这里是修真院前端小课堂,每篇分享文从
【背景介绍】【知识剖析】【常见问题】【解决方案】【编码实战】【扩展思考】【更多讨论】【参考文献】
八个方面深度解析前端知识/技能,本篇分享的是:
【谈谈以前端角度出发做好SEO需要考虑什么?】
大家好,我是IT修真院北京总院第24期的学员,一枚正直纯洁善良的web程序员
今天给大家分享一下,修真院官网css任务15,深度思考中的知识点——谈谈以前端角度出发做好SEO需要考虑什么?
1.背景介绍
什么是SEO?
SEO由英文Search Engine Optimization缩写而来,中文意译为“搜索引擎优化”。
其实叫做针对搜索引擎优化更容易理解。它是指从自然搜索结果获得网站流量的技术和过程,是在了解搜索引擎自然排名机制的基础上,对网站进行内部及外部的调整优化, 改进网站在搜索引擎中的关键词自然排名,获得更多流量,从而达成网站销售及品牌建设的目标。
2.知识剖析
搜索引擎工作原理
在搜索引擎网站,比如百度,在其后台有一个非常庞大的数据库,里面存储了海量的关键词,而每个关键词又对应着很多网址,这些网址是百度程序从茫茫的互联网上一点一点下载收集而来的,这些程序称之为“搜索引擎蜘蛛”或“网络爬虫”。这些勤劳的“蜘蛛”每天在互联网上爬行,从一个链接到另一个链接,下载其中的内容,进行分析提炼,找到其中的关键词,如果“蜘蛛”认为关键词在数据库中没有而对用户是有用的便存入数据库。反之,如果“蜘蛛”认为是垃圾信息或重复信息,就舍弃不要,继续爬行,寻找最新的、有用的信息保存起来提供用户搜索。当用户搜索时,就能检索出与关键字相关的网址显示给访客。
一个关键词对应多个网址,因此就出现了排序的问题,相应的与关键词吻合权重高的网址就会排在前面了。在“蜘蛛”抓取网页内容,提炼关键词的这个过程中,就存在一个问题:“蜘蛛”能否看懂。如果网站内容都是是flash和js,那么它是看不懂的,会犯迷糊,即使关键字再贴切也没用。相应的,如果网站内容是它的语言,那么它便能看懂,它的语言即SEO。
从宏观的角度来说,SEO有三条最重要的规律,那就是原创的内容、高质量的外部链接和适度的优化。前端是构建网站中很重要的一个环节,本节重点从前端的角度来讲解一下SEO的实施方法。
前端的工作主要是负责页面的HTML+CSS+JS,优化好这几个方面会为SEO工作打好一个坚实的基础。突出重点内容可以让搜索引擎判断当前页面的重点是什么,提升网站的访问速度可以让搜索引擎的蜘蛛顺利、快速、大量的抓取页面内容,所以我就着重以突出重要内容和提升网站速度来总结一下。
了解搜索引擎的抓取工具
百度
百度通过一个叫做Baiduspider的程序抓取互联网上的网页,经过处理后建入索引中。
1、对网站抓取的友好性:会制定一个规则最大限度的利用带宽和一切资源获取信息,同时也会仅最大限度降低对所抓取网站的压力。
2、识别url重定向:对互联网众多的url重新识别
3、百度蜘蛛抓取优先级合理使用: 优先抓取的策略主要有:深度优先、宽度优先、反链优先,在我接触这么长时间里,PR优先是经常遇到的。
4、无法抓取数据的获取: 在互联网中可能会出现各种问题导致百度蜘蛛无法抓取信息,在这种情况下百度开通了手动提交数据。
5、对作弊信息的抓取: 百度出台了绿萝、石榴等算法对作弊链接进行过滤,据说内部还有一些其他方法进行判断,这些方法没有对外透露。
谷歌
(谷歌使用许多计算机来提取(或“抓取”)网站上的大量网页。Googlebot 使用算法确定抓取过程:计算机程序确定要抓取的网站、抓取频率以及从每个网站抓取的网页数量。 进行抓取时,Googlebot 会先查看以前的抓取过程所生成的一系列网页网址,包含网站站长提供的站点地图数据。 Googlebot 在访问其中的每个网站时,会检测各网页上的链接(SRC 和 HREF),并将这些链接添加到要抓取的网页列表。 它会记录新出现的网站、现有网站的更新以及无效链接,并据此更新 Google 索引。
3.常见问题
前端怎么做SEO
4.解决方法
1.维护网站,提高内容质量,保持更新
搜索引擎会考评网站的质量,保持网站的经常更新,使网站拥有大量的、有用的、可读性强的优质信息。网站的权重会相应的提升。为了保持更新频率而去抄袭并不可取。
2.网站结构布局优化:尽量简单、开门见山,提倡扁平化结构。
一般而言,建立的网站结构层次越少,越容易被“蜘蛛”抓取,也就容易被收录。一般中小型网站目录结构超过三级,“蜘蛛”便不愿意往下爬,并且根据相关调查:访客如果经过跳转3次还没找到需要的信息,很可能离开。因此,三层目录结构也是体验的需要。
3. 控制首页链接数量
网站首页是权重最高的地方,如果首页链接太少,没有“桥”,“蜘蛛”不能继续往下爬到内页,直接影响网站收录数量。但是首页链接也不能太多,一旦太多,没有实质性的链接,很容易影响用户体验,也会降低网站首页的权重,收录效果也不好。注意链接要建立在用户的良好体验和引导用户获取信息的基础之上。
4.导航优化
导航应该尽量采用文字方式,也可以搭配图片导航,但是图片代码一定要进行优化,img标签必须添加“alt”和“title”属性,告诉搜索引擎导航的定位,做到即使图片未能正常显示时,用户也能看到提示文字。其次,在每一个网页上应该加上面包屑导航,好处:从用户体验方面来说,可以让用户了解当前所处的位置以及当前页面在整个网站中的位置,帮助用户很快了解网站组织形式,从而形成更好的位置感,同时提供了返回各个页面的接口,方便用户操作;对“蜘蛛”而言,能够清楚的了解网站结构,同时还增加了大量的内部链接,方便抓取,降低跳出率。
5.控制页面的大小
减少http请求,提高网站的加载速度。当速度很慢时,用户体验不好,留不住访客,并且一旦超时,“蜘蛛”也会离开。
6.适量的关键词和网页描述
关键词不宜太多也不宜太少,列举出几个页面的重要关键字即可,切记过分堆砌。网页描述要准确,精简地描述网页的内容。
1.title标题:只强调重点即可,尽量把重要的关键词放在前面,关键词不要重复出现,尽量做到每个页面的title标题中不要设置相同的内容。

