1.官网
http://spark.apache.org/docs/1.6.1/configuration.html#shuffle-behavior
Spark数据进行重新分区的操作就叫做shuffle过程

2.介绍
SparkStage划分的时候,将最后一个Stage称为ResultStage(ResultTask),其它Stage叫做ShuffleMapStage(ShuffleMapTask)

3.SparkShuffle实现
基于ShuffleManager来实现,1.6.1版本中存在两种实现:HashShuffleManager和SortShuffleManager(默认);
由参数spark.shuffle.manager决定(sort or hash)
其中,sort:类似MR的shuffle,如下:
4.hash shuffle
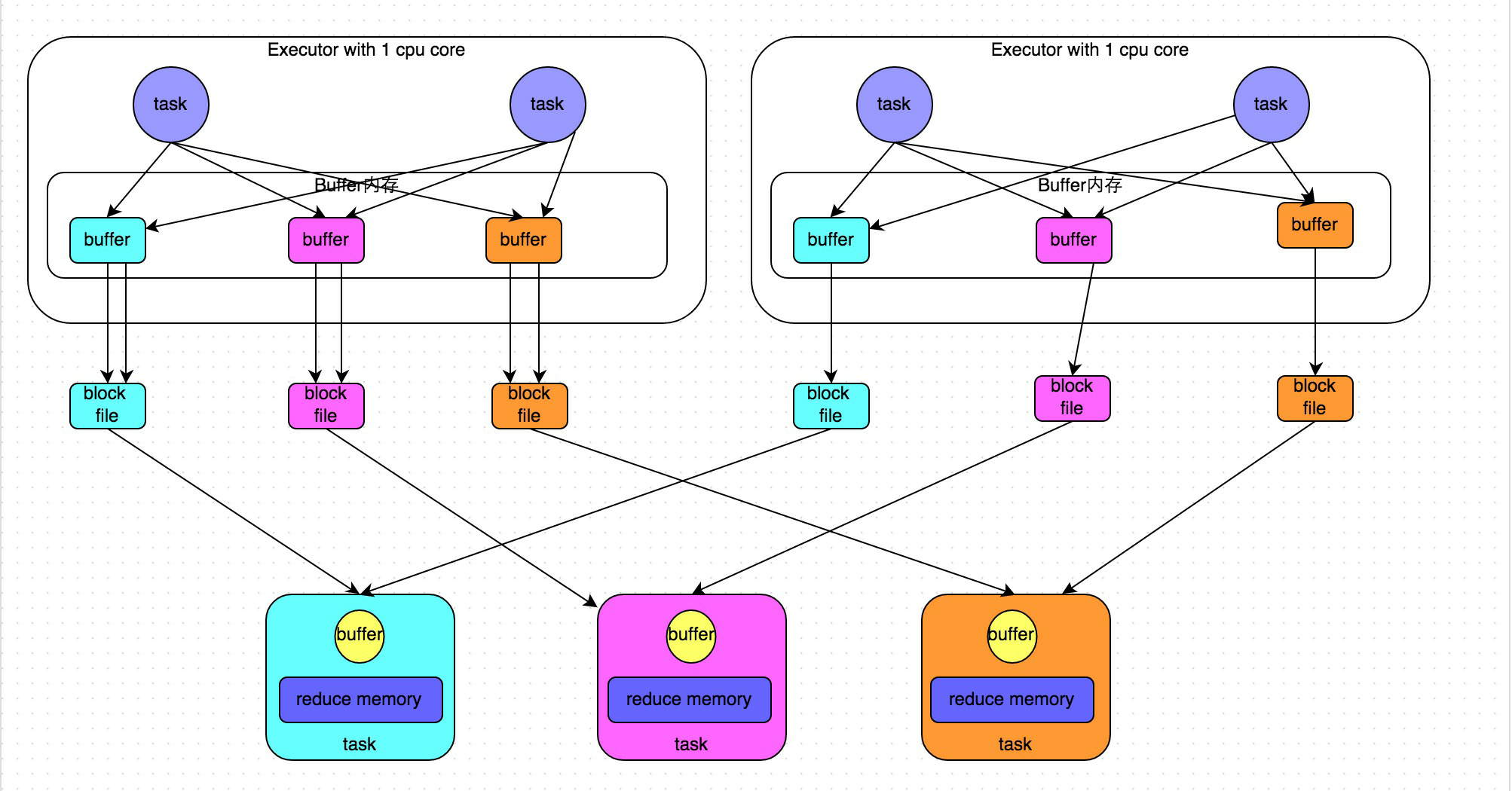
在Spark1.2.x版本之前,只有一个ShuffleManager,就是hash
hash shuffle在以前的版本中存在一个问题:
会产生大量的磁盘问题
优化:
将一个Executor上的所有Task的执行结果合并到一起,减少文件的数量
spark.shuffle.consoldateFiles=true
原hash下的原理:

优化原理:
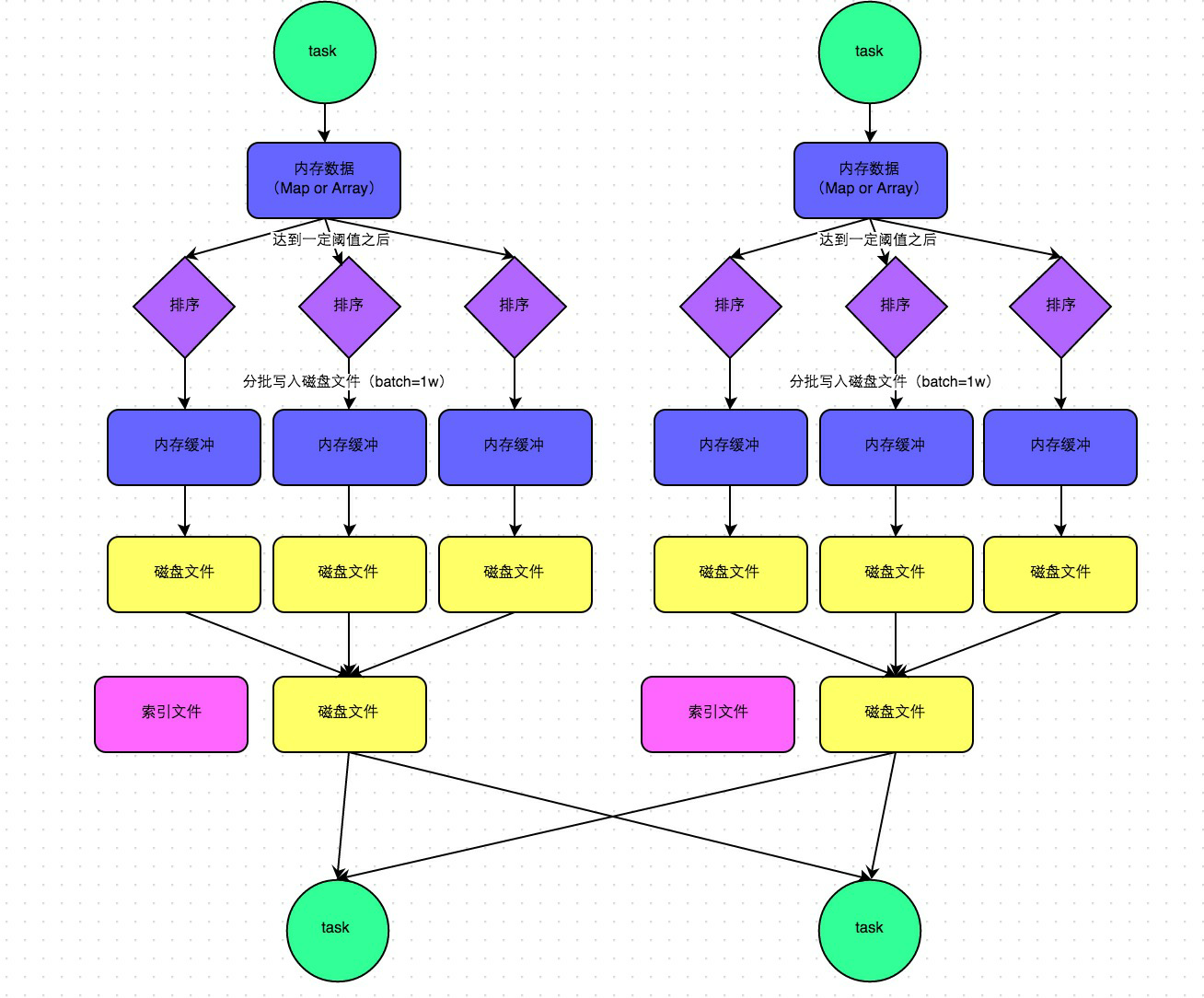
5.sort shuffle
在1.2版本之后,默认是SortManager,就是sort
小问题:所有的情况都进行排序(不管数据量的大小)<通过bypass运行模式可以解决>
两种运行:
普通运行模式:
中间会涉及到sort操作
bypass运行模式:
针对小数据量的情况下,不进行排序,类似于优化后的HashManager(性能没有HashManager<优化后>高)
下面是两个条件,就会走bypass模式,小数据量不排序:
-1. 当RDD的task数量小于spark.shuffle.sort.bypassMergeThreshold(默认200)的时候启用
-2. 不是聚合类shuffle算子(比如:不能是reduceByKey,可以是join)
二:shuffle与依赖的关系
1.说明
在后面补充一下知识点
2.关系
