Restful风格API中用put还是post做新增操作有什么区别?
转
<div class="content" id="articleContent">
<div class="ad-wrap">
<p style="margin:0 0 10px 0;"><a data-traceid="blog_detail_above_text_link_1" data-tracepid="blog_detail_above_text_link" style="color:#A00;font-weight:bold;" href="https://my.oschina.net/u/2663968/blog/3109540" target="_blank">头条面试归来,有些话想和Java开发者说!>>> </a> <img src="https://www.oschina.net/img/hot3.png" align="absmiddle" style="max-height: 32px; max- 32px;"></p>
</div>
<p><span style="color:#2E2E2E">这个是华为面试官问我的问题,回来我找了很多资料,想验证这个问题。在回答问题之前,还需要搜集一些基础知识。</span></p>
1 HTTP协议详解
HTTP是HyperText Transfer Protocol(超文本传输协议)的缩写。它的发展是万维网协会(WorldWide Web Consortium)和Internet工作小组IETF(Internet Engineering Task Force)合作的结果,(他们)最终发布了一系列的RFC,RFC 1945定义了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC 2616定义了今天普遍使用的一个版本——HTTP 1.1。
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。
HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上,这个时候,就成了我们常说的HTTPS。如下图所示:

默认HTTP的端口号为80,HTTPS的端口号为443。
HTTP协议永远都是客户端发起请求,服务器回送响应。见下图:
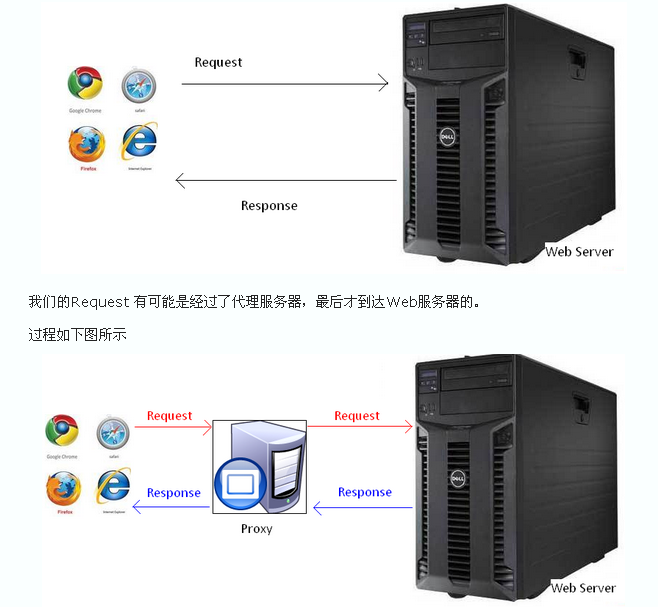
这样就限制了使用HTTP协议,无法实现在客户端没有发起请求的时候,服务器将消息推送给客户端。
HTTP协议是一个无状态的协议,同一个客户端的这次请求和上次请求是没有对应关系。
一次HTTP操作称为一个事务,其工作过程可分为四步:
1)首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
2)建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
3)服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
4)客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要用鼠标点击,等待信息显示就可以了。
2 HTTP协议详解之请求篇
http请求由三部分组成,分别是:请求行、消息报头、请求正文
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本,格式如下:Method Request-URIHTTP-Version CRLF
其中 Method表示请求方法;Request-URI是一个统一资源标识符;HTTP-Version表示请求的HTTP协议版本;CRLF表示回车和换行(除了作为结尾的CRLF外,不允许出现单独的CR或LF字符)。
请求方法(所有方法全为大写)有多种,各个方法的解释如下:
GET 请求获取Request-URI所标识的资源
POST 在Request-URI所标识的资源后附加新的数据
HEAD 请求获取由Request-URI所标识的资源的响应消息报头
PUT 请求服务器存储一个资源,并用Request-URI作为其标识
DELETE 请求服务器删除Request-URI所标识的资源
TRACE 请求服务器回送收到的请求信息,主要用于测试或诊断