2.meta keywords标签:关键词,列举出几个页面的重要关键字即可,切记过分堆砌。
3.meta description标签:网页描述,需要高度概括网页内容,切记不能太长,过分堆砌关键词,每个页面也要有所不同。

4.body中的标签:尽量让代码语义化,在适当的位置使用适当的标签,用正确的标签做正确的事。让阅读源码者和“蜘蛛”都一目了然。比如:h1-h6 是用于标题类的,nav标签是用来设置页面主导航的等。
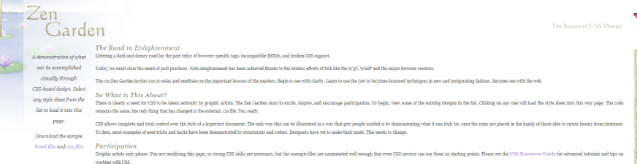
对于搜索引擎来说,最直接面对的就是网页HTML代码,如果代码写的语义化,搜索引擎就会很容易的读懂该网页要表达的意思。例如文本模块要有大标题,合理利用h1-h6,列表形式的代码使用ul或ol,重要的文字使用strong等等。总之就是要充分利用各种HTML标签完成他们本职的工作,当然要兼容IE、火狐、Chrome等主流浏览器。我们来看看著名的禅意花园网站(http://www.csszengarden.com/),在没有样式的情况下,代码非常语义化,看起来很工整,加载不同的样式之后可以随心所欲的改变页面外观。
无样式表:

有样式表:
5.a标签:页内链接,要加 “title” 属性加以说明,让访客和 “蜘蛛” 知道。而外部链接,链接到其他网站的,则需要加上 el="nofollow" 属性, 告诉 “蜘蛛” 不要爬,因为一旦“蜘蛛”爬了外部链接之后,就不会再回来了。
6.img应使用 "alt" 属性加以说明。为图片加上alt属性,当网络速度很慢,或者图片地址失效的时候,就可以体现出alt属性的作用,他可以让用户在图片没有显示的时候知道这个图片的作用。
7.strong、em标签 : 需要强调时使用。strong标签在搜索引擎中能够得到高度的重视,它能突出关键词,表现重要的内容,em标签强调效果仅次于strong标签。
9.巧妙利用CSS布局,将重要内容的HTML代码放在最前面,最前面的内容被认为是最重要的,优先让“蜘蛛”读取,进行内容关键词抓取。搜索引擎抓取HTML内容是从上到下,利用这一特点,可以让主要代码优先读取,广告等不重要代码放在下边。例如,在左栏和右栏的代码不变的情况下,只需改一下样式,利用float:left;和float:right;就可以随意让两栏在展现上位置互换,这样就可以保证重要代码在最前,让爬虫最先抓取。同样也适用于多栏的情况。
10.谨慎使用 display:none :对于不想显示的文字内容,应当设置z-index或设置到浏览器显示器之外。因为搜索引擎会过滤掉display:none其中的内容。
11.保留文字效果
如果需要兼顾用户体验和SEO效果,在必须用图片的地方,例如个性字体的标题,我们可以利用样式控制,让文本文字不会出现在浏览器上,但在网页代码中是有该标题的。例如这里的“电视剧分类”,为了完美还原设计图,前端工程师可以把文字做成背景图,之后用样式让html中的文字的缩进设置成足够大的负数,偏离出浏览器之外,也可以利用设置行高的方法让文字隐藏。

12.利用CSS截取字符
如果文字长度过长,可以用样式截取,设置高度,超出的部分隐藏即可。这样做的好处是让文字完整呈现给搜索引擎,同时在表现上也保证了美观。

5.编码实战
6.拓展思考
如何不让搜索引擎抓取网站的隐私内容
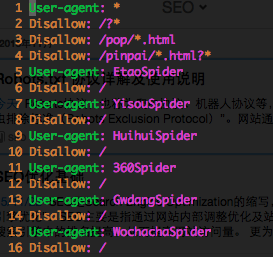
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol), 网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
文件的写法:
User-agent:*
*是一个通配符,表示所有的搜索引擎种类
Disallow:/admin/
这表示禁止搜索引擎爬寻admin目录下的内容
Disallow:*?*
这表示禁止搜索引擎爬寻包含?的网页
Sitemap:sitemap.xml
这里通过Sitemap指定固定的网站地图页面。目前对此表示支持的搜索引擎公司有Google, Yahoo, Ask and MSN。而中文搜索引擎公司,显然不在这个圈子内。这样做的好处就是,站长不用到每个搜索引擎的站长工具或者相似的站长部分,去提交自己的sitemap文件,搜索引擎的蜘蛛自己就会抓取robots.txt文件,读取其中的sitemap路径,接着抓取其中相链接的网页。
如何进行外部优化?
外部链接类别:博客、论坛、B2B、新闻、分类信息、贴吧、知道、百科、相关信息网等尽量保持链接的多样性。
外链选择:与一些和你网站相关性比较高,整体质量比较好的网站交换友情链接,巩固稳定关键词排名。
7.参考文献
参考一:以前端角度出发做好SEO需要考虑什么
8.更多讨论
SEO与SEM的区别
SEO与SEM
SEM(Search Engine Market)就是搜索引擎营销。简单理解就是购买搜索引擎提供的广告位, 例如百度和google右侧的结果都是广告,按照关键词购买,按照点击收费,每次有网民点击你的广告,搜索引擎就扣一次费用。
区别:SEO是通过对网站的内容,结构,外链等方面进行优化,使网站更符合搜索引擎的抓取, 从而提升搜索结果排名,提升网站流量的手段。
感谢大家观看
今天的分享就到这里啦,欢迎大家点赞、转发、留言、拍砖~
技能树.IT修真院
“我们相信人人都可以成为一个工程师,现在开始,找个师兄,带你入门,掌控自己学习的节奏,学习的路上不再迷茫”。
这里是技能树.IT修真院,成千上万的师兄在这里找到了自己的学习路线,学习透明化,成长可见化,师兄1对1免费指导。快来与我一起学习吧~
我的邀请码:12361358,或者你可以直接点击此链接:http://www.jnshu.com/login/1/12361358
更多内容,可以加入IT交流群565734203与大家一起讨论交流
这里是技能树·IT修真院:https://www.jnshu.com,初学者转行到互联网的聚集地