一、总结
1、背景
将一个临时表的数据通过分区转换到一个分区表的新分区的时候,导致数据库查询的时候走了全部扫描,即使是查旧分区里的数据,也是走的全表扫面;
2、通过测试,做完分区转换后,最好rebuild一下索引,不然执行计划会出错,如果数据量大的话,是致命的问题;
3、解决办法
给临时表创建索引,分区转换的时候添加including indexes,转换之后的索引就不会失效,详细测试步骤见第三部分;
二、模拟演示
1、创建分区表
create table student ( id int, name varchar2(20), datet varchar2(20) ) partition by range(datet) ( partition p01 values less than('20200802'), partition p02 values less than('20200803'), partition p03 values less than('20200804') )
2、创建本地索引
create index ind_date on student(datet) local;
3、插入数据
insert into student values(1,'jack','20200801'); insert into student values(2,'rose','20200802'); insert into student values(3,'ksk','20200801'); insert into student values(4,'wade','20200803'); insert into student values(5,'sjkj','20200801'); insert into student values(6,'dskj','20200803'); insert into student values(7,'dsku','20200802'); insert into student values(8,'dsuk','20200801');
4、查看分区索引的状态
select index_owner,index_name,partition_name,status,tablespace_name from dba_ind_partitions where index_name='IND_DATE'
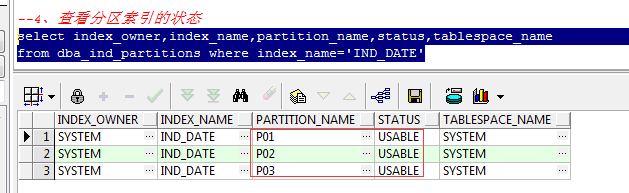
注:可以看到3个分区的状态都是USABLE
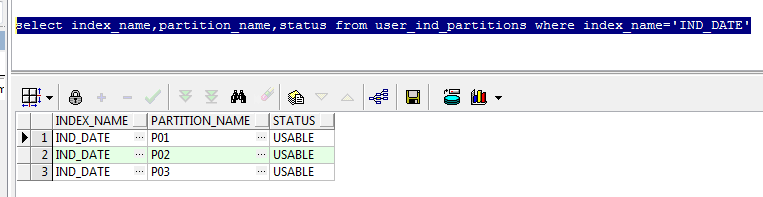
select index_name,partition_name,status from user_ind_partitions where index_name='IND_DATE'
5、创建一张临时表并插入数据
