一、前言
1、最近好多人都在问,in和not in到底走索引吗?
2、not in的性能怎么样?
基于上面的2个问题,我们具体的测试一下,实践胜于雄辩。。。
二、in和not in是否走索引
1、准备数据
--1.创建person表 CREATE TABLE person( [id] [int] NULL, [name] [nvarchar](50) NULL, [age] [int] NULL ) --插入数据 DECLARE @i int = 0; BEGIN TRAN SET @i = 10; WHILE (@i < 10000) BEGIN INSERT INTO customer.dbo.person VALUES (@i, substring(convert(varchar(1000),newid()),2,5),@i /5); SET @i += 1; END; COMMIT TRAN; --创建索引 CREATE NONCLUSTERED INDEX id_index ON person(id)
2、测试in是否走索引

注: 该执行计划发生了二次查找(RID Lookup),因为索引里只有id的信息,所以在索引页中查到这条记录后,需要通过RID(有主键通过主键)去数据页里查询其他的字段;
3、测试not in是否走索引
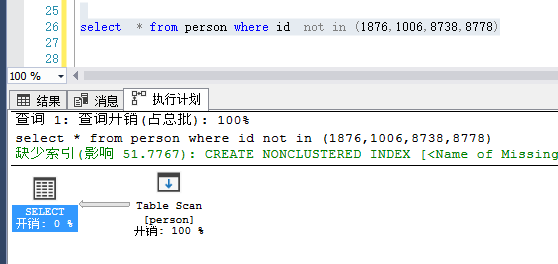
这里使用not in后,发生了全表扫描,没有走索引,那么就能确认not in不走索引吗?接着往下看:

注:这里select后面只查询id字段,因为要是写*的话,not in后面要写好多值,才能走索引,因为查询结果的数据多的话,SQLServer数据库引擎会认为还不如走全表扫描呢。不过这也无所谓,我们只是要测试一下not in是否走索引,所以看到not in发生了全表扫描,不能就认为not in 这个语法不走索引了;
三、not in的性能测试
1、再创建一张addressdetail表
--创建addressdetail表 CREATE TABLE addressdetail( [id] [int] NULL, [tname] [nvarchar](20) NULL, [depart] [nvarchar](50) NULL, [city] [nvarchar](20) NULL ) --插入数据 DECLARE @i int = 0; BEGIN TRAN SET @i = 14000; WHILE (@i < 17000) BEGIN INSERT INTO customer.dbo.addressdetail VALUES (@i, substring(convert(varchar(1000),newid()),2,5), substring(convert(varchar(1000),newid()),2,8), substring(convert(varchar(1000),newid()),2,3) ); SET @i += 1; END; COMMIT TRAN; --创建索引 create nonclustered index ind_id on addressdetail(id)
注:2张表(person和addressdetail)的id都允许为null,并且都是索引列
2、查看not in的执行计划
select * from person where id not in (select id from addressdetail )

