基本概念
- 图是一种非线性的数据结构,相比树来说,更加复杂。
- 图的元素叫顶点,树的元素叫节点。
- 度:顶点相连的边的条数叫度。
图的分类有无向图、有向图、带权图
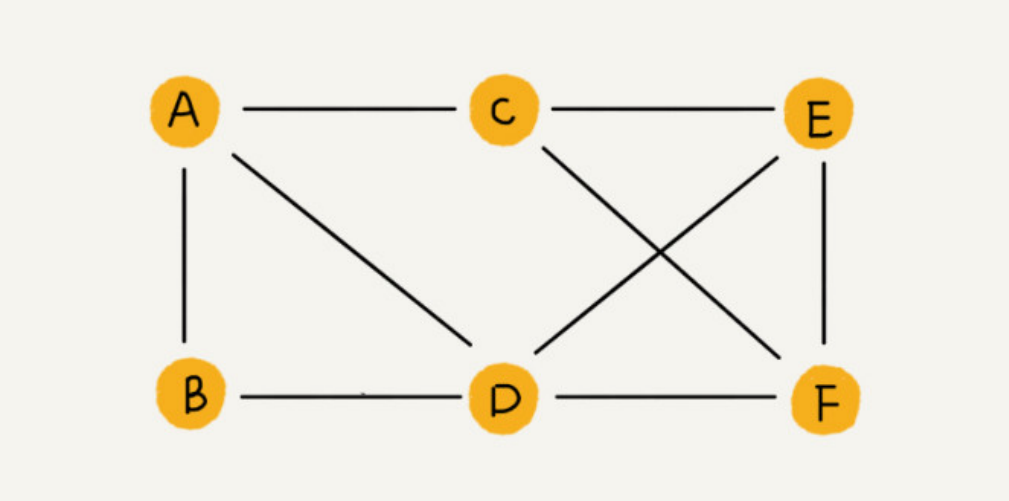
无向图
边没有方向的图员无向图。无向图中的顶点相连的边的条数叫度。例如微信上的好友关系。
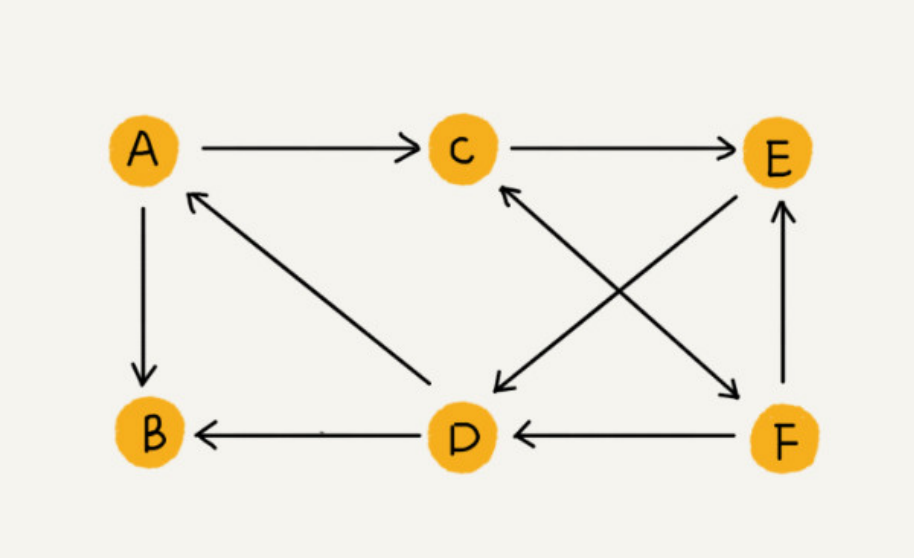
有向图
