人工智能理解常识的数十年挑战,如何让 AI 不再“智障”?
最新一波 AI 进步浪潮,结合了机器学习与大数据,已为我们提供能够对口头命令做出响应的工具,以及可以识别道路前方物体的自动驾驶汽车。
但不得不说,这些所谓“智能”产品的常识基本为零。
亚马逊智能助理 Alexa 与苹果智能助理 Siri 可以通过引用维基百科(Wikipedia)来获取某种植物的信息,但并不知晓将植物放在黑暗中会发生什么;能够识别前方道路障碍物的智能程序,通常也无法理解为何避开人群比避免堵车更加重要。
人工智能要变得像人一样聪明,常识推理能力是其必备的能力之一。但如何让人工智能理解常识,已是一个困扰了人工智能 50 多年的难题。
纽约大学教授欧内斯特·戴维斯(Ernest Davis)已经研究人工智能的常识问题数十年。他认为,理解常识对于推进机器人技术至关重要。机器需要掌握时间、因果关系和社交互动等基本概念,才能展示出真正的智慧。而这正是我们目前所面临的最大障碍。
常识问题是人工智能的重大盲点
“常识”一词不仅仅是指一种知识,还可以指对这种知识的看法,不是特定的学科领域,而是一种广泛可重复使用的背景知识,几乎是每个人都应该拥有的。
例如,人去餐馆是去吃食物而不仅仅是点菜和付钱的;把火柴扔到一堆木柴上,意味着有人在尝试生火。大多数常识知识的隐式属性,使得这类知识很难被明确表示出来。
虽然早期研究者认为,可以通过把现实世界的事实都记下来构建一个知识库,以此作为实现自动化常识推理的第一步。然而这种做法实现起来远比听起来难得多。无论知识库收集多么丰富多彩的知识,都难免无法捕捉到人类常识推理中常出现的模棱两可和关联重叠的情况。
IBM 沃森(Watson)计算机系统前首席研究员大卫·费鲁奇(David Ferrucci),如今正在向新发明的机器解释一个儿童故事。在这个故事中,费尔南多(Fernando)和佐伊(Zoey)买了一些植物。费尔南多将他的植物放在窗台上,佐伊则将植物扔在她黑暗的房间里。几天后,费尔南多的植物长得郁郁葱葱,佐伊的植物叶子却已变成褐色。在佐伊把植物转移到窗台上后,叶子又开始焕发生机。
费鲁奇面前的屏幕上出现了一个问题:“费尔南多将植物放在窗台上是因为他想让植物更健康吗?这是否有意义?洒满阳光的窗户光线充足,植物就能保持健康。”
这个问题是费鲁奇创造的人工智能系统努力学习世界运作方式的部分内容。对于我们而言,能轻易理解费尔南多将植物放在窗台上的缘由。但对于 AI 系统而言,这一点很难掌握。
因为在阅读文本时,人类可以做出常识性的推理,这些推理对理解叙事性故事(narrative,由具有逻辑、因果等关系的events构成)起支撑作用。要让机器和人类一样具有这个能力,就必须无限地获取相关常识,越准确越好。
费鲁奇和他的新公司元素认知(Elemental Cognition)希望通过教会机器获取并应用日常知识,来与人类进行交流、推理并观察周围环境,以此解决现代人工智能中的重大盲点。
研究人员通过在屏幕上单击“是”按钮,就能回答费尔南多植物的问题。而在某处的服务器上,一个称为 CLARA 的 AI 程序将该信息添加到事实与概念库中,学习这种人造的常识。就像一个永远好奇的孩子一样, CLARA 不断向费鲁奇询问有关植物故事的问题,试图“理解”事物为何以这种方式展现出来。
“我们能否让机器真正理解他们所阅读的内容?” 费鲁奇说,“这非常困难,但正是元素认知想要实现的目标。”
AI 理解常识的过程
尽管人工智能领域开始研究常识问题已久,然而进展还是慢得出奇。一开始,研究人员尝试将常识翻译成计算机语言——逻辑。研究人员认为,如果能够将人类常识中所有不成文的规则用计算机语言写下来,那计算机就能够像做算术一样,利用这些常识进行推理。
不过,这种方法依赖人工,不具有扩展性。新西兰奥克兰大学人工智能研究人员 Michael Witbrock 表示,能够方便地用逻辑形式表示的知识量,原则上是有限的,并且事实证明这种方法实现起来非常艰巨。
