1.试验目的
输入:一组任意的规则。
输出:相应的Chomsky 文法的类型。
2.实验原理
1).0型文法(短语文法)
如果对于某文法G,P中的每个规则具有下列形式:
u:: = v
其中u∈V+,v∈V*,则称该文法G为0型文法或短语文法,简写为PSG。
0型文法或短语结构文法的相应语言称为0型语言或短语结构语言L0。这种文法由于没有其他任何限制,因此0型文法也称为无限制文法,其相应的语言称为无限制性语言。任何0型语言都是递归可枚举的,故0型语言又称递归可枚举集。这种语言可由图灵机(Turning)来识别。
2).1型文法(上下文有关文法)
如果对于某文法G,P中的每个规则具有下列形式:
xUy:: = xuy
其中U∈VN;u∈V+;x,y∈V*,则称该文法G为1型文法或上下文有关文法,也称上下文敏感文法,简写为CSG。
1型文法的规则左部的U和右部的u具有相同的上文x和下文y,利用该规则进行推导时,要用u替换U,必须在前面有x和后面有y的情况下才能进行,显示了上下文有关的特性。
1型文法所确定的语言为1型语言L1,1型语言可由线性有界自动机来识别。
3).2型文法(上下文无关文法)
如果对于某文法G,P中的每个规则具有下列形式:
U :: = u
其中U∈VN;u∈V+,则称该文法G为2型文法或上下文无关文法,简写为CFG。
按照这条规则,对于上下文无关文法,利用该规则进行推导时,无需考虑非终结符U所在的上下文,总能用u替换U,或者将u归约为U,显示了上下文无关的特点。
2型文法所确定的语言为2型语言L2,2型语言可由非确定的下推自动机来识别。
一般定义程序设计语言的文法是上下文无关的。如C语言便是如此。因此,上下文无关文法及相应语言引起了人们较大的兴趣与重视。
4).3型文法(正则文法,线性文法)
如果对于某文法G,P中的每个规则具有下列形式:
U :: = T 或 U :: = WT
其中T∈VT;U,W∈VN,则称该文法G为左线性文法。
如果对于某文法G,P中的每个规则具有下列形式:
U :: = T 或 U :: = TW
其中T∈VT;U, W∈VN,则称该文法G为右线性文法。
左线性文法和右线性文法通称为3型文法或正则文法,有时又称为有穷状态文法,简写为RG。
按照定义,对于正则文法应用规则时,单个非终结符号只能被替换为单个终结符号,或被替换为单个非终结符号加上单个终结符号,或者被替换为单个终结符号加上单个非终结符号。
3型文法所确定的语言为3型语言L3,3型语言可由确定的有限状态自动机来识别。
在常见的程序设计语言中,多数与词法有关的文法属于3型文法。
可以看出,上述4类文法,从0型到3型,产生式限制越来越强,其后一类都是前一类的子集,而描述语言的功能越来越弱,四类文法及其表示的语言之间的关系可表示为:
0型1型2型3型;即L0 L1 L2 L3
3..实验内容
1)输入一组文法规则,以S为开始符,大写字母为非终结符,非大写字母为终结符。
2)判断文法类型并生成文法的四元组形式。
3)输出文法类型及文法。
4.实验心得
这次实验让我体会到了判别文法的复杂性,我的算法是先默认是正则文法,再依次判断,而许多同学是每次对一条规则进行相同的判断,我认为这是可以改进的,例如若发现上一条规则是符合1型文法,则当前的规则就只需从1型文法开始判断,详见源代码。
5.实验代码与结果
1)源代码
1 /******************************************************************** 2 created: 2013/05/28 3 created: 28:5:2013 20:15 4 file base: main 5 file ext: cpp 6 author: Justme0 (http://blog.csdn.net/Justme0) 7 8 purpose: 9 判断文法类型。 10 输入约定以S为开始符,大写字母为非终结符,非大写字母为终结符。 11 12 *********************************************************************/ 13 14 #define _CRT_SECURE_NO_WARNINGS 15 #include <iostream> 16 #include <string> 17 #include <vector> 18 #include <set> 19 #include <algorithm> 20 #include <cassert> 21 using namespace std; 22 23 const int STRING_MAX_LENGTH = 10; 24 25 /* 26 ** 一条规则 27 */ 28 struct Principle { 29 string left; 30 string right; 31 32 Principle(const char *l, const char *r) : left(l), right(r) {} 33 }; 34 35 /* 36 ** 文法的四元组形式,同时将该文法类型也作为其属性 37 */ 38 struct Grammer { 39 set<char> Vn; 40 set<char> Vt; 41 vector<Principle> P; 42 char S; 43 44 int flag; // 文法类型 45 46 Grammer(void) : flag(-1) {} 47 }; 48 49 50 /* 51 ** 输入规则 52 */ 53 void input(vector<Principle> &principleSet) { 54 char left[STRING_MAX_LENGTH]; 55 char right[STRING_MAX_LENGTH]; 56 while (EOF != scanf("%[^-]->%s", left, right)) { 57 getchar(); 58 principleSet.push_back(Principle(left, right)); 59 } 60 } 61 62 /* 63 ** 得到S, Vn, Vt 64 */ 