运行架构
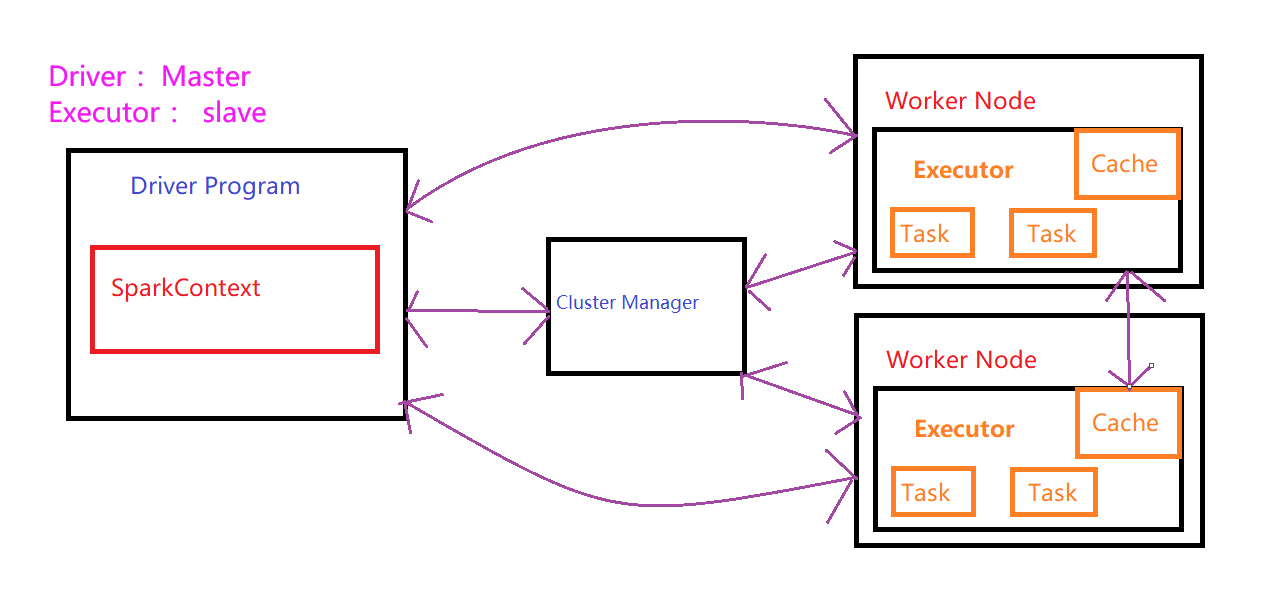
Spark的核心是一个计算引擎, 结构采用主从结构 即 master - slave 结构
Driver: 管理集群中作业任务调度
Executor : 实际执行任务
核心组件
Driver: 执行Spark任务中的main方法
1. 将写的程序转化为作业 Job
2. 在Executor之间调度任务 task
3. 跟踪 Executor 的执行情况
4. 通过 WebUI 查询运行情况
Executor : 集群工作节点Worker中的一个JVM进程
1. 负责在Spark中运行具体任务 (Task), 任务之间相互独立
2. 运行组成Spark应用的任务, 将结果返回给驱动器
3. 通过自身的块管理器 为用户程序中要求缓存的RDD提供内存式存储
4. RDD是直接缓存在Executor 进程内
Executor 是专门用来计算的节点,提交应用中提供参数指定计算节点的个数, 以及对应的资源
资源 ==> 工作节点Executor的内存大小 & 使用的CPU核数(core)
| 名称 | 说明 |
| --num-executors | 启动Executor的数量,默认为 2 |
| --executor-memory | 每个Executor的内存大小 默认为 1G |
| --executor-cores | 每个Executor的虚拟CPU核数 ( core ),默认为1,官方建议2-5 |
| --driver-cores | Driver使用的内核数 默认为 1 |
| --driver-memory | Driver的内存大小 默认为 512M |
Master 和 Worker:
master 类比 Yarn中 ResourceManager ; 管理集群中作业任务调度
worker 类比 Yarn中的 NodeManager ; 实际执行任务