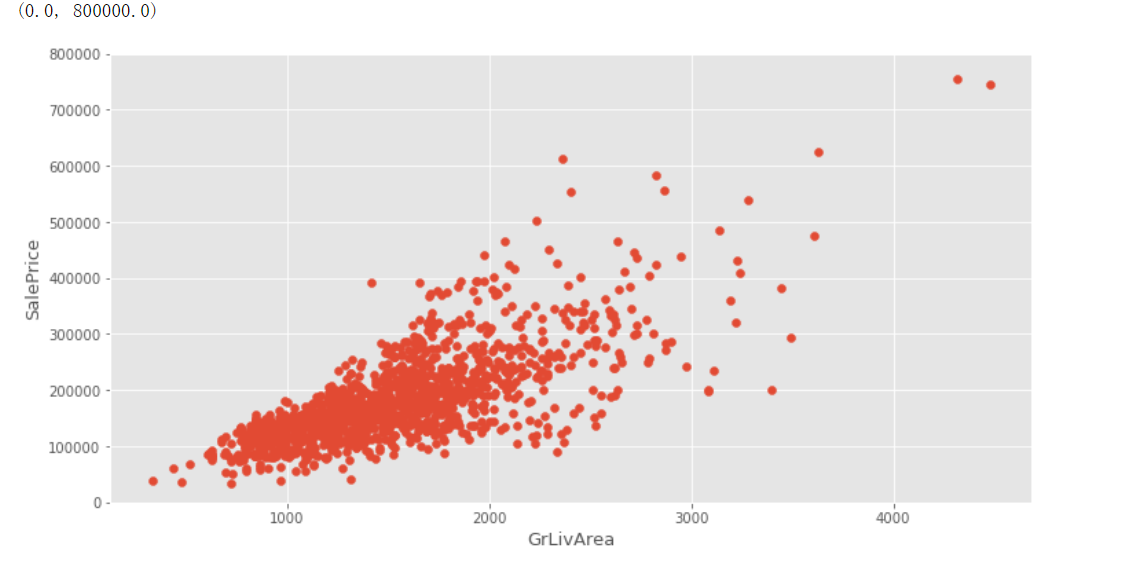
从图中可以看出,存在一些过于偏离直线的点,所以说需要对其进行裁剪
****所以得删除GrLivArea大于4000的点,即删除了右下角的点----删除训练集里面不大好的数据
#删除表中的某一行或者某一列更明智的方法是使用drop,它不改变原有的df中的数据,而是返回另一个dataframe来存放删除后的数据
##凡是会对原数组作出修改并返回一个新数组的,往往都有一个 inplace可选参数。
#如果手动设定为True(默认为False),那么原数组直接就被替换。也就是说,采用inplace=True之后,原数组名(如2和3情况所示)对应的内存值直接改变;
train.drop(train[
(train["GrLivArea"]>4000)&(train["SalePrice"]<300000)
].index,inplace=True)#index为数组的自带的索引即行号 pandas里面的条件删除
full = pd.concat([train,test],ignore_index=True)#合并数组---为了把train和test里面的脏数据一起处理了
full.drop("Id",axis=1,inplace=True)#删除第一列Id
数据清洗 (空值的填充、空值的删除、不处理)
寻找空值
##查看缺失值
miss = full.isnull().sum()#统计有多少个空值 返回的的类型为pandas.core.series.Series 是一种带标签的一维数组 类似字典
#把[miss>0]当一种限定条件看
miss[miss>0].sort_values(ascending=False)#把miss>0的数据,从大到小排序
#这里虽然知道是空,但是不知道空的是字符类型的值还是数字类型的值,
# 所以下面就得进行分类填充 通过full.info()查看数据类型,下面就进行分类填充
# full.info()
空值的填充
字符串用NULL填充,数字类型可以用0也可以用别的均值,众数来填充,根据情况来
#对字符类型的进行填充
cols1 = ["PoolQC" , "MiscFeature", "Alley", "Fence", "FireplaceQu", "GarageQual", "GarageCond", "GarageFinish", "GarageYrBlt", "GarageType", "BsmtExposure", "BsmtCond", "BsmtQual", "BsmtFinType2", "BsmtFinType1", "MasVnrType"]
for col in cols1:
full[col].fillna("None",inplace=True)
#对数值类型的进行填充
cols=["MasVnrArea", "BsmtUnfSF", "TotalBsmtSF", "GarageCars", "BsmtFinSF2", "BsmtFinSF1", "GarageArea"]
for col in cols:
full[col].fillna(0, inplace=True)
#对lotfrontage的空值进行填充(用这一列的均值)
full["LotFrontage"].fillna(np.mean(full["LotFrontage"]),inplace=True)
#对这些列进行众数填充 这里的也是object类型
cols2 = ["MSZoning", "BsmtFullBath", "BsmtHalfBath", "Utilities", "Functional", "Electrical", "KitchenQual", "SaleType","Exterior1st", "Exterior2nd"]
#full[col].mode()[0] 众数
for col in cols2:
full[col].fillna(full[col].mode()[0], inplace=True)
#查看哪些是还没填充好的,发现只有test数据集的没有SalePrice列
full.isnull().sum()[full.isnull().sum()>0]##至此我们已经把空值填充好了
数据预处理--字符变成数值型这是很重要的
将一些数字特征转换为类别特征。最好使用LabelEncoder和get_dummies来实现这些功能。
for col in cols2:
full[col]=full[col].astype(str)##astype对cols2中的数据进行数据转换成字符串类型
#类别数据数字化 encoder
#可以将数据集中的文本转化成0或1的数值
#例如存在 A B两种类型的str,直接将这两种转变成0或1
#A--0 B--1 将str转换成int
from sklearn.preprocessing import LabelEncoder
lab = LabelEncoder()
#将下列字符型数据都转换成数字型数据
full["Alley"] = lab.fit_transform(full.Alley)
full["PoolQC"] = lab.fit_transform(full.PoolQC)
full["MiscFeature"] = lab.fit_transform(full.MiscFeature)
full["Fence"] = lab.fit_transform(full.Fence)
full["FireplaceQu"] = lab.fit_transform(full.FireplaceQu)
