Application
application(应用)其实就是spark-submit提交的spark应用程序。一个完整的Spark应用程序包含如下几个基本步骤:
- 获取输入数据(通过序列获取,读取HDFS,读取数据库,读去S3等!)
- 处理数据(具体的代码逻辑)
- 输出结果(导入到HDFS,Hbase,MySQL等存储)
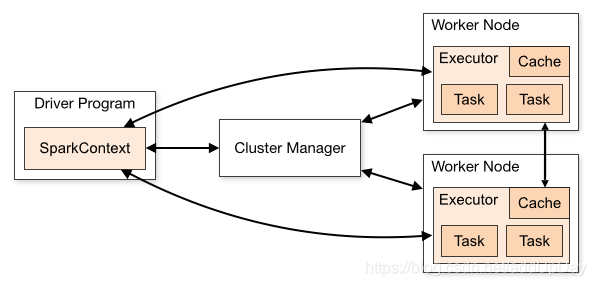
从spark官网的这幅图可以简单看出,提交一个spark应用程序会创建一个driver端来管理这个spark应用程序。和YARN的ApplicationMaster相似,完成任务的调度以及与executor和ClusterManager协调。有两种模式,client以及cluster模式。client模式将driver运行在spark-submit执行的机器中,cluster则是在spark集群中随机挑选一台执行。如果spark调度器集成了YARN,那么这两种模式在YARN中也有类似的体现!
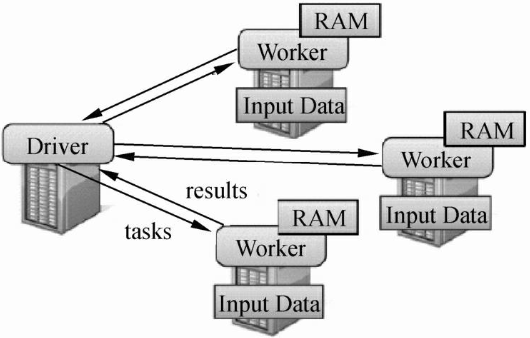
Spark Application 的执行框架如图所示。 一个 Spark Application 由两
部分构成: Driver Program 和若干 Executor。 其中 Driver Program 中包含了 Spark Context 和 main 函
数; Executor 是 Worker 中用于运行 Task 的进程。 在执行 Spark Application 过程中,集群上的资源如
何调度,由 Cluster Manager 进行管理。
Driver Program
Spark Driver Program(以下简称Driver)是运行Application的main函数并且新建SparkContext实例的程序。其实,初始化SparkContext是为了准备Spark应用程序的运行环境,在Spark中,由SparkContext负责与集群进行通信、资源的申请、任务的分配和监控等。当Worker节点中的Executor运行完毕Task后,Driver同时负责将SparkContext关闭。通常也可以使用SparkContext来代表驱动程序(Driver)。
Driver(SparkContext)整体架构图如下所示:
SparkContext
SparkContext是通往Spark集群的唯一入口,可以用来在Spark集群中创建RDDs、累加器(Accumulators)和广播变量(Broadcast Variables)。SparkContext也是整个Spark应用程序(Application)中至关重要的一个对象,可以说是整个Application运行调度的核心(不是指资源调度)。
