一、Redis的事务
1.是什么
可以一次执行多个命令,本质是一组命令的集合。一个事务中的
所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞
(更多请参见官网事务介绍)
2.能干什么
一个队列中,一次性、顺序性、排他性的执行一系列命令
3.怎么干
摘取官网:

常用如下:
开启一个事务:(MULTI)
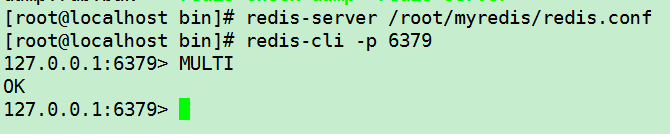
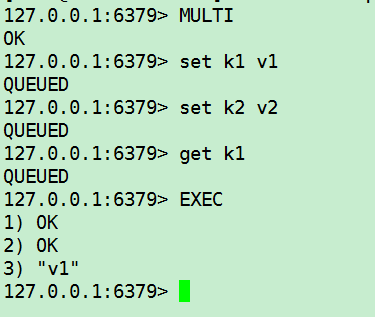
添加若干命令加入队列,执行事务(EXEC)
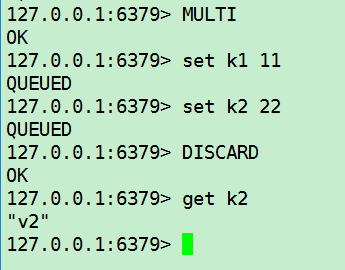
添加操作后不想执行,放弃事务(DISCARD)
一个出错,全体受罚,连坐(一个出错,其它事务内操作均不成功)

谁的命令加入队列时正常执行时报错,则冤头债主,只找它(这里k1的v1不是Integer不能增加)
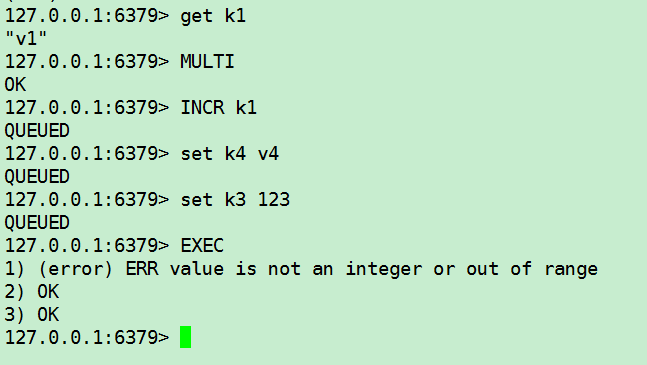
//和上一个的区别就是这个是加入队列时成功,执行时出错,而上一个加入队列时就出错了
所以说,Redis对事务的支持,是部分支持
watch监控
悲观锁/乐观锁/CAS(Check And Set)
悲观锁(会有点像行锁和表锁)
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁
乐观锁(一般用乐观锁,还是乐观点好)
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号(在记录后加一个版本号,通过版本号来判断是否进行了修改)等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,