--创建临时表,字段要和分区表的一致 create table student_tmp ( id int, name varchar2(20), datet varchar2(20) ) --插入数据 insert into student_tmp values(20,'dsakdjfgfg','20200804'); insert into student_tmp values(21,'dsakdj','20200804'); insert into student_tmp values(22,'dssdgfdj','20200804'); insert into student_tmp values(23,'dsakdjllgf','20200804');
6、给分区表student添加一个新分区(后面要把临时表的数据插入到该新分区)
--添加新分区 alter table student add partition p04 values less than('20200805') --查看表的所有分区 select partition_name from user_tab_partitions where table_name='STUDENT'; --查看分区的状态 select index_owner,index_name,partition_name,status,tablespace_name from dba_ind_partitions where index_name='IND_DATE'
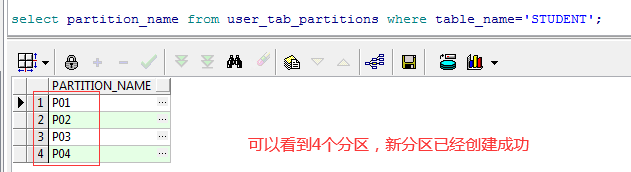
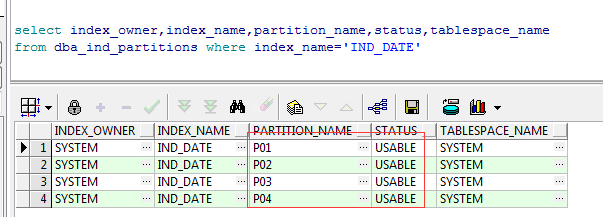
注:这个时候可以看到4个分区的状态都是USABLE
7.分区转换(把临时表的数据转换到分区表的新分区)
alter table student exchange partition p04 with table student_tmp;
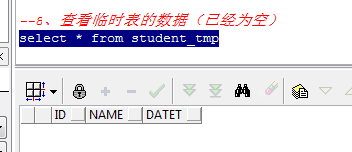
8、查看临时表的数据(已经为空)
select * from student_tmp
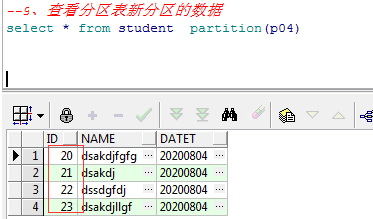
9、查看分区表新分区的数据
select * from student partition(p04)
10、查看分区表的新分区索引是否失效
select index_owner,index_name,partition_name,status,tablespace_name from dba_ind_partitions where index_name='IND_DATE'
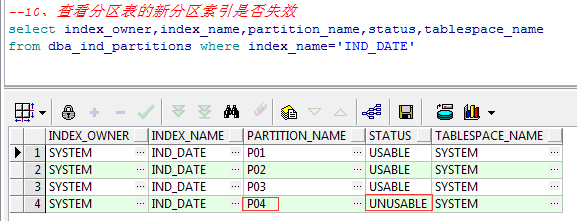
注:可以看到新分区的索引是失效的
11、查询新分区的数据,看执行计划是否走索引
set autotrace on select * from student where id =20;

注:可以看到查询新分区里的数据,走的是全表扫描
12、查看不在新分区的数据,看执行计划是否走索引
set autotrace on select * from student where id =1;
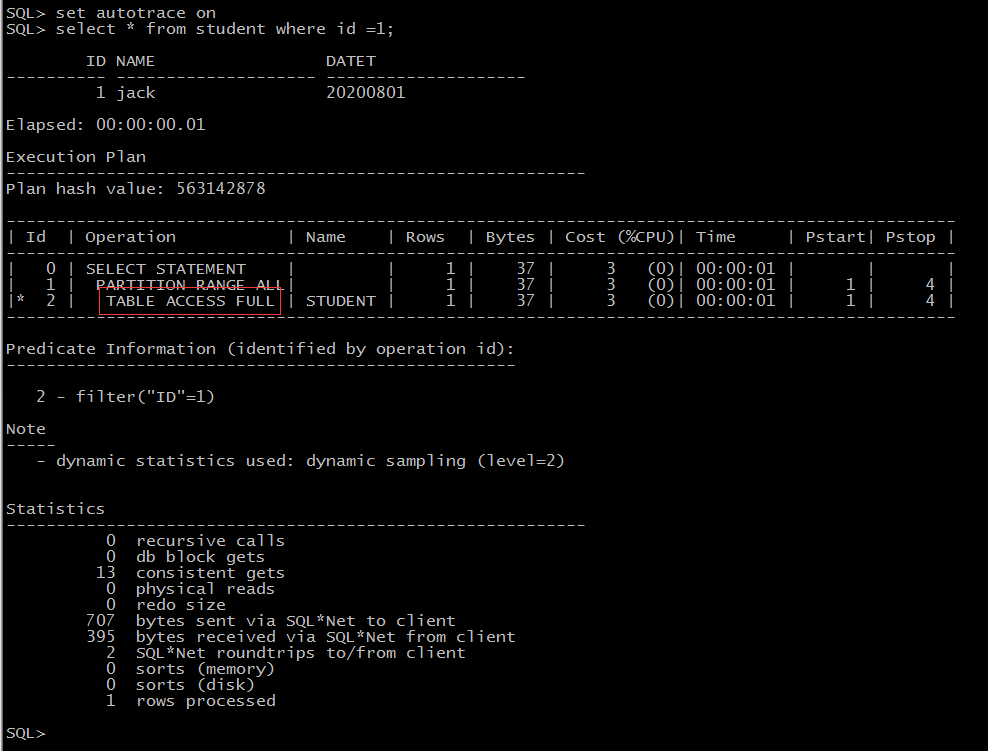
