广度优先搜索,深度优先搜索-JavaScript
摘要:
掌握好数据结构对前端和后端都很有必要,js中DOM可以跟树这种数据结构联系起来,相信大家都不陌生。
遍历下面这颗DOM树,遍历到节点时,打印当前节点和类名
<div class="root"> <div class="box1"> <p class="pnode">nini</p> </div> <div class="box2"> </div> <div class="box3"> <span class="spannode">lalal</span> </div> </div>
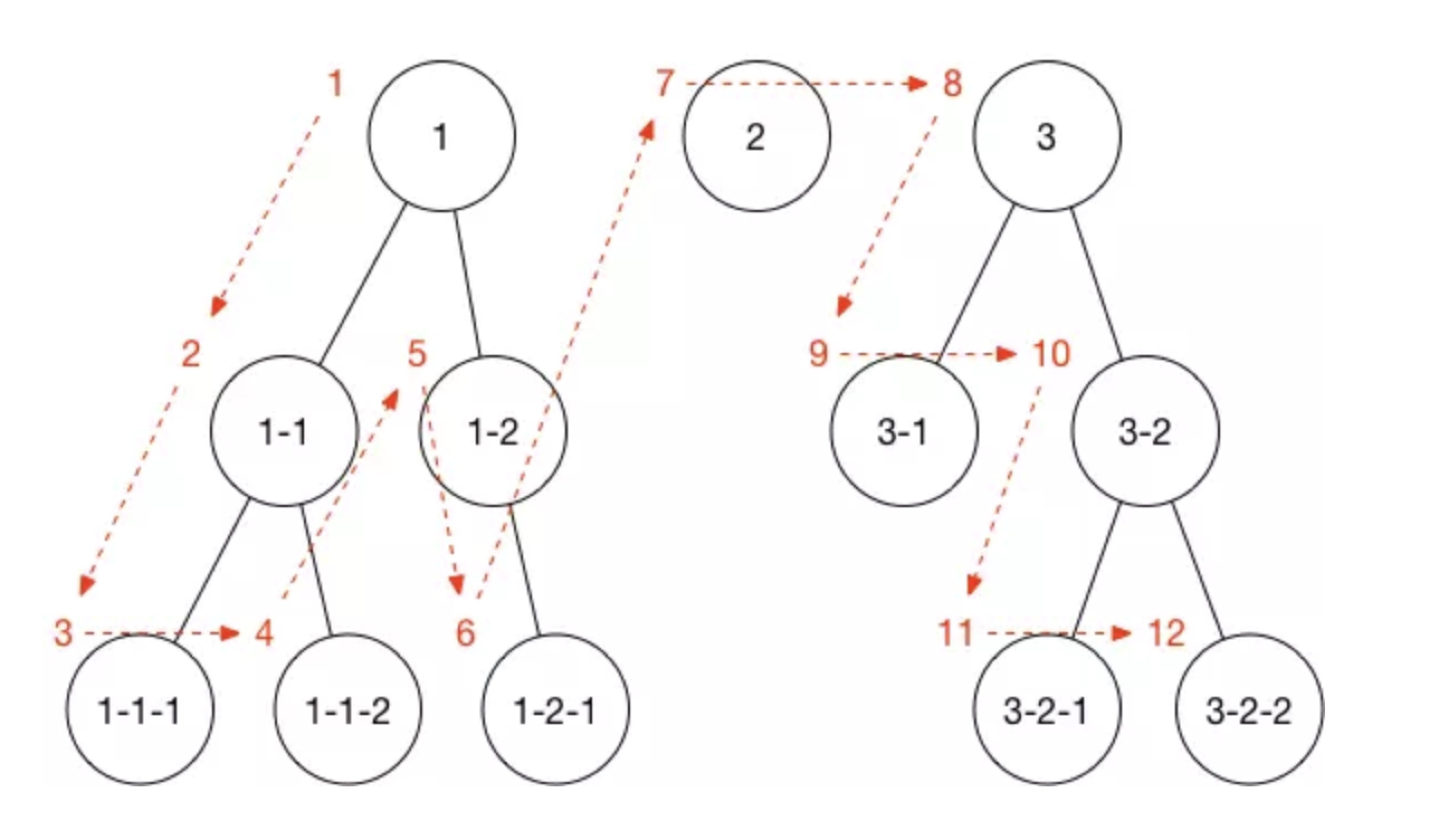
1. 深度优先搜索
深度优先遍历是指从某个顶点出发,首先访问这个顶点,然后找出刚访问这个结点的第一个未被访问的邻结点,然后再以此邻结点为顶点,继续找它的下一个顶点进行访问。重复此步骤,直至所有结点都被访问完为止。
下面是深度优先搜索的顺序图
递归版:
function deepTraversal(node){
let nodes=[];
if(node!=null){
nodes.push[node];
let childrens=node.children;
for(let i=0;i<childrens.length;i++)
deepTraversal(childrens[i]);
}
return nodes;
}
非递归版:
function deepTraversal(node) { let nodes = []; if(node != null) { let stack = []; //存放将来要访问的节点 stack.push(node); while(stack.length !=0) { let item = stack.pop(); //正在访问的节点 nodes.push(item); let childrens = item.children; for(let i = childrens.length-1; i>=0; i--) { //将现在访问的节点的子节点存入stack,供将来访问 stack.push(childrens[i]) } } } return nodes; }