SparkContext的核心作用是初始化Spark应用程序运行所需要的核心组件,包括高层调度器(DAGScheduler)、底层调度器(TaskScheduler)和调度器的通信终端(SchedulerBackend),同时还会负责Spark程序向Master注册程序等。
Worker
- 主要功能:管理当前节点内存,CPU的使用状况,接收master分配过来的资源指令,通过ExecutorRunner启动程序分配任务,worker就类似于包工头,管理分配新进程,做计算的服务,相当于process服务。
- 需要注意的是:
- 1)worker不会汇报当前信息给master,worker心跳给master主要只有workid,它不会发送资源信息以心跳的方式给mater,master分配的时候就知道worker,只有出现故障的时候才会发送资源。
- 2)worker不会运行代码,具体运行的是Executor是可以运行具体appliaction写的业务逻辑代码,操作代码的节点,它不会运行程序的代码的。
Executor
是 Worker 上为某个 Application 启动的一个进程,该进程负责执行任务并且负责将数据存储在内存或者磁盘中 。 Executor 拥有 CPU 和内存资源,它是资源管理系统能够给予的最小单位。一个 Worker 节点上可能有多个 Executor,但是每个 Executor 中仅执行一个 Application 对应的任务。 也就是说 ,不同的 Application 通过 Executor 无法共享数据。
Task
Task 即任务,是被送到 Executor 上执行的工作单元 。 RDD 中的每个分区都对应相应的 Task ,而每个 Task 对应于 Executor 中的一个线程,这使得系统更加轻量级, Task 之间切换的时间延迟更短。
Job
Job 即作业,是包含多个 Task 的并行计算,其与 Application 中的执行操作一一对应,也就是说
Application 每提交一个执行操作 Spark 对应生成一个 Job 。
Stage
通常执行操作之前会有若干个转换操作,而每个转换操作意味着父 RDD 到子 RDD 的转换,因
此一个 Job 中通常涉及多个 RDD。 将 Job 中涉及的 RDD 进行分组,每组称为一个 Stage。
Cluster Manager
是在集群上获取资源的外部服务。若是 Standalone 模式的 Spark 集群, Cluster Manager 即为 Master;
若是基于 Yam 模式的 Spark 集群, Cluster Manager 即为 Resource Manager。
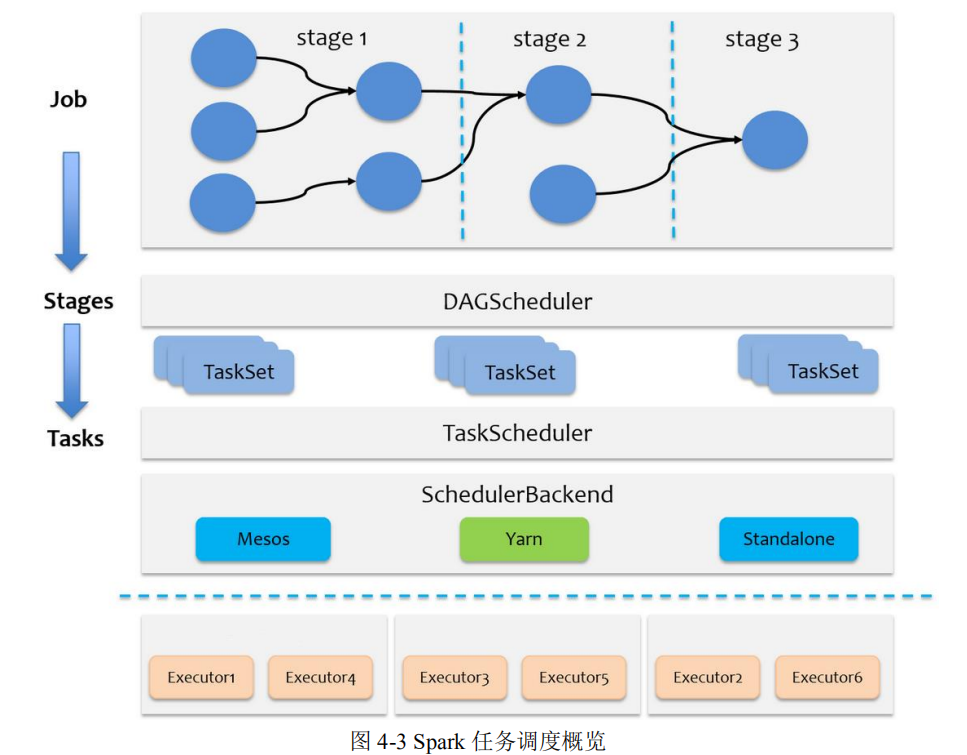
Job、Stage、Task 划分方法
Spark 任务提交流程

Spark 任务调度概述
参考资料
https://blog.csdn.net/addUpDay/article/details/89112712