65 void getGrammer(Grammer &G) { 66 G.S = G.P.front().left.front(); 67 G.Vn.clear(); 68 G.Vt.clear(); 69 70 for (unsigned i = 0; i < G.P.size(); ++i) { 71 const Principle &prcp = G.P[i]; 72 73 for (unsigned j = 0; j < prcp.left.size(); ++j) { 74 char v = prcp.left[j]; 75 !isupper(v) ? G.Vt.insert(v) : G.Vn.insert(v); 76 } 77 for (unsigned j = 0; j < prcp.right.size(); ++j) { 78 char v = prcp.right[j]; 79 !isupper(v) ? G.Vt.insert(v) : G.Vn.insert(v); 80 } 81 } 82 } 83 84 /* 85 ** 判断字符串(文法的左部)中是否存在一个非终结符。 86 */ 87 bool hasUpper(string s) { 88 return s.end() != find_if(s.begin(), s.end(), isupper); 89 } 90 91 /* 92 ** 判断文法类型。 93 */ 94 void check(int &flag, const Principle &prcp) 95 { 96 switch (flag) { 97 case 3: 98 if ( 99 1 == prcp.left.size() && isupper(prcp.left.front()) && 100 (1 == prcp.right.size() && !isupper(prcp.right.front()) || 101 2 == prcp.right.size() && !isupper(prcp.right.front()) && isupper(prcp.right.back())) 102 ) { 103 break; 104 } 105 106 case 2: 107 if (1 == prcp.left.size() && isupper(prcp.left.front())) { 108 flag = 2; 109 break; 110 } 111 112 case 1: 113 if (hasUpper(prcp.left) && prcp.left.size() <= prcp.right.size()) { 114 flag = 1; 115 break; 116 } 117 118 default : 119 // 所有的文法规则左部都必须至少含有一个非终结符,是否应放到最前面判断? 120 // 用异常机制exit是否合适? 121 try { 122 if (!hasUpper(prcp.left)) { 123 throw exception("输入的文法错误!"); 124 } 125 } catch (exception e) { 126 cout << e.what() << endl; 127 exit(-1); 128 } 129 130 flag = 0; 131 break; 132 } 133 } 134 135 136 /* 137 ** 判别文法并生成四元组形式。 138 */ 139 void solve(Grammer &G) { 140 G.flag = 3; // 从正则文法开始判断 141 for (unsigned i = 0; i < G.P.size(); ++i) { 142 check(G.flag, G.P[i]); 143 } 144 getGrammer(G); 145 } 146 147 /* 148 ** 输出文法 149 */ 150 void output(const Grammer &G) { 151 cout << "G = (Vn, Vt, P, S)是" << G.flag << "型文法\n" << endl; 152 153 cout << "Vn:" << endl; 154 for (auto ite = G.Vn.begin(); ite != G.Vn.end(); ++ite) { 155 cout << *ite << endl; 156 } 157 cout << endl; 158 159 cout << "Vt:" << endl; 160 for (auto ite = G.Vt.begin(); ite != G.Vt.end(); ++ite) { 161 cout << *ite << endl; 162 } 163 cout << endl; 164 165 cout << "P:" << endl; 166 for (auto ite = G.P.begin(); ite != G.P.end(); ++ite) { 167 cout << (*ite).left << "->" << (*ite).right << endl; 168 } 169 cout << endl; 170 171 cout << "S:\n" << G.S << endl; 172 }; 173 174 int main(int argc, char **argv) { 175 freopen("cin.txt", "r", stdin); 176 177 Grammer G; 178 input(G.P); 179 solve(G); 180 output(G); 181 182 return 0; 183 }
2)实验结果
(1)
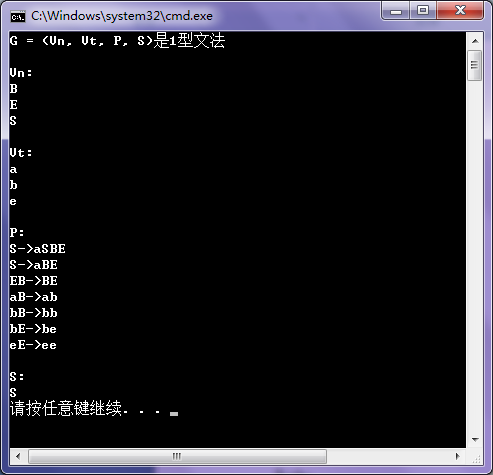
输入:
S->aSBE
S->aBE
EB->BE
aB->ab
bB->bb
bE->be
eE->ee
输出:
(2)
输入:
S->aB
S->bA
A->a
A->aS
A->bAA
B->b
B->bS
B->aBB
输出:
