A Discriminative CNN Video Representation for Event Detection
Note here: it's a learning note on the topic of video representation, based on the paper below.
Link: http://arxiv.org/pdf/1411.4006v1.pdf
Motivation:
The use of improved Dense Trajectories (IDT) has led good performance on the task of event detection, while the performance of CNN based video representation is worse than that. The author argues the following three main reasons:
- Lack of labeled video data to train good models.
- Video level event labels are too coarse to finetune a pre-trained model for adapting the event detection task.
- The use of average pooling to generate a discriminative video level representation from CNN frame level descriptors works worse than hand-crafted features like IDT.
Proposed Model:
This paper proposes a model mainly targetting at the third problem, namely how to build a cost-efficient and discrimintive video representation based on CNN.
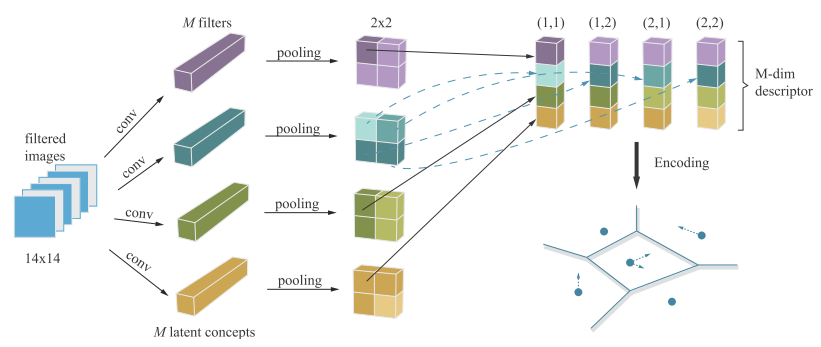
1) Firstly, we should extract frame-level descriptor:
We adopt M filters in the last convolutional layers as M latent concept classifiers. Each convolutional filter is corresponding to one latent concept, and each of it will apply on different location of the frame. So we’ll get responses of discrimintive latent concepts on different locations of the frame.
After that, we apply max-pooling operation on all concepts descriptors and concatenate different responses at the same location to form vectors each of which containing various concepts descriptions at this location.
By now, we’ve extract frame-level features.
(Actually, they didn’t do anything special at this step, they just give a new illustration of responses in CNN and rearrange those responses for further process.)
2) Secondly, we need to encode a discrimintive video-level descriptor from all these frame-level descriptors:
They introduce and compare three different encoding methods in the paper.
However, as I’m not proficient in the mathematical meanings of them, I can just give a briefly look at them instead of going further.
- Fisher Vector Encoding (refer to: http://blog.csdn.net/breeze5428/article/details/32706507 & http://www.cnblogs.com/CBDoctor/archive/2011/11/06/2236286.html)
- VLAD Encoding (simplified version of Fisher Vector Encoding)
- Average Pooling
Through experiment, they find out VLAD is better than other encoding methods. (You can refer to the paper for details about that experiment.)
"This is the first work on the video pooling of CNN descriptors and we broaden the encoding methods from local descriptors to CNN descriptors in video analysis."
(That's the takeaway in their work. They're the first to apply these encoding methods on the CNN descriptors. Previously, most of the works utilize Fisher Vector Encoding to encode a general feature of an image from local descriptors like HOG, SIFT, HOF and so on.)
3) Lastly, we get a video-level descriptor and feed it into a SVM to do detection task.
Two Tricks:
1) Spatial Pyramid Pooling: they apply four different CNN max-pooling operations to give more spatial locations for a single frame, which makes the descriptor more discrimintive. And that’s also more cost-friendly than applying spatial pyramid on raw frame.
2) Representation Compression: they do Product Quntization to compress the final representation while still maintain or even slightly improve the original performance.