1. 序列化
1.1 概念
数据存储在程序中有两种:
(1)存储在内存中,称为内存对象或是内存数据,其为临时的数据
(2)数据是存储在磁盘中,其为永久数据
序列化:将数据结构或对象转换成二进制串的过程
User对象 ---------转换规则----------> 10101010 (本质理解:序列化就是数据结构或对象如何转换成二进制串的规则)
反序列化:将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程
1.2 什么时候需要序列化
(1)数据结构或对象写入磁盘,以及从磁盘中的二进制串读取对象
(2)网络传输数据
1.3 序列化的本质是什么
就是指定一个读写规则(对象转二进制的规则,二进制转对象的规则)
(1)序列化:将内存中的对象数据持久化到磁盘中,将一端的对象通过网络发送到另一端,即对象---->二进制数据
(2)反序列化:将磁盘中的数据变成内存对象数据,接收远程的二进制数据转换成对象 ,即二进制数据--->对象
注意:自定义的写属性要和读取属性的顺序一致
如,写的第一个属性大小为4bytes,第二个属性的大小为8bytes,若读取数据的时候先读取第二个数据的话,程序就会先读取第一个属性的4个字节以及第二个属性的前四个字节,这样数据的内容就被破坏了
2. 迭代器
迭代,在不知道数据的内部存储结构的情况下可以获取数据
(1) 第一种写法:内部数据结构可以被其他人看到
MyIterator


public class MyIterator implements Iterator<User> { String line = null; User user = new User(); BufferedReader br; public MyIterator() throws Exception { br = new BufferedReader(new FileReader("E:\javafile\data.txt")); } @Override public boolean hasNext() { boolean flag = false; try { if((line = br.readLine()) != null) { flag = true; } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } return flag; } @Override public User next() { String[] split = line.split("#"); String[] split2 = split[1].split("-"); String name = split2[0]; double money = Double.parseDouble(split2[1]); int id = Integer.parseInt(split[0]); user.setId(id); user.setName(name); user.setMoney(money); return user; } }
Test
public class Test1 { public static void main(String[] args) throws Exception { MyIterator myIterator = new MyIterator(); while(myIterator.hasNext()) { User user = myIterator.next(); System.out.println(user); } } }
可以获取到相应的数据
(2)改进:只有自己能看到内部数据结构(使用内部类)
MyIteratable
public class MyIteratable implements Iterable<User>{ @Override public Iterator<User> iterator() { MyIterator myIterator = null; try { myIterator = new MyIterator(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } return myIterator; } class MyIterator implements Iterator<User> { String line = null; User user = new User(); BufferedReader br; @SuppressWarnings("unused") public MyIterator() throws Exception { br = new BufferedReader(new FileReader("E:\javafile\data.txt")); } @Override public boolean hasNext() { boolean flag = false; try { if((line = br.readLine()) != null) { flag = true; } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } return flag; } @Override public User next() { String[] split = line.split("#"); String[] split2 = split[1].split("-"); String name = split2[0]; double money = Double.parseDouble(split2[1]); int id = Integer.parseInt(split[0]); user.setId(id); user.setName(name); user.setMoney(money); return user; } } }
Test
public class Test1 { public static void main(String[] args) throws Exception {
//内部类对选哪个的创建:外部类名.内部类名 对象名=new 外部类名().new 内部类名(); MyIteratable.MyIterator myIterator= new MyIteratable().new MyIterator(); while(myIterator.hasNext()) { User user = myIterator.next(); System.out.println(user); } } }
3. 服务的基本概念
服务:就是一个业务功能通过网络通信的方式调用来实现业务功能
socket服务:
服务端:一个绑定特定端口的服务器程序
客户端:要知道服务端的地址和监听的端口请求
双方之间应该约定通信协议(协议非常复杂和麻烦,客户端请求使用比较困难)
4. hadoop
相关介绍见hadoopday01中的文档,其主要包括下面三个
(1)HDFS分布式存储文件系统
(2)MapReduce分布式运算框架
(3)YARN资源调度平台和任务监控平台
5. HDFS
(Hadoop Distribute File System )分布式文件系统,解决了海量数据无法单台机器存储的问题,将海量的数据存储在不同的机器中 ,有HDFS文件系统统一管理和维护, 提供统一的访问目录和API ,具体见文档
特点:
(1)对外提供统一的虚拟访问目录 如,put a.txt hdfs://feng01:9000/
(2)客户端访问的是虚拟目录
(3)namenode来维护这个虚拟目录和数据真正存储的信息关系(元数据管理)
虚拟目录 映射 元数据
(4)数据真正存储在不同的机器上的,并且大文件会被物理切块【128m】存储(方便赋值,方便运算)
(5)为了保证在某些机器宕机的情况下数据是安全的的,在集群中数据块是存储副本的(3)
(6)集群中的存储能力通过添加节点(datanode)动态追加存储容量
(7)集群能够否无限扩容?不能,因为存储的数据的元数据是由namenode管理的,name的内存是由限制的
(8)容错机器,保证数据副本的个数,当某个机器宕机后,集群的存储和访问不受影响
5.0 客户端
请求读写数据
如果客户端client程序发起了读hdfs上的某个文件的指令, NameNode首先将找到这个文件对应的block,然后NameNode告知client,这些block数据在哪些DataNode上,之后, client将直接和DataNode交互。
5.1 namenode