full["GarageQual"] = lab.fit_transform(full.GarageQual)
full["GarageCond"] = lab.fit_transform(full.GarageCond)
full["GarageFinish"] = lab.fit_transform(full.GarageFinish)
full["GarageYrBlt"] = full["GarageYrBlt"].astype(str)
full["GarageYrBlt"] = lab.fit_transform(full.GarageYrBlt)
full["GarageType"] = lab.fit_transform(full.GarageType)
full["BsmtExposure"] = lab.fit_transform(full.BsmtExposure)
full["BsmtCond"] = lab.fit_transform(full.BsmtCond)
full["BsmtQual"] = lab.fit_transform(full.BsmtQual)
full["BsmtFinType2"] = lab.fit_transform(full.BsmtFinType2)
full["BsmtFinType1"] = lab.fit_transform(full.BsmtFinType1)
full["MasVnrType"] = lab.fit_transform(full.MasVnrType)
full["BsmtFinType1"] = lab.fit_transform(full.BsmtFinType1)
#对col2进行字符型数据转换成数字型数据
full["MSZoning"] = lab.fit_transform(full.MSZoning)
full["BsmtFullBath"] = lab.fit_transform(full.BsmtFullBath)
full["BsmtHalfBath"] = lab.fit_transform(full.BsmtHalfBath)
full["Utilities"] = lab.fit_transform(full.Utilities)
full["Functional"] = lab.fit_transform(full.Functional)
full["Electrical"] = lab.fit_transform(full.Electrical)
full["KitchenQual"] = lab.fit_transform(full.KitchenQual)
full["SaleType"] = lab.fit_transform(full.SaleType)
full["Exterior1st"] = lab.fit_transform(full.Exterior1st)
full["Exterior2nd"] = lab.fit_transform(full.Exterior2nd)
#这里会发现仍然存在字符类型的数据
full.head()
# 将大表变成训练时候的输入X 线性回归模型 函数y=k*x
full.drop("SalePrice",axis=1,inplace=True)##删除
# 将离散型特征使用one-hot编码,
# 会让特征之间的距离计算更加合理
full2 = pd.get_dummies(full)##独热编码
#处理好的数据
full2.shape
#可以看出都变成数字型了
full2.head()
数据集预处理--为模型构建做准备
from sklearn.preprocessing import RobustScaler, StandardScaler#去除异常值与数据标准化
n_train = train.shape[0]#行数
#划分数据集
#将其分为一个函数y=k*x X是自变量 y是结果
X = full2[:n_train]#相当于取出X 行切分
y = train.SalePrice#取出训练集的标签 一列
#进行实例化 进行归一化和标准化
# 目的:减少坐标直接的差异 让x的值在[0,1]之间
# 归一化是让不同维度之间的特征在数值上有一定比较性
std = StandardScaler()
X_scaled = std.fit_transform(X)
# y = np.log(y)#训练集的一个数据分布
test_x = full2[n_train:]#截取测试集部分 1461行之后的
#这里其实是不需要进行归一化和标准化的,归一化和标准化之后跑出来的结果有问题
模型构建
#导入线性回归模型
from sklearn.linear_model import LinearRegression #导入模型
#模型定义
model = LinearRegression()
#开始训练模型
# model1 = model.fit(X_scaled,y)
model1 = model.fit(X,y)
预测
predict = model1.predict(test_x)
result = pd.DataFrame({'Id':test.Id,'SalePrice':predict})
result.to_csv("submission1.csv",index=False)
最终结果
最终会生成的csv文件提交之后的成绩如下

结果不是很好,毕竟只用了很简单的方法,但是这是一个很好的开端,后面将会接着进行学习,来改进这个方法。
思考
后面学了再说吧