CAS
redis中使用 check-and-set 操作实现乐观锁
模拟场景:模拟信用卡消费,可用额度:balance,当前欠款:debt
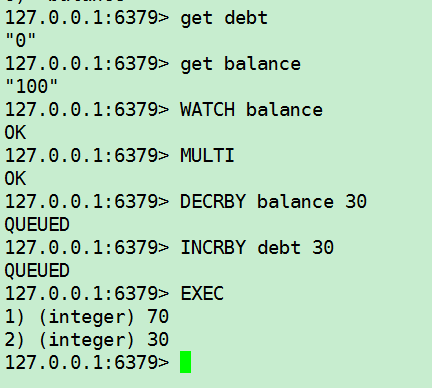
无加塞篡改,先监控再开启multi,保证两笔金额变动在同一个事务内(如果监控的变量在其它事务地方发生了变化,将会报错)
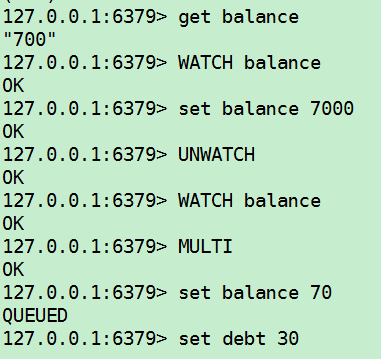
有加塞篡改,监控了key,如果key被修改了,后面一个事务的执行失效(以前一个事务执行结果为准)

UNWATCH(WATCH之后的设值是模拟其它终端进行了修改,实际操作中可用通过boolean等变量来控制,当有人修改时,放弃监控,再获取最新的进行监控修改,直到没有人修改,再开始监控,开启事务)——此命令是取消监控所有key
一旦执行了exec之前加的监控锁都会被取消掉了,不管成功失败,本次操作就清了(操作结束)
小结:
Watch指令,类似乐观锁,事务提交时,如果Key的值已被别的客户端改变,比如某个list已被别的客户端push/pop过了,整个事务队列都不会被执行。
通过WATCH命令在事务执行之前监控了多个Keys,倘若在WATCH之后有任何Key的值发生了变化,EXEC命令执行的事务都将被放弃,同时返回Nullmulti-bulk应答以通知调用者事务执行失败
4.事务三阶段
开启:以MULTI开始一个事务
入队:将多个命令入队到事务中,接到这些命令并不会立即执行,而是放到等待执行的事务队列里面
执行:由EXEC命令触发事务
5.事务三特性