CONNECT 保留将来使用
OPTIONS 请求查询服务器的性能,或者查询与资源相关的选项和需求
应用举例:
GET方法:在浏览器的地址栏中输入网址的方式访问网页时,浏览器采用GET方法向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)
POST方法要求被请求服务器接受附在请求后面的数据,常用于提交表单。
HEAD方法与GET方法几乎是一样的,对于HEAD请求的回应部分来说,它的HTTP头部中包含的信息与通过GET请求所得到的信息是相同的。利用这个方法,不必传输整个资源内容,就可以得到Request-URI所标识的资源的信息。该方法常用于测试超链接的有效性,是否可以访问,以及最近是否更新。
3 HTTP协议详解之响应篇
在接收和解释请求消息后,服务器返回一个HTTP响应消息。
HTTP响应也是由三个部分组成,分别是:状态行、消息报头、响应正文
1、状态行格式如下:
HTTP-VersionStatus-Code Reason-Phrase CRLF
其中,HTTP-Version表示服务器HTTP协议的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示请求已接收,继续处理
2xx:成功--表示请求已被成功接收、理解、接受
3xx:重定向--要完成请求必须进行更进一步的操作
4xx:客户端错误--请求有语法错误或请求无法实现
5xx:服务器端错误--服务器未能实现合法的请求
2、常见状态代码、状态描述、说明:
请求收到,继续处理
100——客户必须继续发出请求
101——客户要求服务器根据请求转换HTTP协议版本
操作成功收到,分析、接受
200——交易成功
201——提示知道新文件的URL
202——接受和处理、但处理未完成
203——返回信息不确定或不完整
204——请求收到,但返回信息为空
205——服务器完成了请求,用户代理必须复位当前已经浏览过的文件
206——服务器已经完成了部分用户的GET请求
完成此请求必须进一步处理
300——请求的资源可在多处得到
301——删除请求数据
302——在其他地址发现了请求数据
303——建议客户访问其他URL或访问方式
304——客户端已经执行了GET,但文件未变化
305——请求的资源必须从服务器指定的地址得到
306——前一版本HTTP中使用的代码,现行版本中不再使用
307——申明请求的资源临时性删除
请求包含一个错误语法或不能完成
400——错误请求,如语法错误
401——未授权
HTTP 401.1 - 未授权:登录失败
HTTP 401.2 - 未授权:服务器配置问题导致登录失败
HTTP 401.3 - ACL 禁止访问资源
HTTP 401.4 - 未授权:授权被筛选器拒绝
HTTP 401.5 - 未授权:ISAPI 或 CGI 授权失败
402——保留有效ChargeTo头响应
403——禁止访问
HTTP 403.1 禁止访问:禁止可执行访问
HTTP 403.2 - 禁止访问:禁止读访问
HTTP 403.3 - 禁止访问:禁止写访问
HTTP 403.4 - 禁止访问:要求 SSL
HTTP 403.5 - 禁止访问:要求 SSL128
HTTP 403.6 - 禁止访问:IP 地址被拒绝
HTTP 403.7 - 禁止访问:要求客户证书
HTTP 403.8 - 禁止访问:禁止站点访问
HTTP 403.9 - 禁止访问:连接的用户过多
HTTP 403.10 - 禁止访问:配置无效
HTTP 403.11 - 禁止访问:密码更改
HTTP 403.12 - 禁止访问:映射器拒绝访问
HTTP 403.13 - 禁止访问:客户证书已被吊销
HTTP 403.15 - 禁止访问:客户访问许可过多
HTTP 403.16 - 禁止访问:客户证书不可信或者无效
HTTP 403.17 - 禁止访问:客户证书已经到期或者尚未生效
404——没有发现文件、查询或URl
405——用户在Request-Line字段定义的方法不允许
406——根据用户发送的Accept拖,请求资源不可访问
407——类似401,用户必须首先在代理服务器上得到授权
408——客户端没有在用户指定的饿时间内完成请求
409——对当前资源状态,请求不能完成
410——服务器上不再有此资源且无进一步的参考地址
411——服务器拒绝用户定义的Content-Length属性请求