边有方向的图叫有向图。有向图中分为入度和出度。入度指终点为此顶点的边的条数;出度指始点为此顶点的边的条数。例如微博上的关注和粉丝关系。
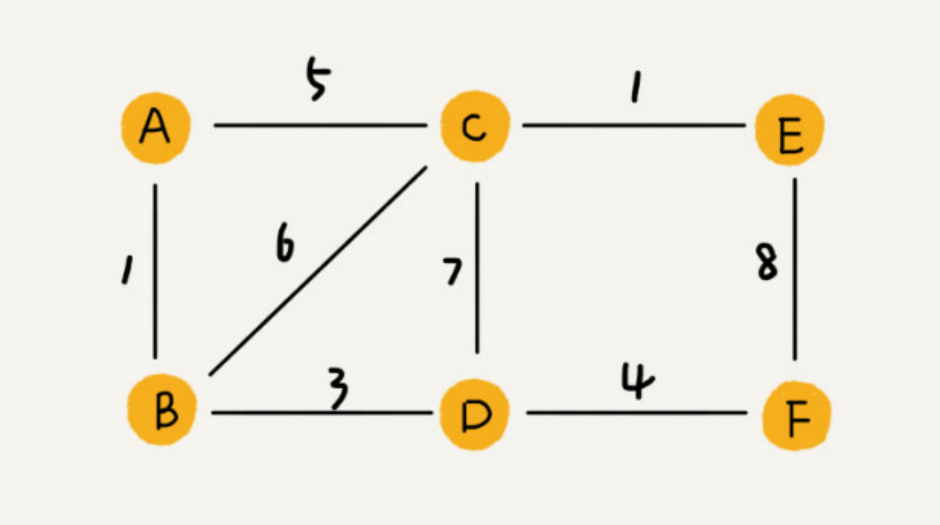
带权图
每条边都有一个权重的图叫带权图。例如QQ上与好友的亲密度。
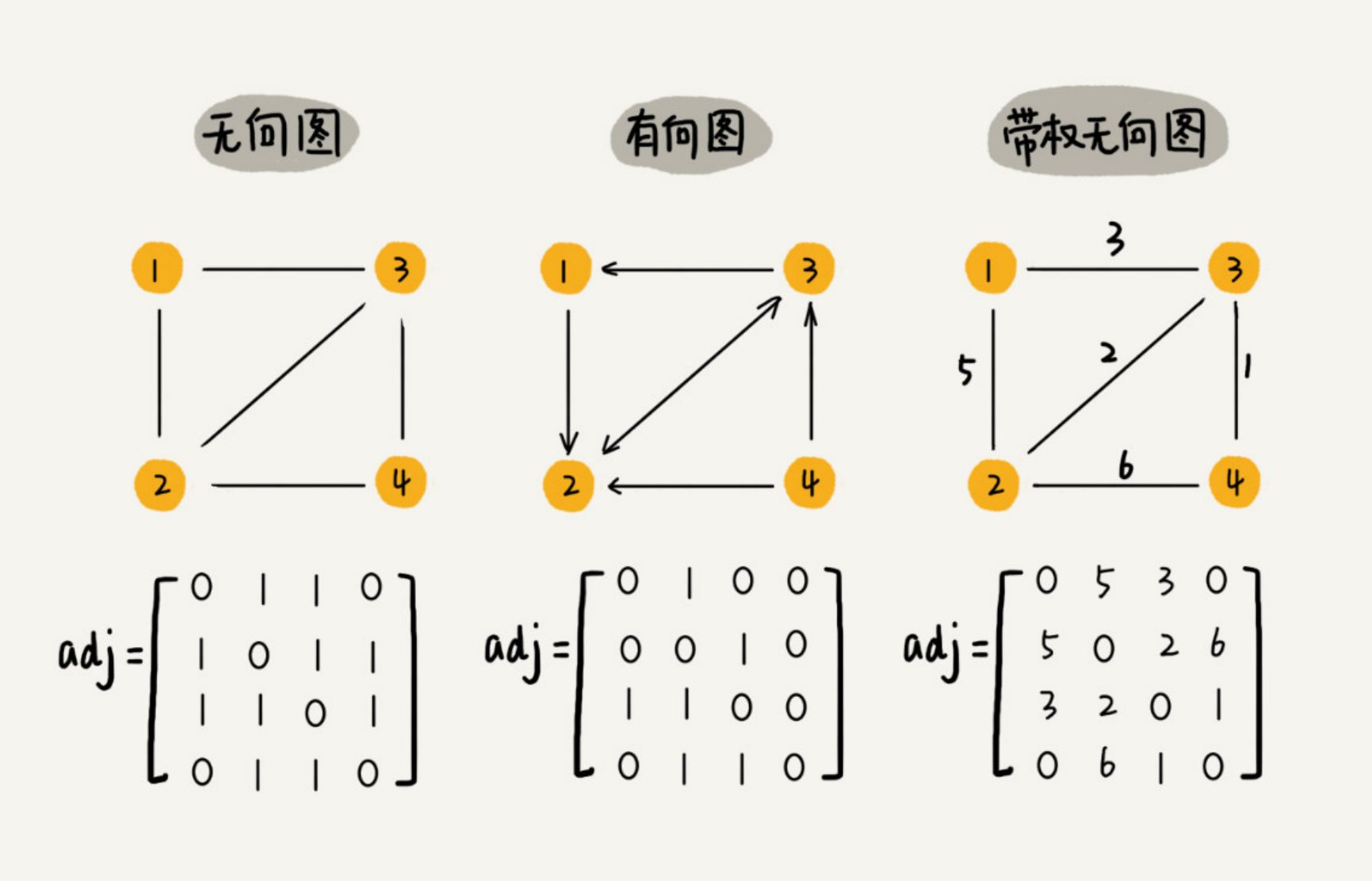
图的存储方式
图有两种存储方式,分别为邻接矩阵和邻接表。
邻接矩阵
通过二维数组来保存图的边。其中无向图(i, j)和(j, i)设置为1,有向图设置带方向的边,比如(i, j)设置为1,带权图把值设置为权重。