单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
没有隔离级别的概念:队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行,也就不存在”事务内的查询要看到事务里的更新,在事务外查询不能看到”这个让人万分头痛的问题。
不保证原子性:redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
二、Redis的发布和订阅
1.是什么
(兼职做一下发布,实际还是做分布式缓存的)
进程间的一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
2.实例:
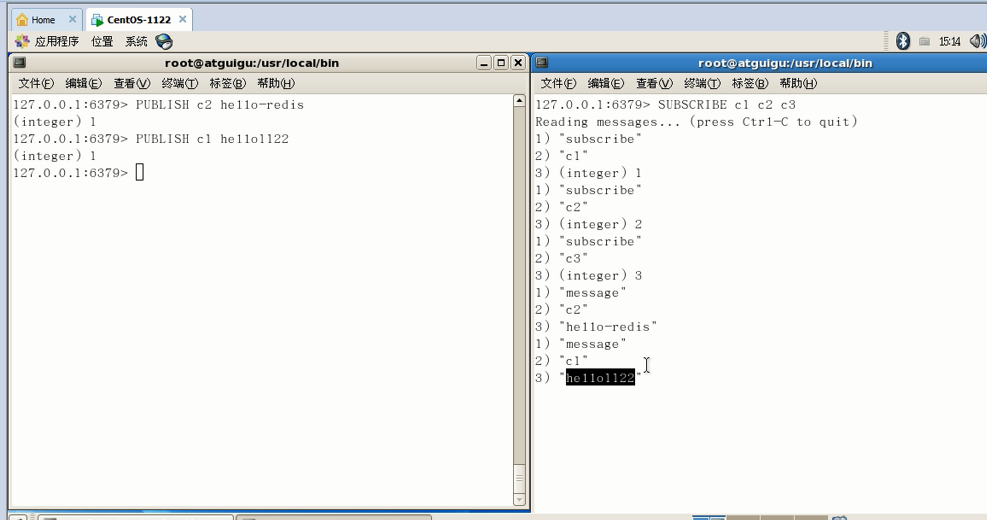
先订阅后发布后才能收到消息,
1 可以一次性订阅多个,SUBSCRIBE c1 c2 c3
2 消息发布,PUBLISH c2 hello-redis
===========================================================================================================
3 订阅多个,通配符*, PSUBSCRIBE new*
4 收取消息, PUBLISH new1 redis2015
左边发布,右边获取:
三、主从复制
1.是什么
行话:也就是我们所说的主从复制,主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
2.能干什么
读写分离 容灾恢复
3.怎么干
配从(库)不配主(库)
从库配置:slaveof 主库IP 主库端口
每次与master断开之后,都需要重新连接,除非你配置进redis.conf文件
info replication
开始实验
拷贝多个redis.conf文件(用于模拟多台机器)
开启daemonize yes
pid文件名字
指定端口
log文件名字
dump.rdb名字
常用3招:其实已经是过时,后面将会由哨兵模式更先进的模式取代
一主二仆
开启3台机器模拟如下:
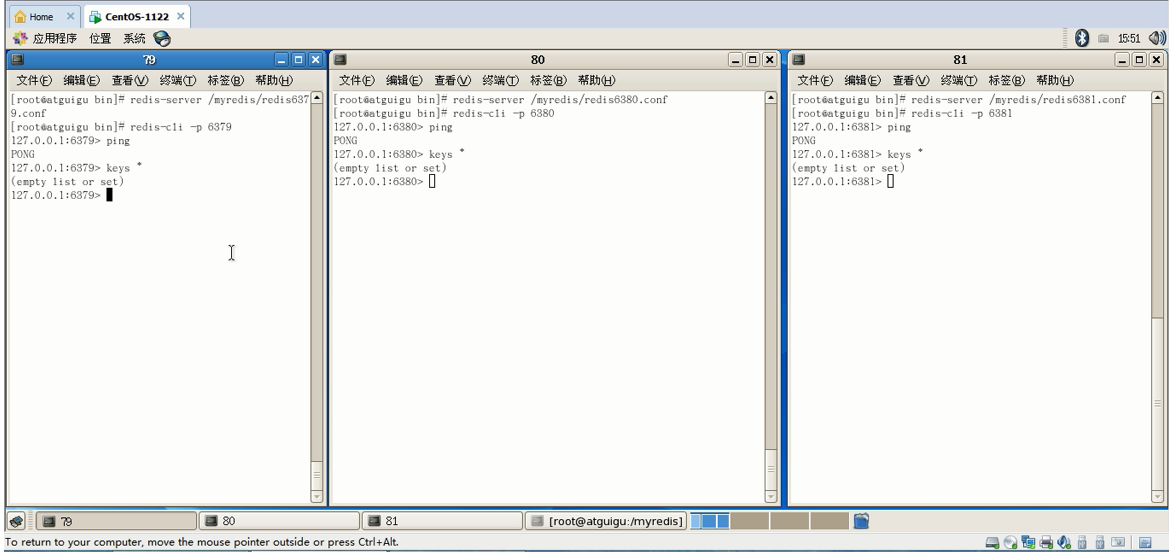
启动情况如下:
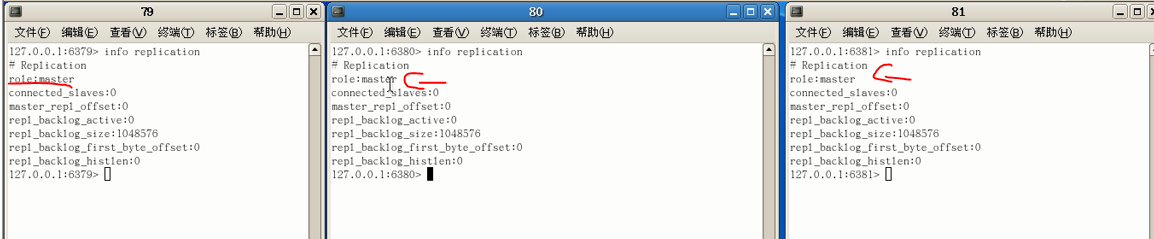
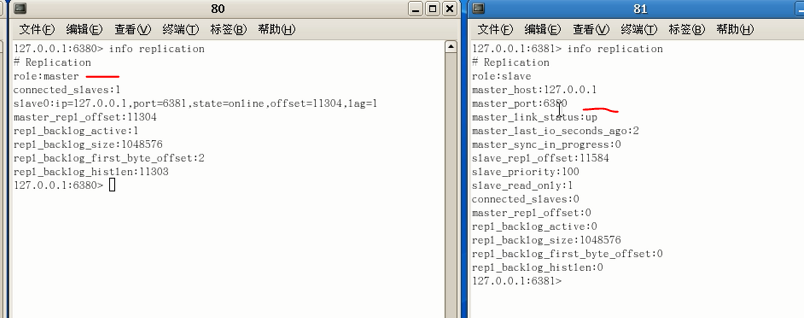
使用 INFO replication: 查看主/从复制信息(此时还是三台主机身份)
使用 slaveof 192.168.1.1 6379进行主从复制:(后两台使用命令后变为从机)
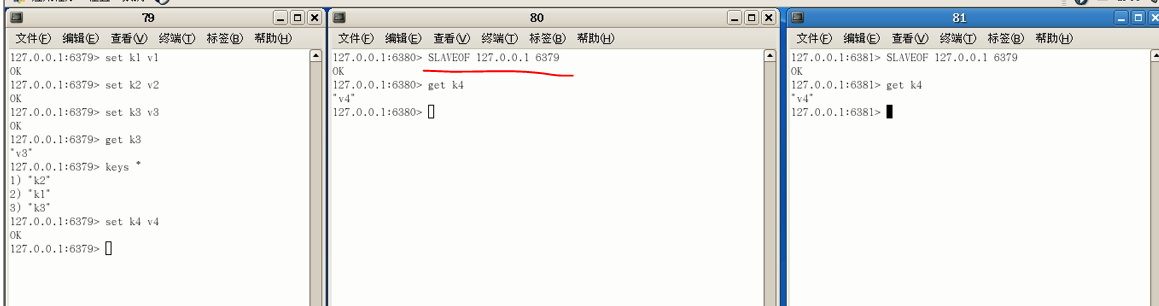
注意,此时从机是可以取得k1 k2 k3的(即使从机是从k4才开始开启备份),也就是说,从机一旦接管,便从头录到尾 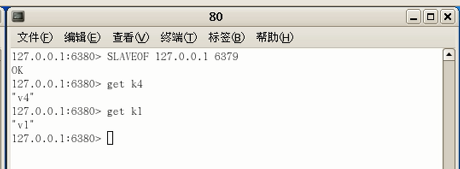
此时查看主机79信息:身份是主机,后跟着两个小弟(从机),再在从机中查看主从复制信息可以看到是slave(从机状态)

假设三台机器都执行相同的命令,思考结果:

//结果:只有主机可以正确执行,从机将会出错。也就是从机无法覆盖主机。
假设主机挂了,思考此时从机是代替主机上位,还是原地待命(假设由你设计,哪种方案)

//主机关机后,从机之前备份的数据是存在的(不然,备份意义何在呢)
可以发现还是从机身份,不过连接状态为down
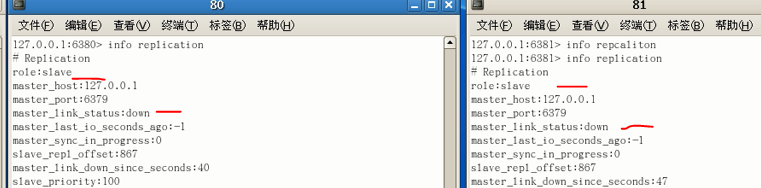
此时再把主机开启,并且进行操作
//可以发现是可以获取到最新的值的。(主机一旦正常,一切照旧)
假设其中一台从机挂了,另外的从机是正常运作的,而主机当然不受影响:

再把从机启动,发现身份信息翻身为主机了
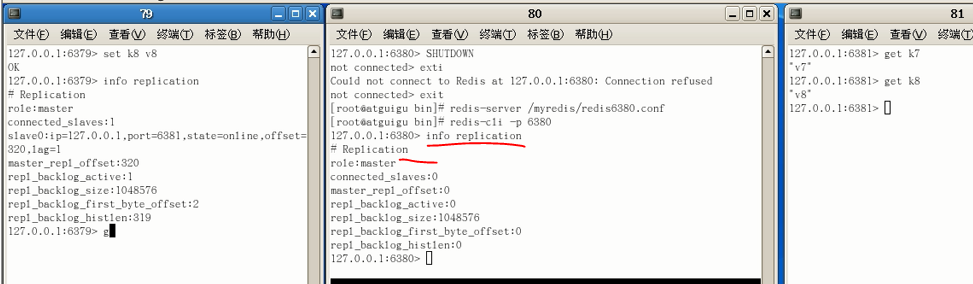
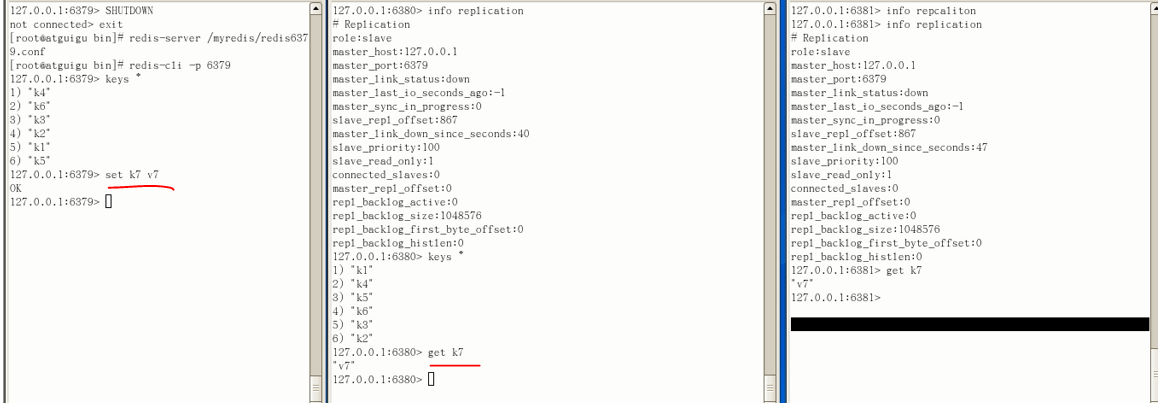
但是其它机器在80SHUTDOWN期间的操作,80的无从获取的;原因是前面说过的,只要从机断开连接(自己挂了),就要重新和主机连接
不然就认为是一台独立的机器而不是从机(除非写进它的配置文件)
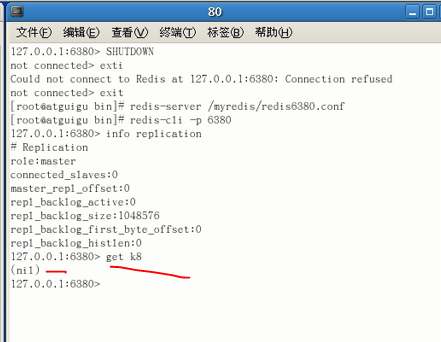
当然了,只要它重新和主机连接,重新作为从机,是可以正常运作的(再增量备份一份,最新的k8也有了):

薪火相传
1.上一个Slave可以是下一个slave的Master,Slave同样可以接收其他slaves的连接和同步请求,
那么该slave作为了链条中下一个的master,可以有效减轻master的写压力。
2.中途变更转向:会清除之前的数据,重新建立拷贝最新的
3.slaveof 新主库IP 新主库端口
原先是80 81挂在79上,变更为81挂80,80依旧挂79

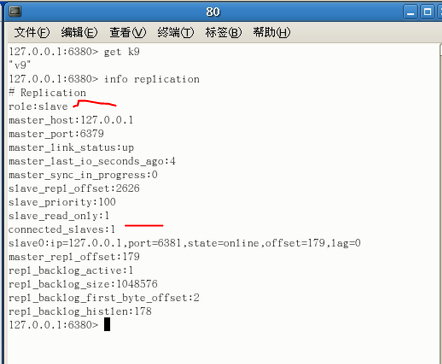
此时查看79主从复制信息:其下只有一个直接从机
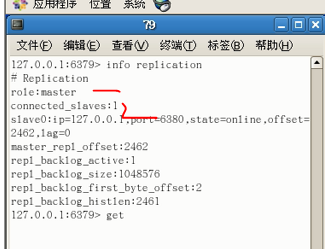
在第一台主机上设值,可以看到直接和间接从机都能成功获取(薪火相传是OK的)
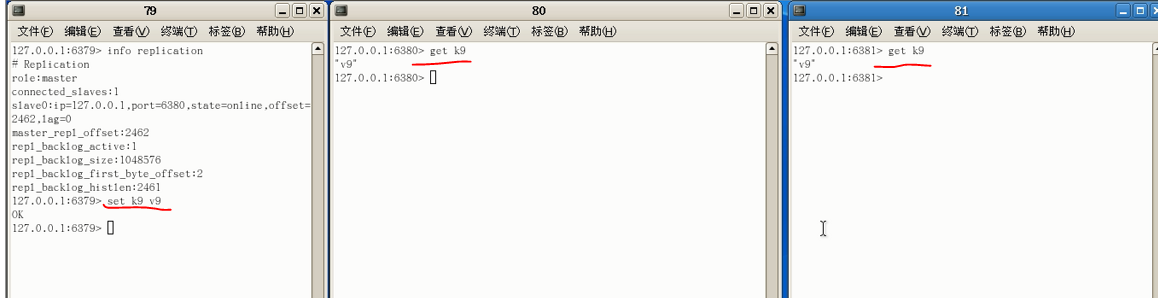
查看80的主从复制信息:总体而言是一个slave,但它同时连接了一个slave(包工头还是打工的,但手下还管了人)
反客为主
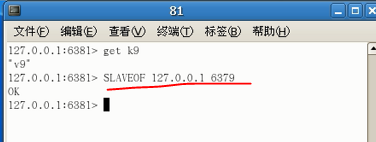
SLAVEOF no one
使当前数据库停止与其他数据库的同步,转成主数据库
先将上一个实验中间接从机81改回来,使环境正常:
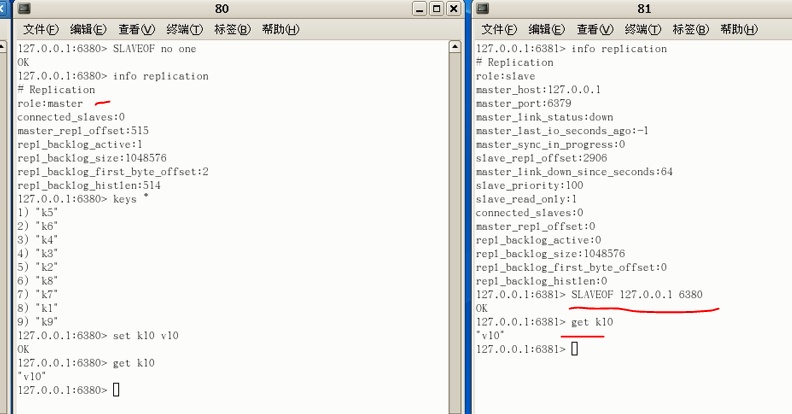
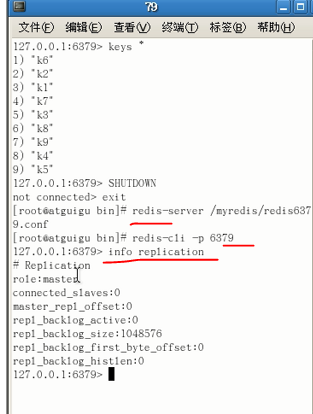
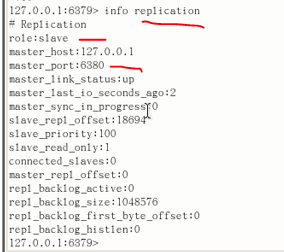
假设主机挂了,我们不再像第一个实验一样,傻傻的等待主机苏醒,而是从从机中选出新主机上位:SLAVEOF no one(不再为奴)

现在主机变更为80,现在81就不傻傻的等了,跟着新主机81混了。格局变更
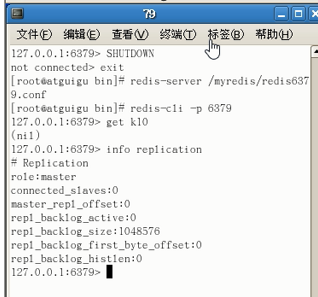
现在老主机再回来,不过目前80 81已经组成新的格局,老主机再次苏醒,可惜无法入局了:
4.复制原理
仔细区分思考、,是增量还是全量
1.slave启动成功连接到master后会发送一个sync命令
2.Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
3.全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
4.增量复制:Master继续将收集到的修改指令,依次发送给slave,完成同步