412——一个或多个请求头字段在当前请求中错误
413——请求的资源大于服务器允许的大小
414——请求的资源URL长于服务器允许的长度
415——请求资源不支持请求项目格式
416——请求中包含Range请求头字段,在当前请求资源范围内没有range指示值,请求也不包含If-Range请求头字段
417——服务器不满足请求Expect头字段指定的期望值,如果是代理服务器,可能是下一级服务器不能满足请求长。
服务器执行一个完全有效请求失败
HTTP 500 - 内部服务器错误
HTTP 500.100 - 内部服务器错误 -ASP 错误
HTTP 500-11 服务器关闭
HTTP 500-12 应用程序重新启动
HTTP 500-13 - 服务器太忙
HTTP 500-14 - 应用程序无效
HTTP 500-15 - 不允许请求 global.asa
Error 501 - 未实现
HTTP 502 - 网关错误
HTTP 500.100 - 内部服务器错误 -ASP 错误
HTTP 500-11 服务器关闭
HTTP 500-12 应用程序重新启动
HTTP 500-13 - 服务器太忙
HTTP 500-14 - 应用程序无效
HTTP 500-15 - 不允许请求 global.asa
Error 501 - 未实现
HTTP 502 - 网关错误
4 API设计的基本要求
一个被普遍承认和遵守:RESTful设计原则。它被Roy Felding提出(在他的”基于网络的软件架构“论文中第五章)。而REST的核心原则是将你的API拆分为逻辑上的资源。这些资源通过http被操作(GET ,POST,PUT,DELETE)。
显然从API用户的角度来看,”资源“应该是个名词。即使你的内部数据模型和资源已经有了很好的对应,API设计的时候你仍然不需要把它们一对一的都暴露出来。这里的关键是隐藏内部资源,暴露必需的外部资源。
一旦定义好了要暴露的资源,你可以定义资源上允许的操作,以及这些操作和你的API的对应关系:
· GET /tickets # 获取ticket列表
· GET /tickets/12 # 查看某个具体的ticket
· POST /tickets # 新建一个ticket
· PUT /tickets/12 # 更新ticket 12.
· DELETE /tickets/12 #删除ticekt 12
可以看出使用REST的好处在于可以充分利用http的强大实现对资源的CURD功能。而这里你只需要一个endpoint:/tickets,再没有其他什么命名规则和url规则了,cool!
但是有的endpoint,需要使用复数使得你的URL更加规整。这让API使用者更加容易理解,对开发者来说也更容易实现。
如何处理关联?关于如何处理资源之间的管理REST原则也有相关的描述:
· GET /tickets/12/messages- Retrieves list of messages forticket #12
· GET /tickets/12/messages/5- Retrieves message #5 forticket #12
· POST /tickets/12/messages- Creates a new message inticket #12
· PUT /tickets/12/messages/5- Updates message #5 for ticket#12
· PATCH /tickets/12/messages/5- Partially updates message#5 for ticket #12
· DELETE /tickets/12/messages/5- Deletes message #5 forticket #12
其中,如果这种关联和资源独立,那么我们可以在资源的输出表示中保存相应资源的endpoint。然后API的使用者就可以通过点击链接找到相关的资源。如果关联和资源联系紧密。资源的输出表示就应该直接保存相应资源信息。(例如这里如果message资源是独立存在的,那么上面 GET/tickets/12/messages就会返回相应message的链接;相反的如果message不独立存在,他和ticket依附存在,则上面的API调用返回直接返回message信息)
5 get和post区别
常用的请求方式是GET和POST.
