一、库操作
1、创建数据库
1.1语法:CREATE DATABASE数据库名[charset utf8];
1.2数据库命名规则:可以由字母、数字、下划线、@、#、$,区分大小写,唯一性,不能使用关键字如 create select,不能单独使用数字,最长128位,#基本上跟。,python或者js的命名规则一样。
2、数据库相关操作:也是一些基本操作,和我们之前说的差不多。
1.1查看数据库:show database;
show create database db1;
select database();
1.2选择数据库:use 数据库名
1.3删除数据库:drop database 数据库名;
1.4修改数据库:alter database db1 [charset utf8];
二、表操作
‘’数据库‘’只是一个外壳,除了有个数据库名称和字符集设定,基本就没有别的信息了。
数据表才是存储(装载)数据的具体“容器”。
我们需要创建不同的表来存储不同的数据。
1、数据类型:定义数据字段的类型对于数据库的优化是非常重要的;
MySQL支持多种类型:大致分为三类:数值、日期/时间和字符串类型。
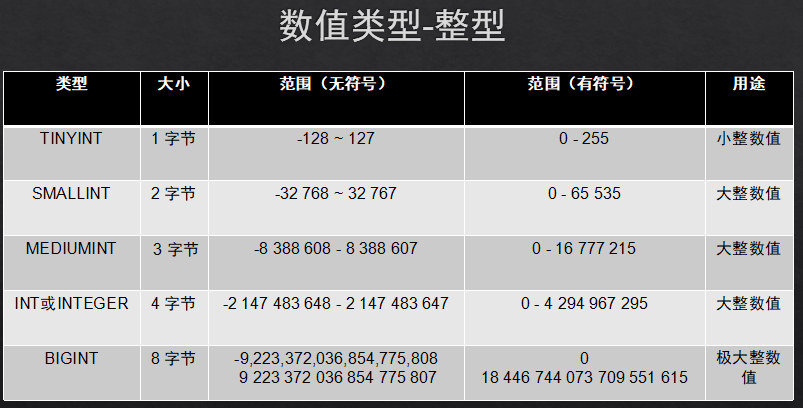
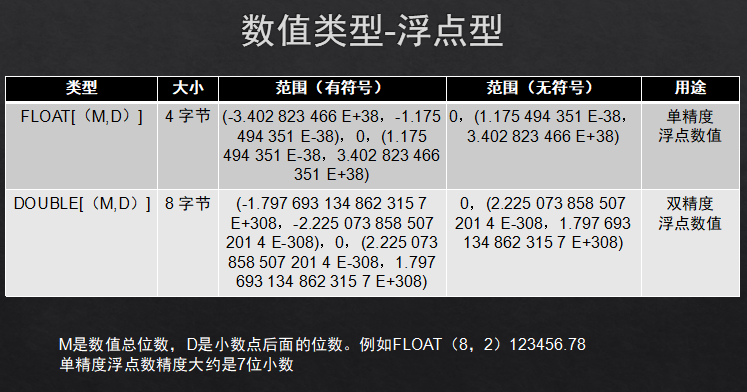
1.1数值类型:整数类:int,浮点类:float(8,2),重点记住这两个。
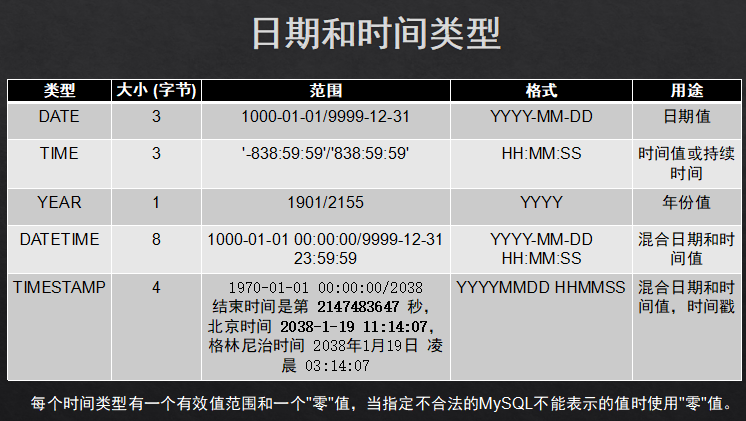
1.2日期时间类型:datatime 重点记住这一个类型。因为时间差问题多数会使用时间戳和int配合来使用。
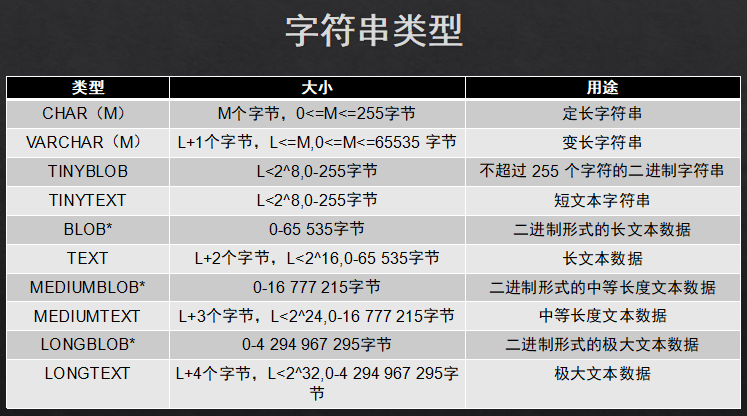
1.3字符串类型:varchar(20)text 重点记住这两个。
2、创建表的语法:create table 表的名称(column name column type);
如:create table 表名(
id int auto_increment,---列名称,列类型
name varchar(20) not null,
primapy key(id));
如果你不想字段为null可以设置字段的属性为not null,在操作数据库时如果输入字段的数据为null就会报错。
auto_increment定义列为自增属性,一般用于主键,数值会自动加1.