非递归版呢,先把元素放在数组里,然后是把数据的最后一项pop出去,判断当前元素是否有子节点,如果有的话推进数组里,直到数组里没有数据停止循环。
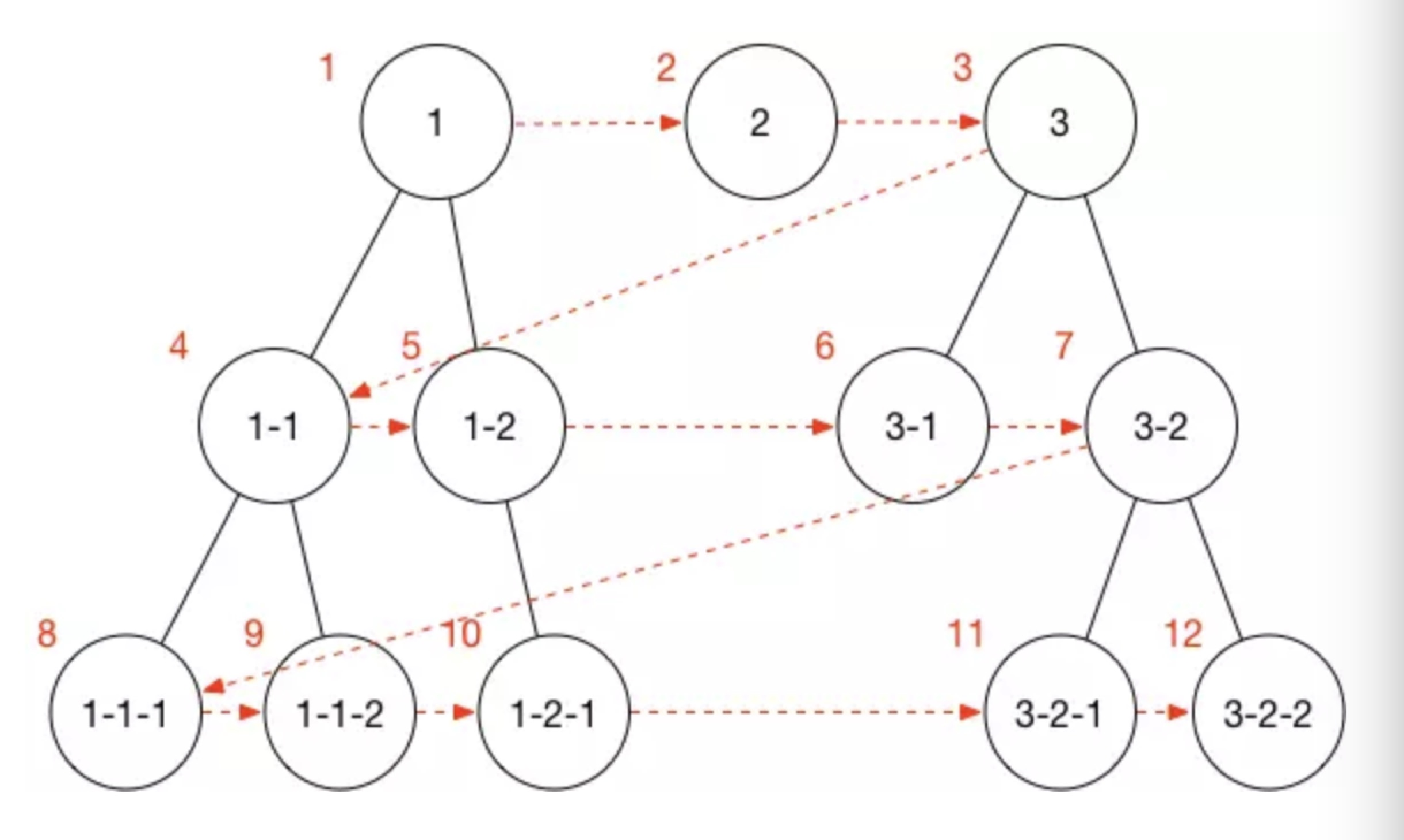
2. 广度优先搜索
广度优先遍历是从某个顶点出发,首先访问这个顶点,然后找出刚访问这个结点所有未被访问的邻结点,访问完后再访问这些结点中第一个邻结点的所有结点,重复此方法,直到所有结点都被访问完为止。
下面是广度优先搜素的顺序图:
递归版:
function wideTraversal(node) { let nodes = [],i=0; if(node != null) { nodes.push(node); wideTraversal(node.nextElementSibling); node = nodes[i++]; wideTraversal(node.firstElementChild); } return nodes }
非递归版:
function wideTraversal(node) { let nodes = [],i=0; if(node != null) { let stack = []; //存放将来要访问的节点 stack.push(node); while(stack.length !=0) { let item = stack.shift(); //正在访问的节点 nodes.push(item); let childrens = item.children; for(let i = 0; i<childrens.length; i++) { //将现在访问的节点的子节点存入stack,供将来访问 stack.push(childrens[i]) } } } return nodes }
广度优先搜索非递归版和深度优先搜索的递归版思想差不多,一个是pop最后一个元素,一个是shift第一个元素,再把子元素放在一个数组最后,这样再进行数组的处理时会先遍历父元素,子元素最后遍历。达到广度搜索的目的。
结论:
对于深度优先搜索来说,打印了两个的执行速度,递归的处理速度相对较快点,但是对于广度优先搜索来说,非递归的执行速度比较快点。所以每个搜索都有自己的最好的算法。