另一条通往常识的道路,是使用神经网络进行深度学习。研究人员设计这样的人工智能系统来模拟生物大脑中相互连接的神经元层,在不需要程序员事先指定的情况下学习模式。
在过去的十几年间,经过大量数据训练的越来越复杂的神经网络,已经变革了计算机视觉和自然语言处理领域的研究。然而,虽然神经网络具有较强的智能能力以及灵活性(实现自动驾驶,在国际象棋、围棋中击败世界一流的玩家),但是这些系统却仍然会犯很多令人啼笑皆非的常识性错误(有时甚至是致命的)。
在 2011 年,沃森计算机通过解析大量文本,找到了智力竞赛节目《危险边缘》问题的答案,但在理解常识方面仍有很多局限性。随后,人工智能领域的深度学习开始兴起。通过教计算机识别人脸,转录语音并向它们提供大量数据来执行其他操作,深度学习已得到广泛应用,且近几年在语言理解方面取得了新的突破。目前可以通过特定的人工神经网络生成问题答案或者具有连贯性的文本模型。谷歌、百度、微软,以及 Open AI 都已创建更复杂的语言处理模型。
以 CLARA 为例,其目标是通过明确逻辑规则,将深度学习与构建知识到机器中的方式相结合,主要使用统计方法来识别句子中的名词和动词等概念。
有关特定主题的知识来源于亚马逊 Mechanical Turkers,随后会内置到 CLARA 的数据库中。CLARA 再将其给出的事实与深度学习语言模型结合在一起,产生自己的常识。此外,CLARA 还能通过与用户互动来收集常识。如果遇到分歧,它可以询问哪种陈述最为准确。
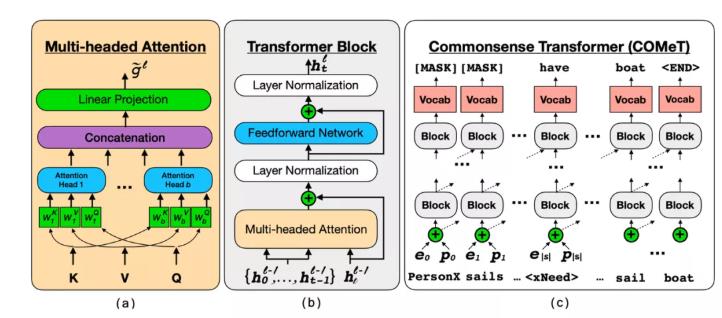
CLARA 并非唯一可以理解常识的人工智能。华盛顿大学教授,艾伦人工智能研究所研究员 Yejin Choi 与合作者近期提出自动构建常识知识库模型 COMET(Commonsense Transformers),融合了符号推理与深度学习两种截然不同的人工智能方法。
与纯深度学习语言模型相比,COMET 在交谈或回答问题时的理解错误频率更低。因为COMET 与许多使用规范模板存储知识的传统知识库正好相反,常识知识库仅存储松散结构的开放式知识描述。通过借鉴 Transformer 上下文感知语言模型,在 ATOMIC 和 ConceptNet 知识库中选取种子知识训练集进行预训练,使得模型可以自动构建常识知识库,给定头实体和关系,生成尾实体。
尽管常识建模存在挑战,但 Yejin Choi 的调查显示,将来自深层预训练语言模型的隐式知识转移到常识图中生成显式知识时,结果很有希望。研究的实证结果表明,COMET 能产生被人类认可的高质量新知识,其最高1位的精确度能达到 77.5%(ATOMIC)和 91.7%(ConceptNet),接近人类的表现。使用常识生成模型COMET进行自动构建常识知识库,或许能成为知识抽取构建知识库的合理替代方案。
“如果我生活在一个没有其他人(可以交谈)的世界里,我仍然能够拥有常识——我仍然能够理解这个世界是如何运转的,并且对我应该看到什么和不应该看到什么抱有预期。”布朗大学的计算机科学家 Ellie Pavlick 说,他目前正在研究如何通过在虚拟现实中与人工智能系统互动来教授它们常识。
对 Pavlick 来说,COMET 代表了“真正令人兴奋的进步,但缺少的是实际的参考方面”。“苹果”这个词不一定就是真的苹果,这种意义必须以某种形式存在,而不是语言本身。”
Salesforce 公司的高级研究科学家 Nazneen Rajani 也在追求类似的目标,但她认为,神经语言模型的全部潜力还远未开发出来。她正在研究神经语言模型是否能学会推理涉及基础物理的常识情景,比如一个装有球的罐子被打翻通常会导致球掉出来。
“现实世界真的很复杂,”Rajani 说,“但自然语言就像一个低维度的代理,反映了现实世界的运作方式。神经网络可以通过文本提示来预测下一个单词,但这不应该是它们的限制。他们可以学习更复杂的东西。”
随着AI理解常识研究的不断突破,或许很快,我们身边的人工智能助手就会变得越来越聪明和善解人意。