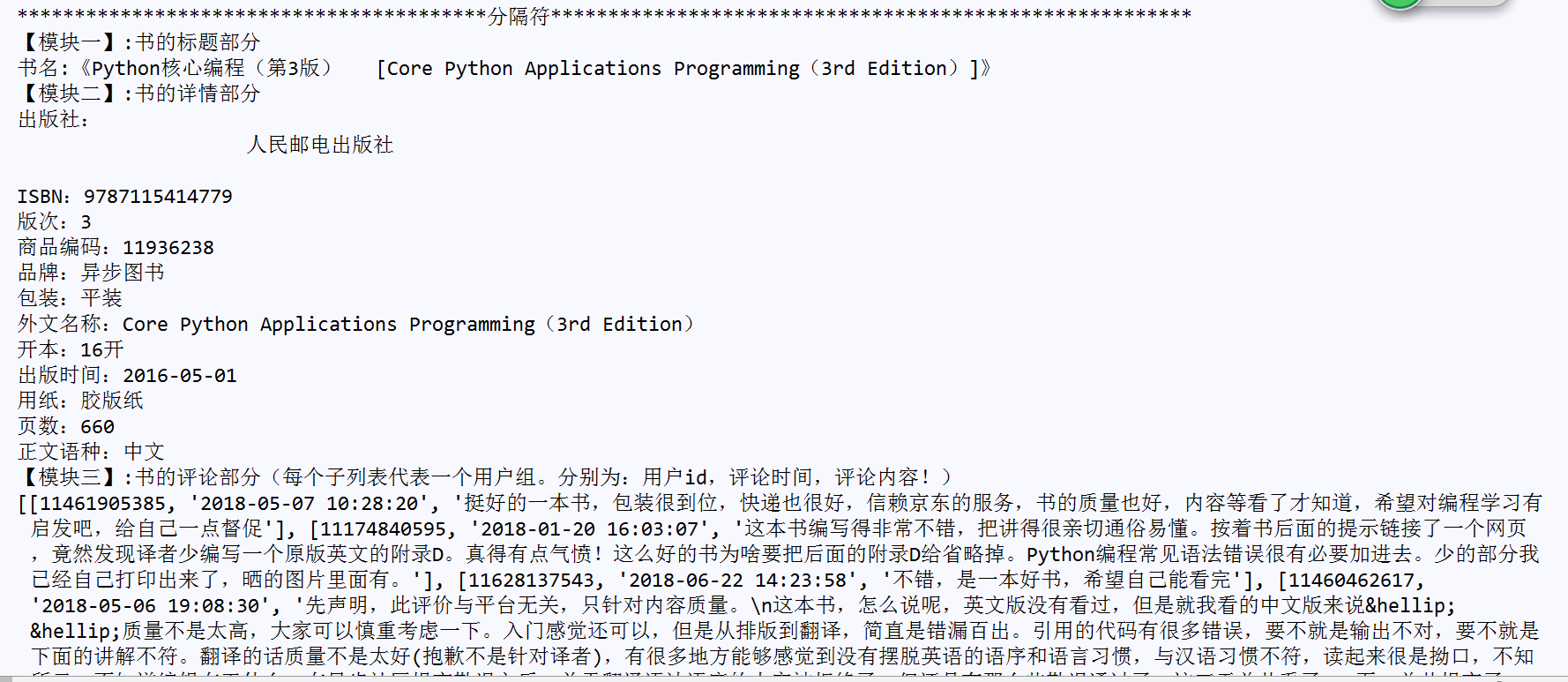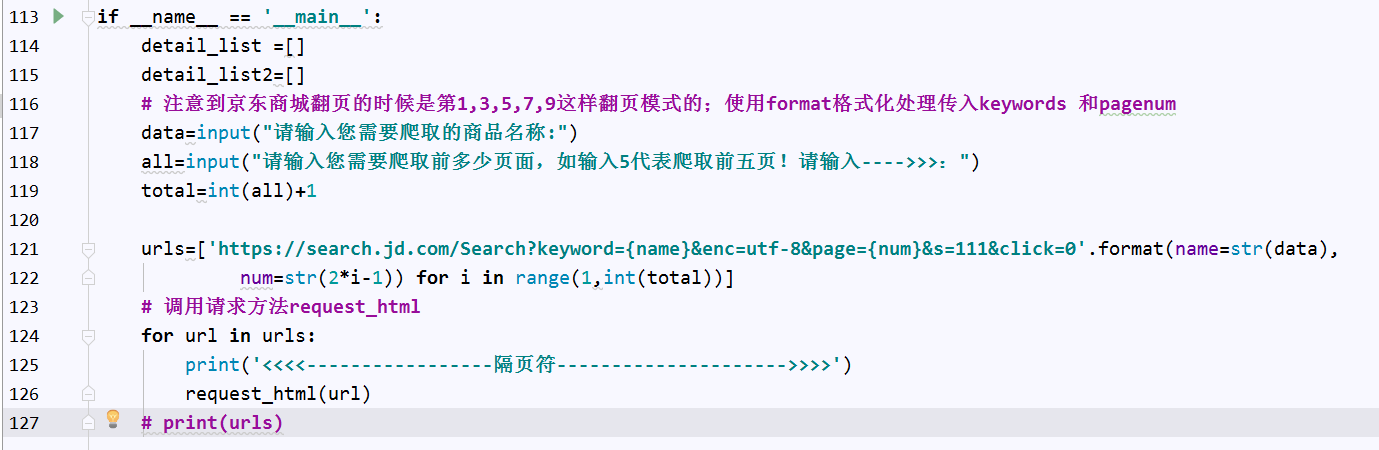
运行状态:


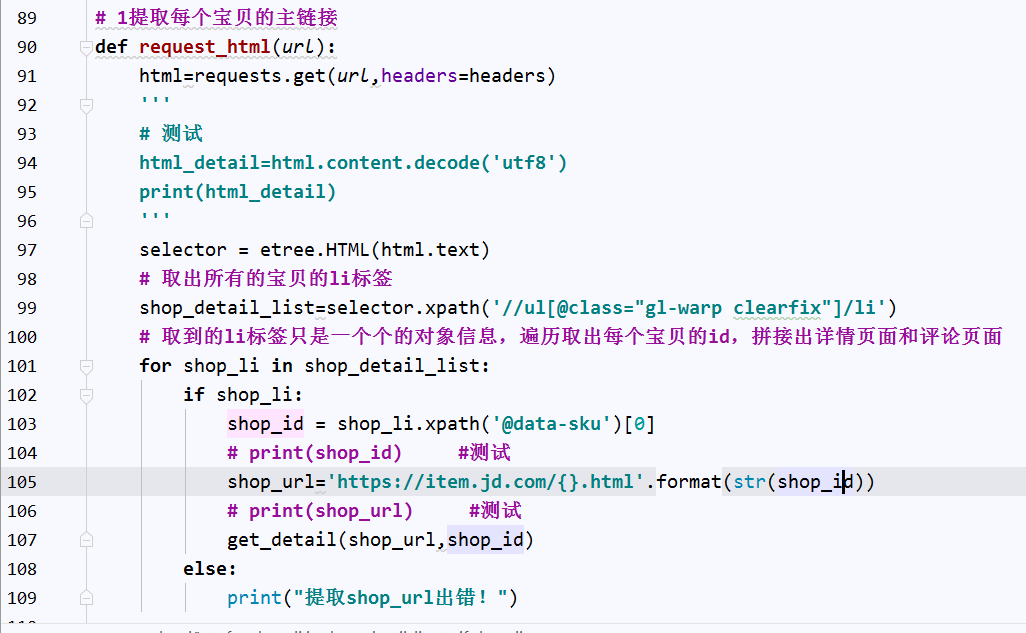



分析:
京东的评论信息其实是异步加载模式的,很难通过一个固定的url链接来爬取到所有的评论信息,所以就需要找相应的json文件。
找到network里的js
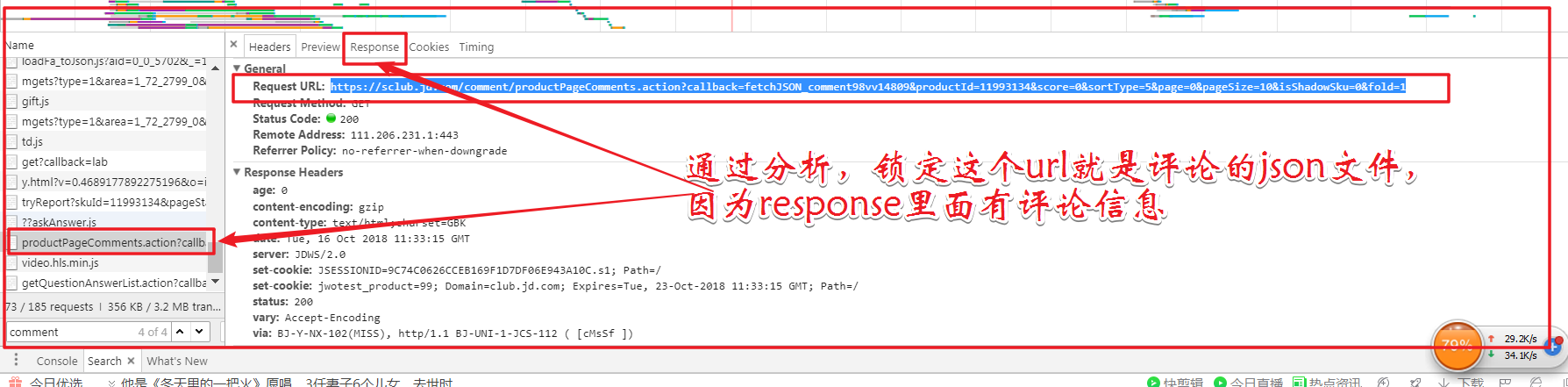
所以可以通过写一个方法来爬取该页面的评论信息
# 3 评论比较难抓(json文件形式),写一个处理方法 def get_comment(id): url='https://sclub.jd.com/comment/productPageComments.action?' 