专门记录数据存储信息(即为元数据)的机器称为namenode,存储的信息为:如数据有多大,存储在哪个机器上,并且分的块的大小为多少,每个块存储在哪些datanode中以及哪个文件夹中等
5.2 datanode


5.3 HDFS分布式存储的基本涉及原理:
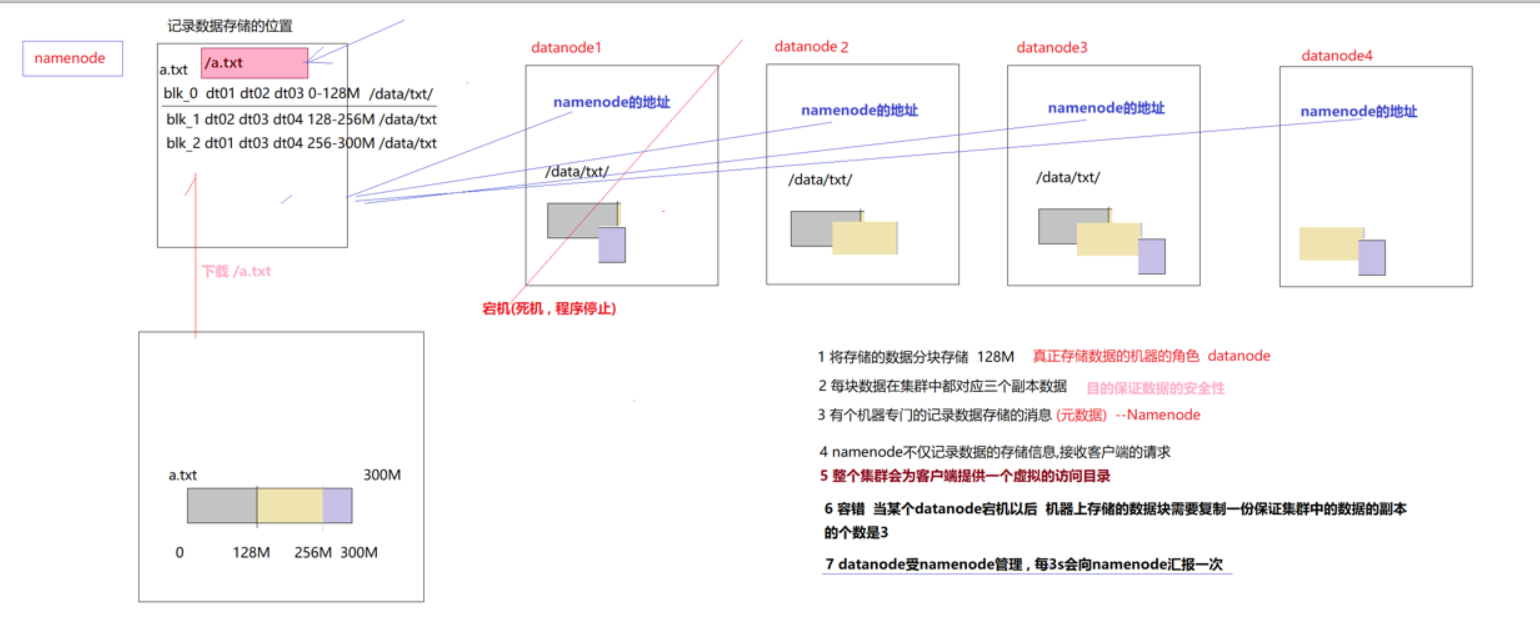
HDFS中有namenode和datanode,分别用来记录数据存储的位置和存储数据,数据会采取分块存储,一个块一般是128M(原因:读取数据的时候,寻找到文件位置的时间一般为10ms,而处理数据的最佳时长为10x100,ms, 而本地流的下载速度一般为100m/s),每个块会在不同的机器上存储副本,当其中一个机器宕机时(即某些数据块访问不到),namenode会发送响应的指令去datanode,这时集群能找到包含此数据块并在正常工作的机器,并将这个数据备份一份放到另外一台没有此数据的机器上去。
(1)这种备份机制是如何做到的呢?
答案就是datanode所在的机器会相隔一定的时间(3s)向namenode所在的机器发送信息(心跳汇报),表明自己还在运行,若namenode超过3s没收到datanode发来的心跳汇报,就会进行响应的措施。
(2)这样以来又存在另外一个问题,datanode如何知道namenode上面的集群ID是多少,即向谁进行心跳汇报?
datanode启动之后会去读取配置文件,通过配置文件获取到namenode的地址和内部请求端口,然后去跟namenode进行握手,握手之后就会获取namenode的集群id
5.4 HDFS的动态扩容
注意:
云资源上会有一个虚拟目录,这个目录对应着数据的真实地址,如百度网盘可以直接点击虚拟目录中的内容进行下载,实质就是去相应的datanode下载,如下图所示