5.但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
5.哨兵模式(sentinel)
是什么
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
怎么干
调整结构,6379带着80、81
开始实验之前,依旧恢复原始环境(80 81都跟着79走,可以在79查看是否环境正常)
自定义的/myredis目录下新建sentinel.conf文件,名字绝不能错
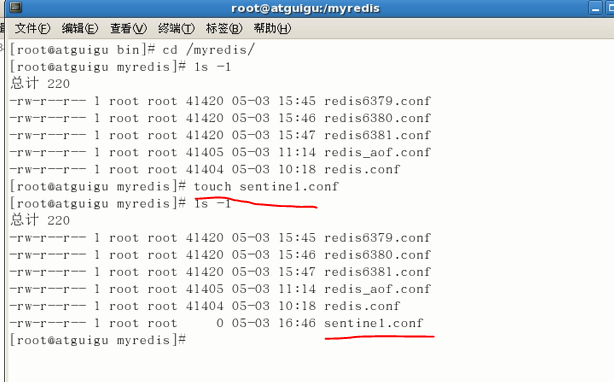
配置哨兵,填写内容
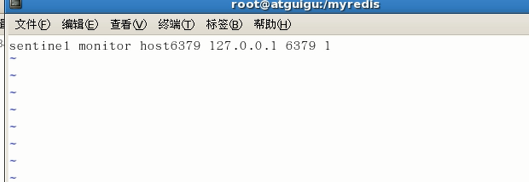
vim sentinel进行配置
sentinel monitor 被监控数据库名字(自己起名字) 127.0.0.1 6379 1
上面最后一个数字1,表示主机挂掉后salve投票看让谁接替成为主机,得票数多少后成为主机
启动哨兵
redis-sentinel /myredis/sentinel.conf
上述目录依照各自的实际情况配置,可能目录不同

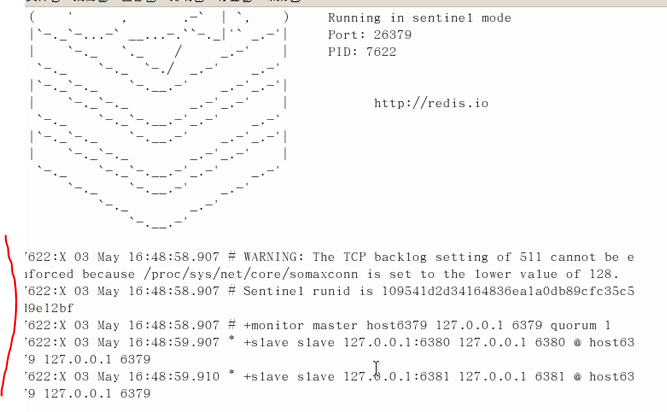
此时主机出现故障,哨兵开始工作:
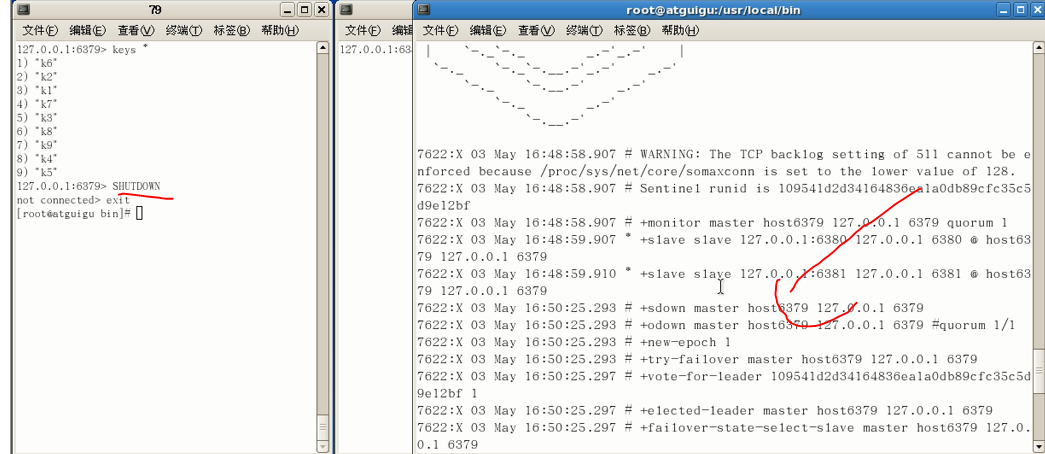
选出主机,更换格局:
倘若此时老的主机回来,哨兵模式下会有何变化:
开始启动是master,经哨兵监控调剂,成为从机!
上述实验为监控一个master,实际:一组sentinel能同时监控多个Master
6.复制的缺点
复制延时
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。