'productId={}&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1'.format(str(id)) html=requests.get(url,headers=headers).json() html_num=html['productCommentSummary'] html_comment=html['comments'] print(html_comment)
爬取到还没进行数据处理的结果信息如下,等待下一步信息处理
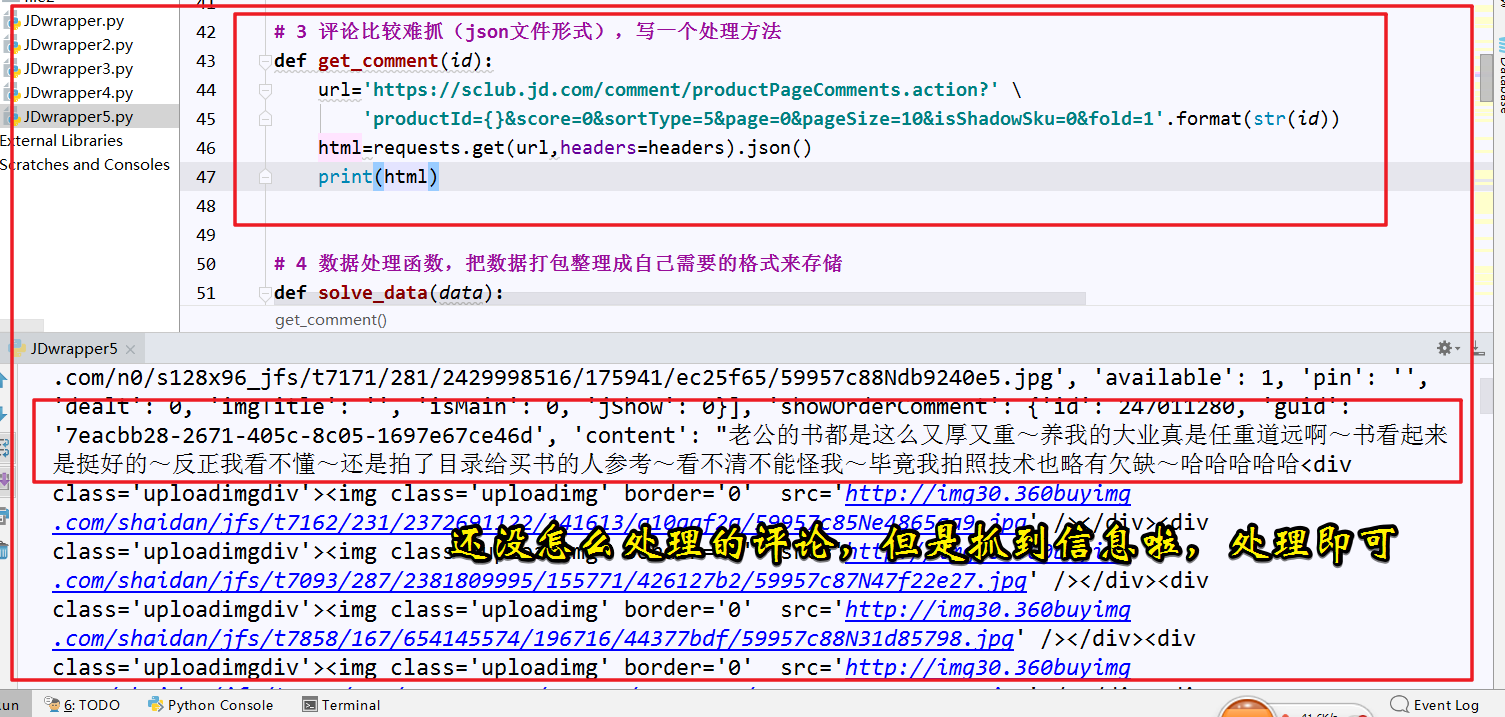
分析爬取到的json文件信息,发现:每个用户的评论信息都是跟在content关键字之后的,可以把它从字典中取出来
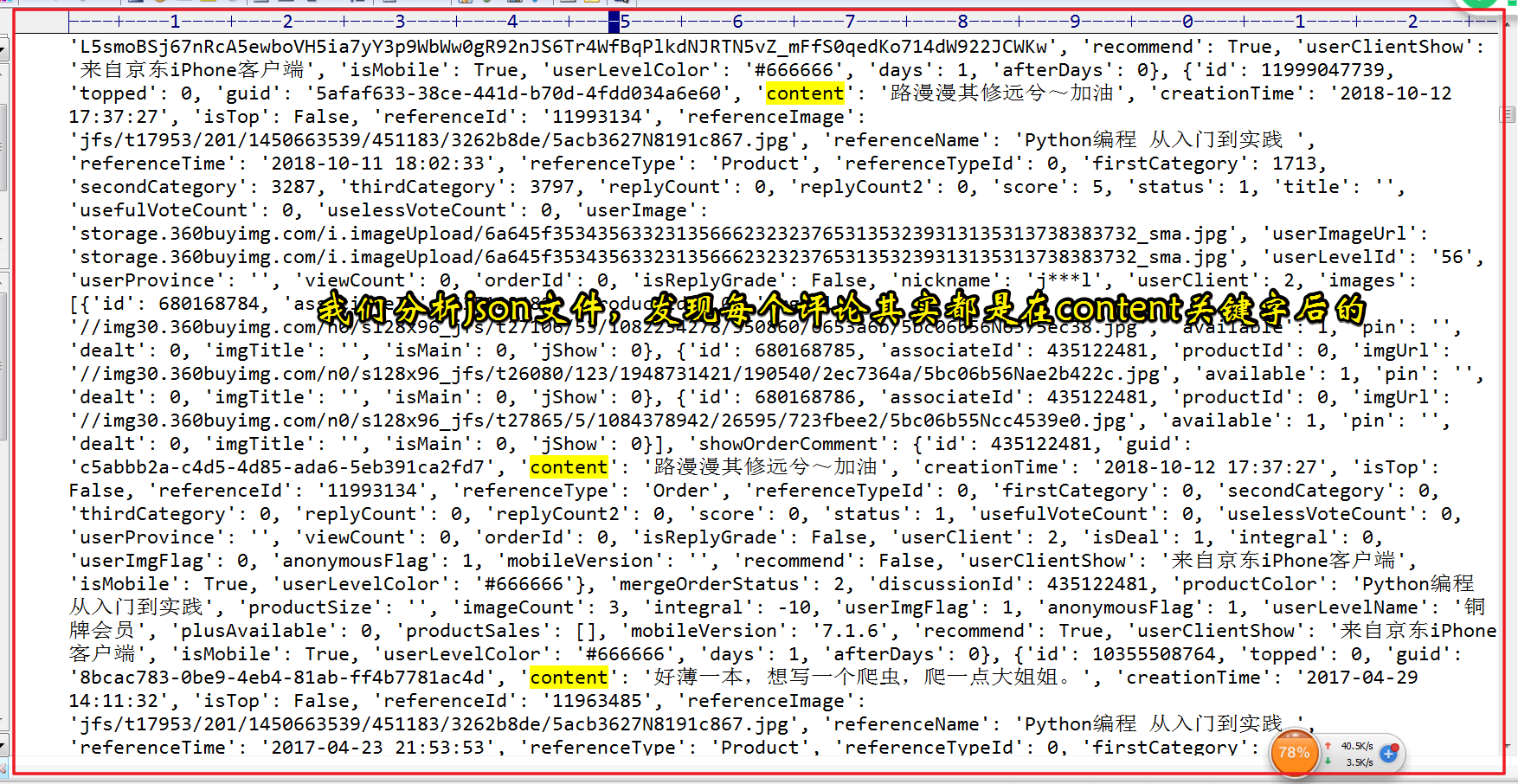