当存储能力有限时,就可以通过增加datanode的形式实现动态扩容。当新添加一个datanode时,当namenode收到此新的datanode的心跳汇报时,其能知晓多了一个datanode,这样就会将原来4T的内存更新为6T(图所示)
5.5 HDFS的安装

core-site.xml文件中的hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配 置namenode和datanode的存放位置,默认就放在这个路径中,这个路径的默认路径为/tmp(没设置时)
1 将安装包上传到linux操作系统中 /usr/apps======>使用rz
2 tar -zxf hadoop-2.8.5.tar.gz 解压到当前文件夹下 没有显示解压的进度

3. 配置
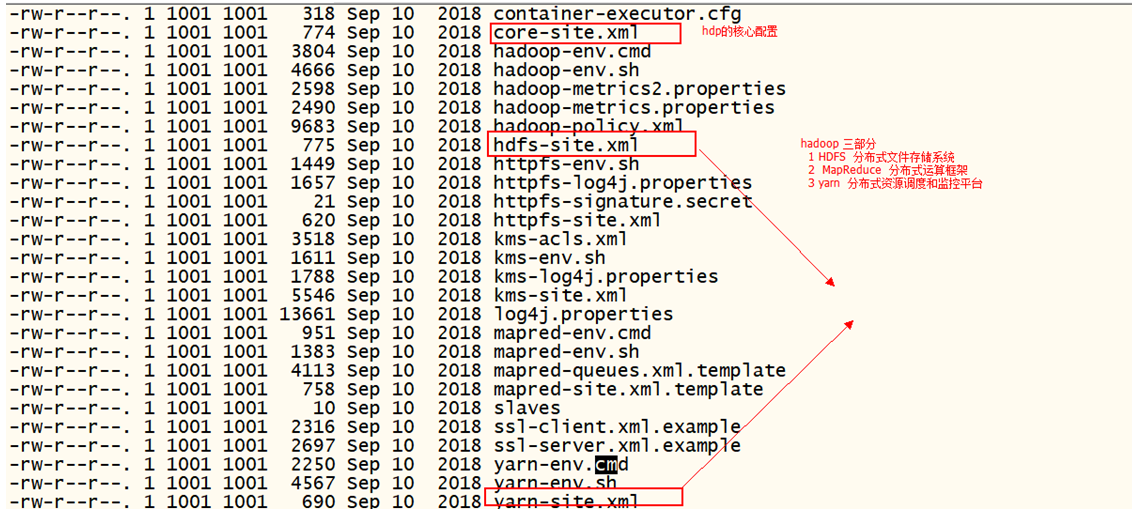
(1)hdp JAVA_HOME(hadoop-env.sh)