- 好处:存储简单、访问方便、方便计算
- 坏处:浪费空间
邻接表
每个顶点存储一个链表,存储的是这个顶点的相连的顶点。跟之前学过的散列表很像。每个顶点存储的是指向的顶点,无论是有向图还是无向图。
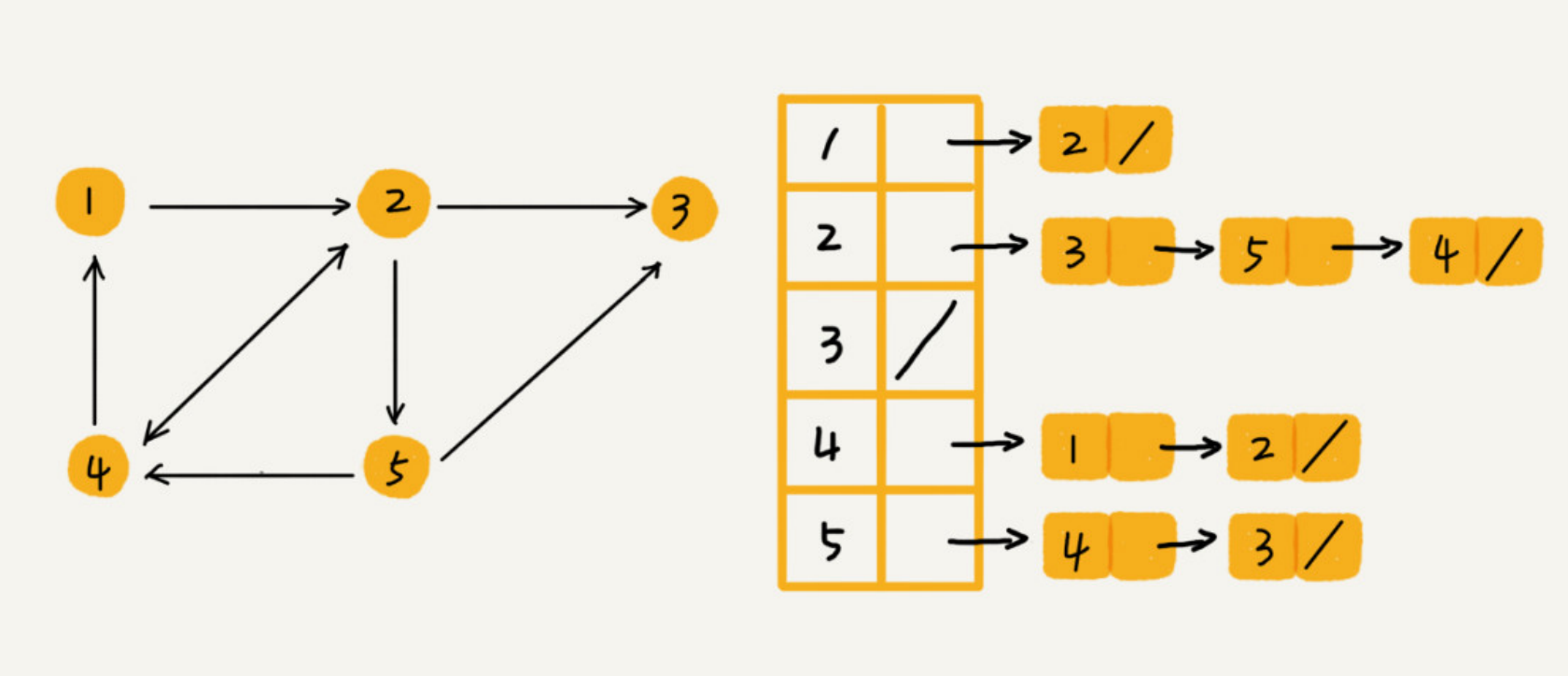
- 好处:节省空间
- 坏处:操作耗时
优化:通过对链表进行改造,使用跳表、散列表、平衡二叉树、红黑树等数据结构来优化。
案例分析
如何存储微博、微信等社交网络中的好友关系?
针对微博用户关系,假设我们需要支持下面这样几个操作:
- 判断用户A是否关注了用户B;
- 判断用户A是否是用户B的粉丝;
- 用户A关注用户B;
- 用户A取消关注用户B;
- 根据用户名称的首字母排序,分页获取用户的粉丝列表;
- 根据用户名称的首字母排序,分页获取用户的关注列表。
技术选型思路:
1、确定存储方式
因为社交关系是稀疏的,选择邻接表。
因为既要查看关注的,还要查看粉丝,因此除了使用邻接表,还需要逆邻接表。
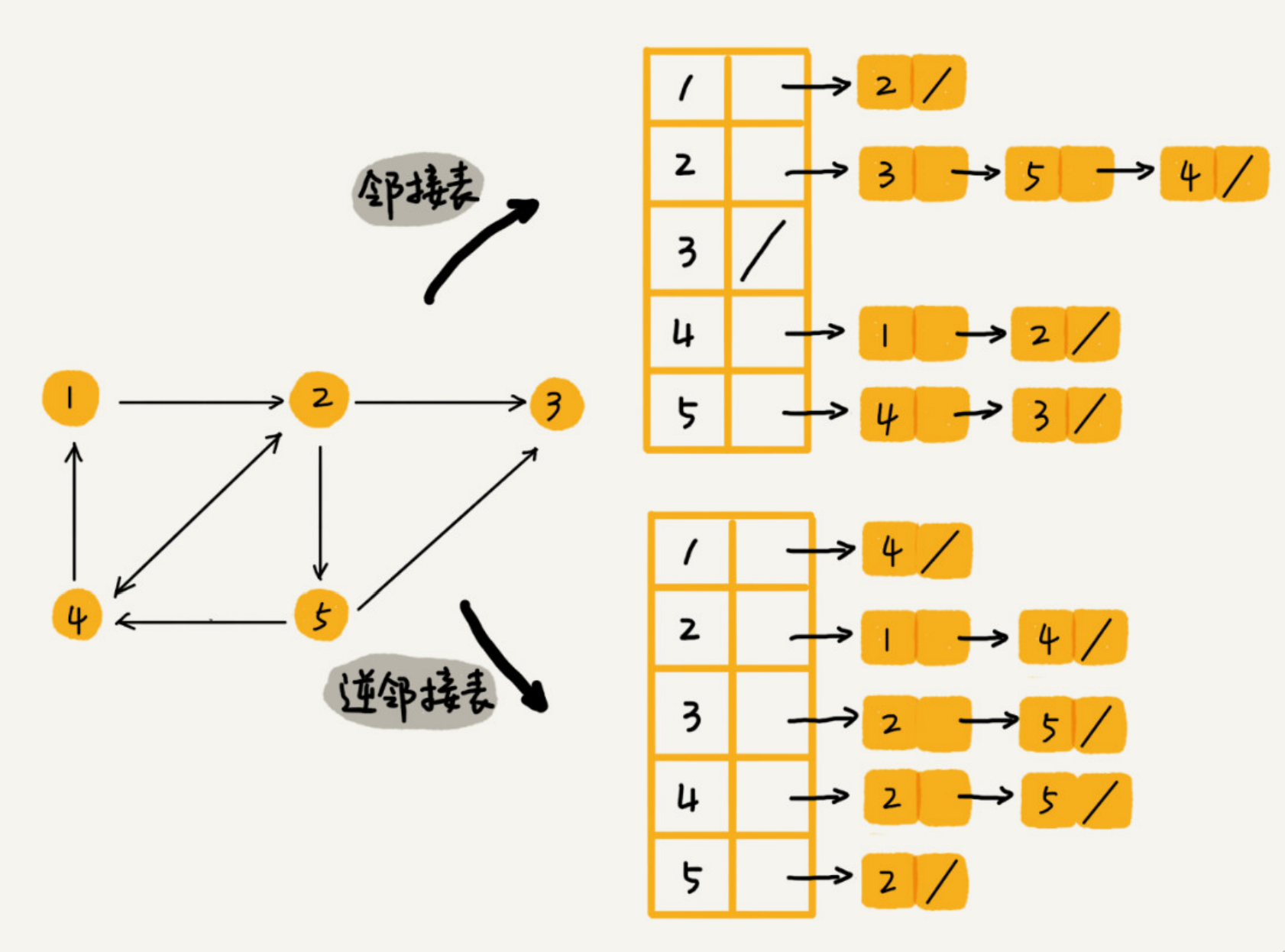
2、存储方式的底层数据结构