primapy key关键字用于定义列为主键,可以使用多列来定义主键,列间以逗号分隔,但大多数就设置一个主键。
1.1、删除数据表语法:drop table 表名;
1.2、查看所有数据表语法:show tables;
1.3、查看数据表结构的语法:desc 表名;所谓的数据表结构就是每一个字段的具体信息。
1.4、查看数据表的创建语句:showcreate table表名;
3、修改表:
1.1、添加字段语法:alter table 表名 add 字段名 字段类型;
1.2、删除字段语法:alter table 表名 drop column 列名;
1.3、修改字段名:
1.3.1、语法:alter table 表名 change 旧字段名 新字段名 新字段类型;
1.3.2、语法:alter table 表名modify 字段名 新字段类型【约束】;如果不修改名字,只修改字段的其他信息;
1.4、修改表名语法:alter table 表名 rename 新的表名;
三、数据操作:
数据的基本操作:增(insert)删(delete)改(update)查(select);
1、插入数据语法:insert into 表名(字段名1,字段名2)values(数据1,数据2);
注意:字段名和数据要对应起来;字符串和时间日期类型用单引号引起来;字段可以省略,但是要按顺序全字段数据插入;如果字段是字符串类型,必须用单引号或双引号;一条语句可以插入多个数据;
2、删除数据语法:delete from 表名;
不带条件删除的是所有的数据;通常不使用;带条件的删除,使用where id=2;
truncate 表名:删除表中所有的数据,标识所用值重置;
3、更新数据语法:update 表名 set field1=newvaluel,field2=newvalue2;
注意:修改表中某一行某个字段的数据;如果不加where条件是修改所有的数据;
4、查询数据语法:select 字段1,字段2 from 表名;
可以使用星号(*)来代替其他字段,select语句会返回表的所有字段数据;可以使用where语句来包含任何条件;
1.1、查询所有的列:select * from 表名;
1.2、使用别名:select 字段1 as ‘新名’,字段2 from 表名
1.3、where条件(逻辑and or 比较>、<、=、>=、<=、<>不等于)
where子句中可以指定任何条件;where中可以使用and或or指定一个或多个条件;where可以运用于delete或者update命令中;列如:select * from表名 where 字段1 >值and字段2 <值;使用主键来作为where子句的条件查询是非常快速的。
1.4、where条件中berween and:select *from 表名 where 字段 between75and90;
1.5、空条件查询(null值处理):为了处理这种情况,MySQL提供了三大运算符:
is null:当列的值是null,此运算符返回true;is not null:当列的值不为null,运算符返回true;<=>:比较操作符(不同于=运算符),当比较的两个值为null时返回true。
注意:关于 NULL 的条件比较运算是比较特殊的。你不能使用 = NULL 或 != NULL 在列中查找 NULL 值 。
select * from 表名 where 字段 IS NULL;(IS NOT NULL)
5、模糊查询like语法:select *from 表名 where 字段 like‘%w%’;
select * from 表名 where 字段‘李_’;
%:表示任意字符;字符可有可无;_:表示一个字符;此字符必须有;
6、去除重复数据(distinct):select distinct 字段1 from 表名;
7、排序(order by):select * from 表名 order by 列名 asc(asc升序默认;desc降序)
你可以使用任何字段来作为排序的条件,从而返回排序后的查询结果。你可以设定多个字段来排序。你可以使用 ASC 或 DESC 关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列。你可以添加 WHERE...LIKE 子句来设置条件。
8、聚合函数查询:(常用的)
min最小值;max最大值;sum值的和;avg平局值;count统计行数;
1.1、分组查询:select cno,avg(degree),count(*) from score group by cno;
1.2、分组后筛选使用:group by 字段 having
having的含义跟where的含义一样,只是having是用于对group by分组的结果进行的条件筛选。
1.3、分页查询:select * from score limit 0,5;limit 起始行,行数;
9、多表联合查询:select * from 表1 as a join 表2 as b on a.id=b.lid where a.id=3;
JOIN 按照功能大致分为如下三类:
INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。