(2)namenode的位置,元数据存储的位置; datanode 真正的数据存储的位置(hdfs-site.xml)
<configuration> <!-- 配置namenode机器 --> <property> <name>dfs.namenode.rpc-address</name> <value>feng01:9000</value> </property> <!-- 配置namenode元数据存储的路径 --> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hdpdata/name/</value> </property> <!-- 配置datanode数据块数据存储的路径 --> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hdpdata/data/</value> </property> <!-- 配置secondarynamenode的机器的位置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>feng02:50090</value> </property> </configuration>
4. 安装包的分发
分发前先删除一个文件夹(此文件夹下有大量的小文件,不删除分发很麻烦)

scp -r hadoop-2.8.5 doit02:$PWD 当前路径为/usr/apps
scp -r hadoop-2.8.5 doit03:$PWD
scp -r hadoop-2.8.5 doit04:$PWD
5 初始化

注意:JAVA_HOME的配置,否则这块会出错
./hadoop namenode -format
格式化成功后,/opt中就会又个hdpdata文件夹
6. 启动
启动程序在sbin目录中
(1)启动namenode命令:./hadoop-daemon.sh start namenode

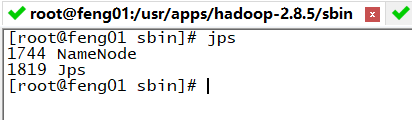
这时在浏览器中输入feng01:50070,即可得到如下网页
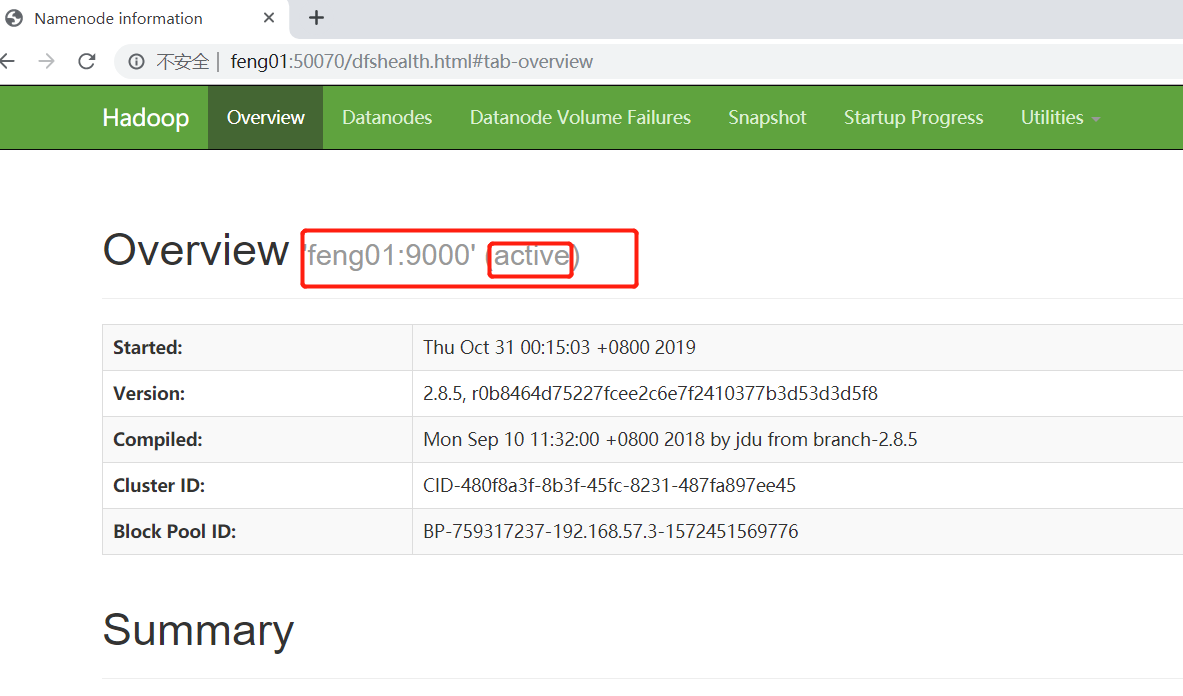
(2)启动datanode,会发现会有一个datanode节点(若开启多个datanode的节点数会相应的增加)
6.1 客户端的操作
bin> hdfs dfs -put 文件 hdfs://doit01:9000/
bin> hdfs dfs -mkdir hdfs://doit01:9000/aaa
[root@doit01 bin]# ./hdfs dfs
19/09/22 15:00:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] 下载
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>] 剪切上传
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]