注:在图中我们可以看到有一个Row Count Spool(Lazy Spool)操作,该操作就是确认addressdetail表中的id列是否有null值(因为该列的属性是允许为null的,所以SQLServer必须额外确认),并且该操作占用的开销也比较多,接近一半的查询成本,因此在这一步是比较浪费性能的;
3、使用 not exists 代替not in ,对比SQL执行计划的查询开销
--查询not in的执行计划 select * from person where id not in (select id from addressdetail ) --使用 not exists 代替not in 查看SQL的执行计划 select * from person p where not exists (select * from addressdetail b where p.id=b.id)
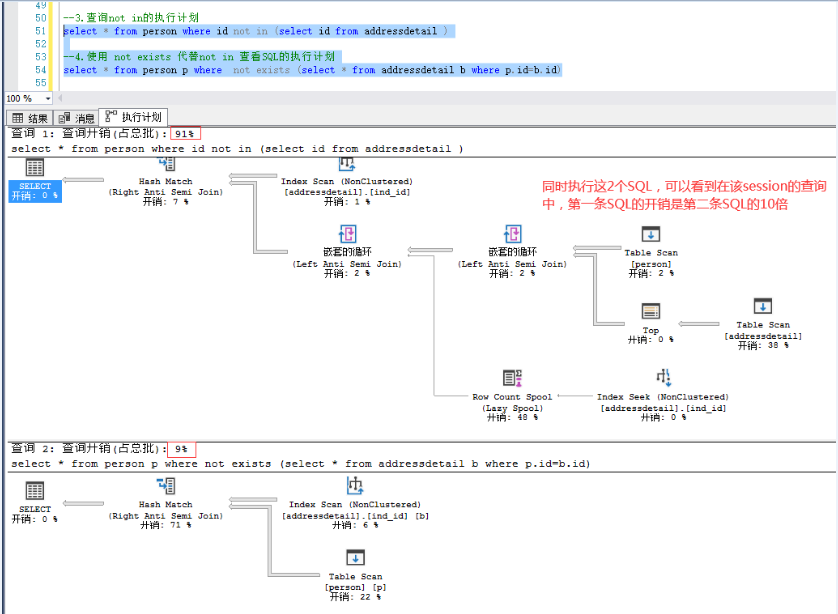
注:由上图可以看出,使用not in的SQL的查询开销是使用not exists的SQL的10倍,仅仅是not in需要确认id列中是否有null值;
当然这个10倍这个值是不准确的,因为这个和2张表的数据量有关,但是可以肯定的是not in的查询性能确实是多了一步校验null值的步骤,所以会降低性能。
4、对比not in 和not exists的IO情况
--not in set statistics io on select * from person where id not in (select id from addressdetail ) --not exists select * from person p where not exists (select * from addressdetail b where p.id=b.id)

注:由上面可以看出not吃掉的IO很高
5、not in的结果准确性
由上面的测试,很容易看出使用not in语法是会降低SQL性能的,但是抛去性能的原因,使用not in 还有可能使查询的结果不准确;
(1)结果不准确主要是和NULL值进行对比的时候,可能会导致结果不准确,我们知道null值并不是一个值,任何与NULL值进行比对的二元操作结果都是null,包括null值本身;
(2)比对的结果为null时,转换为Bool类型的结果就是False;
(3)结果不准确的示例
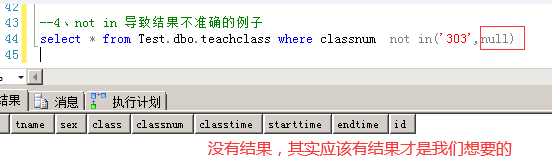
(4)为什么结果不准确
--not in 语句 select * from Test.dbo.teachclass where classnum not in('303',null) --not in('303',null) 等价于下面的语句 select * from Test.dbo.teachclass where classnum<> '303' and classnum<> null
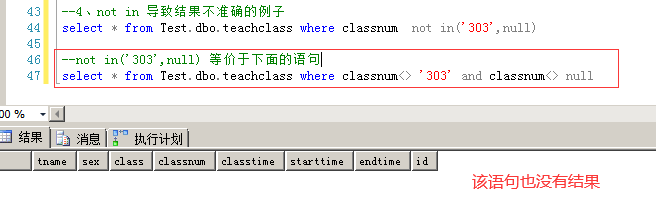
注:把not in的where条件语句等价用and连接,结果也为null,因为上面说了任何值与null值进行二元操作都为null,并且转换为bool都是false,所以再做and,结果都是false,所以最后没有结果;
解决办法:使用not Exists作为替代。Exists操作符不会返回null,只会根据子查询中的每一行返回true或者false,当遇到null时,只会返回false,不会因为某个null值导致整个查询返回空。
四、总结
1、not in和in走不走索引,是视情况而看的,不能绝对的说in和not不走索引;
2、对于数据量大的表,使用IN和NOT IN往往效率很低,如果字段值允许为null,还有可能出现结果不准确的情况,所以在尽量避免使用not in;
3、如果列的属性是not null 的话,是不会产生Row Count Spool(Lazy Spool)操作步骤的;