需要按用户名称首字母排序,并且要优化操作性能,因此选择跳表改造基础的邻接表,并且还有很重要的一点,跳表本身的数据是有序的。
3、确定数据规模
因为单个计算机资源是有限的,例如内存、磁盘空间。数据规模对存储方案有很大的影响。
对于小规模数据,几十万数据量,将邻接表直接保存到内存中。
对于大规模数据,数以亿计,就需要存储在多台服务器上。可使用哈希算法来计算用户存储在哪台服务器上。
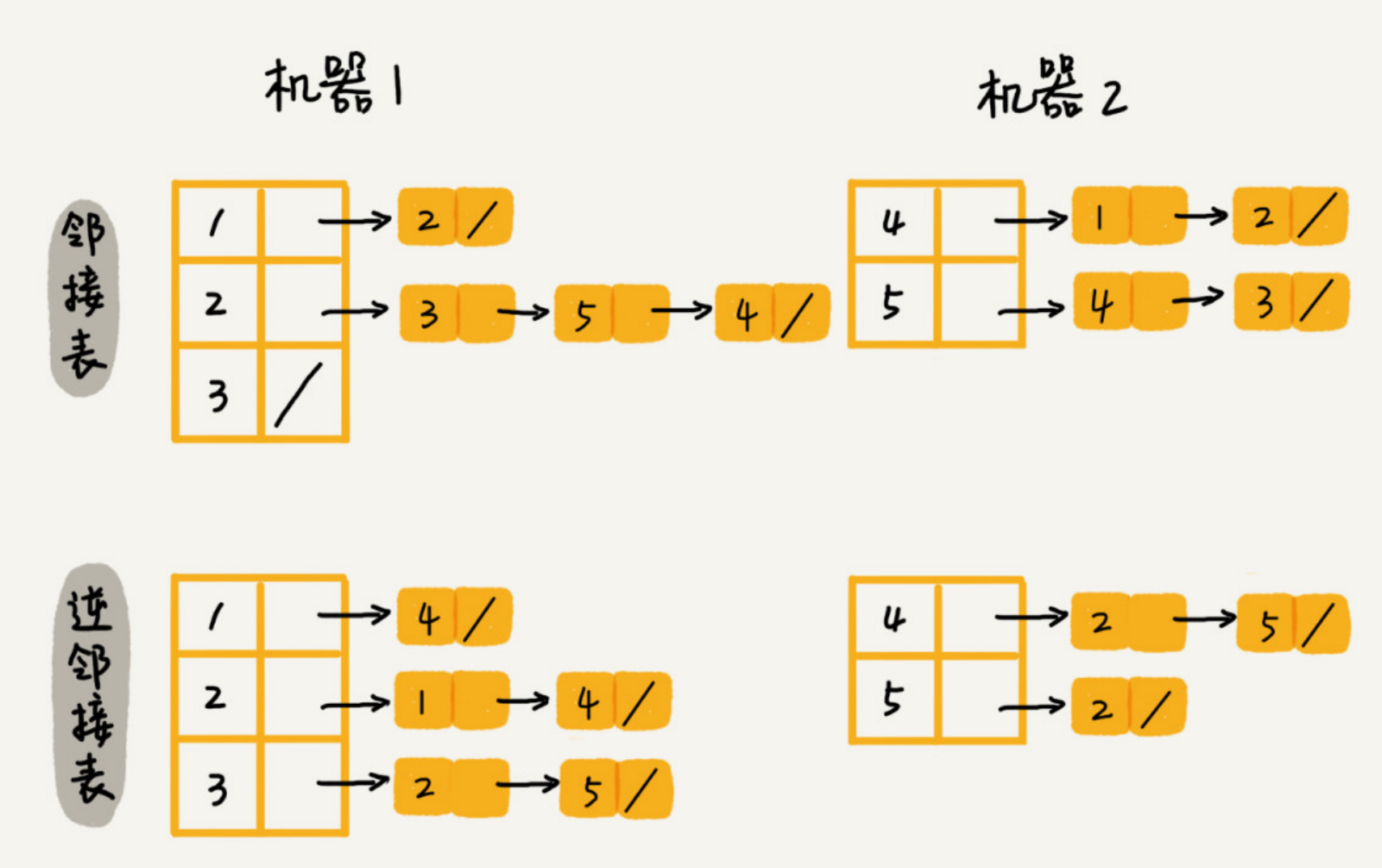
另外,也可存储在磁盘上。磁盘相对于内存来说,空间更大。比如数据库文件就是存储在磁盘上,可通过索引优化查询效率。