提取content内容,可以考虑用两种办法,这里第一种是可以遍历找出,第二种是可以通过正则表达式来实现。
# 3 评论比较难抓(json文件形式),写一个处理方法 def get_comment(id): comment_dict={} comment_list=[] comment_list2=[] url='https://sclub.jd.com/comment/productPageComments.action?' 'productId={}&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1'.format(str(id)) html=requests.get(url,headers=headers).json() # 爬取评论数的信息页面 html_num=html['productCommentSummary'] # 爬取评论具体内容的信息页面,下边的html_comment是取出了一个列表 html_comment=html['comments'] for each in html_comment: #each是一个字典,字典中包括评论者id,评论内容 userId=each['id'] comment_time=each['creationTime'] comment_content=each['content'] #append到空的备用列表中去 comment_list.append(userId) comment_list.append(comment_time) comment_list.append(comment_content) # print(comment_list) #把每个用户评论的ID,时间,内容放一个字典里 total_num = len(comment_list) user_num = total_num // 3 for i in range(0,user_num): j=0 comment_dict['用户ID']=comment_list[j] comment_dict['评论时间']=comment_list[j+1] comment_dict['评论内容'] = comment_list[j + 2] j+=3 comment_list2.append(comment_dict) print(comment_list2)
这里把一个用户整理为一个字典,放入一个大的列表中去
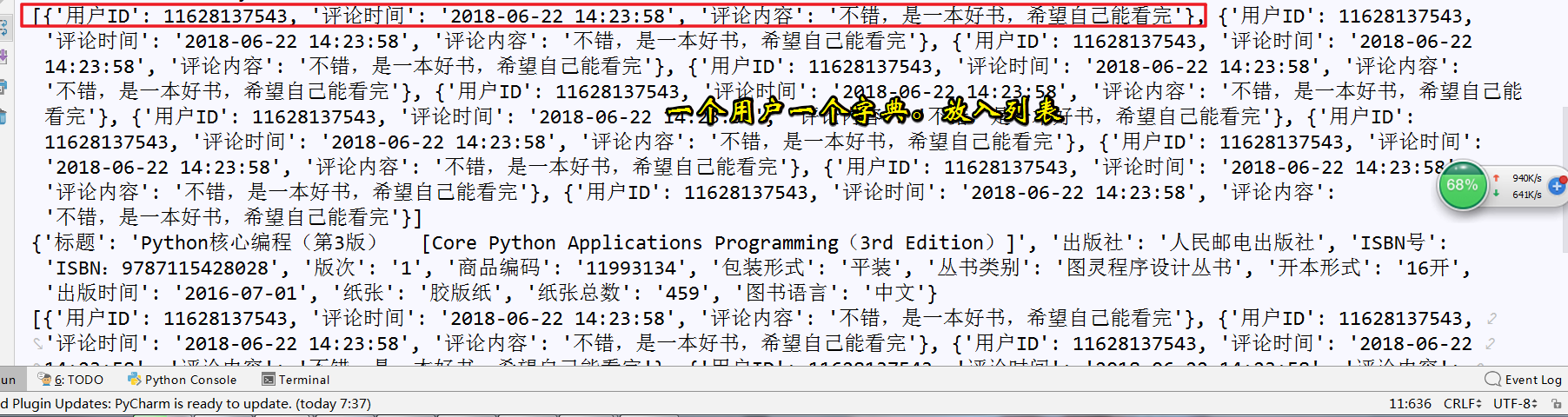
格式化处理数据后的详情信息