GET方式:是以实体的方式得到由请求URI所指定资源的信息,如果请求URI只是一个数据产生过程,那么最终要在响应实体中返回的是处理过程的结果所指向的资源,而不是处理过程的描述。
POST方式:用来向目的服务器发出请求,要求它接受被附在请求后的实体,并把它当作请求队列中请求URI所指定资源的附加新子项,Post被设计成用统一的方法实现下列功能:
1)对现有资源的解释;
2)向电子公告栏、新闻组、邮件列表或类似讨论组发信息;
3)提交数据块;
4)通过附加操作来扩展数据库 。
从上面描述可以看出,Get是向服务器发索取数据的一种请求;而Post是向服务器提交数据的一种请求,要提交的数据位于信息头后面的实体中。
GET与POST方法有以下区别:
1) 在客户端,Get方式在通过URL提交数据,数据在URL中可以看到;POST方式,数据放置在HTMLHEADER内提交。
2) GET方式提交的数据最多只能有1024字节,而POST则没有此限制。
3) 安全性问题。正如在(1)中提到,使用 Get 的时候,参数会显示在地址栏上,而 Post 不会。所以,如果这些数据是中文数据而且是非敏感数据,那么使用 get;如果用户输入的数据不是中文字符而且包含敏感数据,那么还是使用 post为好。
4) 安全的和幂等的。所谓安全的意味着该操作用于获取信息而非修改信息。幂等的意味着对同一 URL 的多个请求应该返回同样的结果。完整的定义并不像看起来那样严格。换句话说,GET 请求一般不应产生副作用。从根本上讲,其目标是当用户打开一个链接时,她可以确信从自身的角度来看没有改变资源。比如,新闻站点的头版不断更新。虽然第二次请求会返回不同的一批新闻,该操作仍然被认为是安全的和幂等的,因为它总是返回当前的新闻。反之亦然。POST 请求就不那么轻松了。POST 表示可能改变服务器上的资源的请求。仍然以新闻站点为例,读者对文章的注解应该通过 POST 请求实现,因为在注解提交之后站点已经不同了(比方说文章下面出现一条注解)。
6 put和post区别
有的观点认为,应该用POST来创建一个资源,用PUT来更新一个资源;有的观点认为,应该用PUT来创建一个资源,用POST来更新一个资源;还有的观点认为可以用PUT和POST中任何一个来做创建或者更新一个资源。这些观点都只看到了风格,争论起来也只是争论哪种风格更好,其实,用PUT还是POST,不是看这是创建还是更新资源的动作,这不是风格的问题,而是语义的问题。
举一个简单的例子,假如有一个博客系统提供一个Web API,模式是这样http://superblogging/blogs/{blog-name},很简单,将{blog-name}
替换为我们的blog名字,往这个URI发送一个HTTP PUT或者POST请求,HTTP的body部分就是博文,这是一个很简单的REST API例子。我们应该用
PUT方法还是POST方法?取决于这个REST服务的行为是否是idempotent的,假如我们发送两个http://superblogging/blogs/post/Sample请求,服
务器端是什么样的行为?如果产生了两个博客帖子,那就说明这个服务不是idempotent的,因为多次使用产生了副作用了嘛;如果后一个请求把第一个
请求覆盖掉了,那这个服务就是idempotent的。前一种情况,应该使用POST方法,后一种情况,应该使用PUT方法。
参考资料:
http://www.ruanyifeng.com/blog/2011/09/restful
http://kb.cnblogs.com/page/512047/
</div>
</div>
<div class="ui hidden divider"></div>
<p style="text-align:center;">
本文转载自:http://blog.csdn.net/chlu113/article/details/51853331
</p>
</div>php __call 与 __callStatic
js jquery提交表单不成功的问题原因
js 获取对象属性的各种方法
通达OA公共代码 php常用检测函数
php中session的用法
php中cookie的用法
php session_id() session_name()
禁用php函数的设置
盐值加密-MD5