注:看结果,即使是不在新分区里的数据,走的也是全表扫描
三、解决办法
1、创建分区表people
create table people ( id number, name varchar2(20), time date ) partition by range (time) ( partition p01 values less than (to_date('20200102 00:00:00','yyyymmdd hh24:mi:ss')), partition p02 values less than (to_date('20200103 00:00:00','yyyymmdd hh24:mi:ss')), partition p03 values less than (to_date('20200104 00:00:00','yyyymmdd hh24:mi:ss')) )
2、创建本地索引
create index ind_p_id on people(id) local;
3、插入数据
--p01 declare i number; begin for i in 1..20 loop insert into people values(i,'ms',to_date('20200101 12:00:00','yyyymmdd hh24:mi:ss')); end loop; end; --p02 declare i number; begin for i in 21..50 loop insert into people values(i,'ms',to_date('20200102 12:00:00','yyyymmdd hh24:mi:ss')); end loop; end; --p03 declare i number; begin for i in 51..100 loop insert into people values(i,'ms',to_date('20200103 12:00:00','yyyymmdd hh24:mi:ss')); end loop; end; --查看个分区的数据 select * from people partition(p01) select * from people partition(p02) select * from people partition(p03)
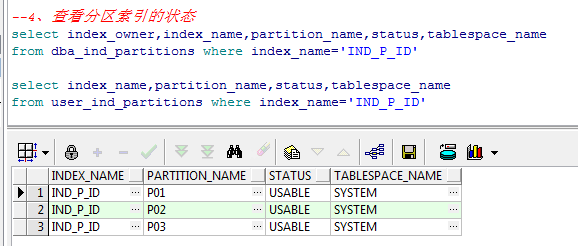
4、查看分区索引的状态
select index_owner,index_name,partition_name,status,tablespace_name from dba_ind_partitions where index_name='IND_P_ID' select index_name,partition_name,status,tablespace_name from user_ind_partitions where index_name='IND_P_ID'
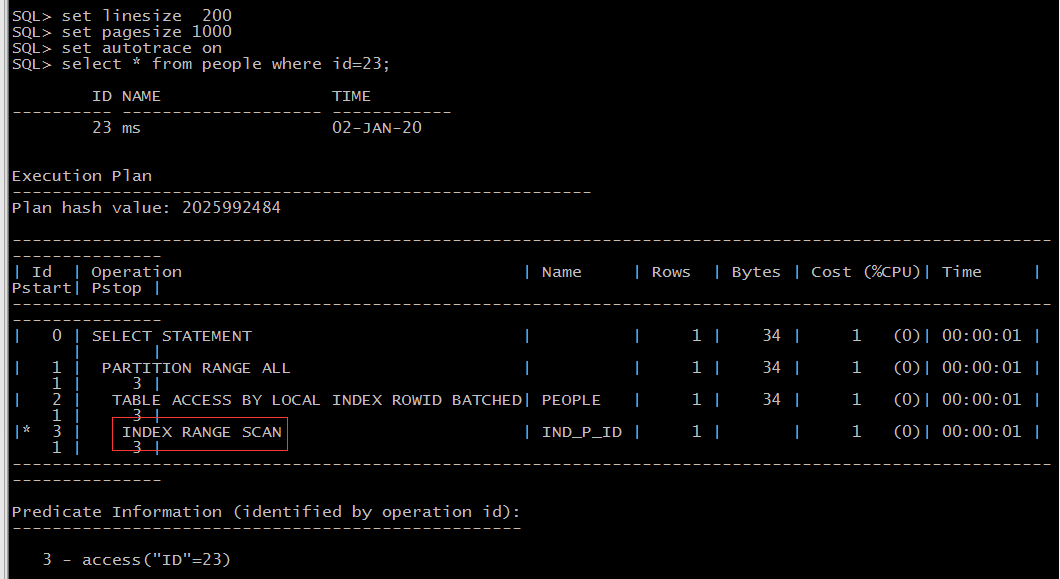
5、查看一条数据,看是否走索引
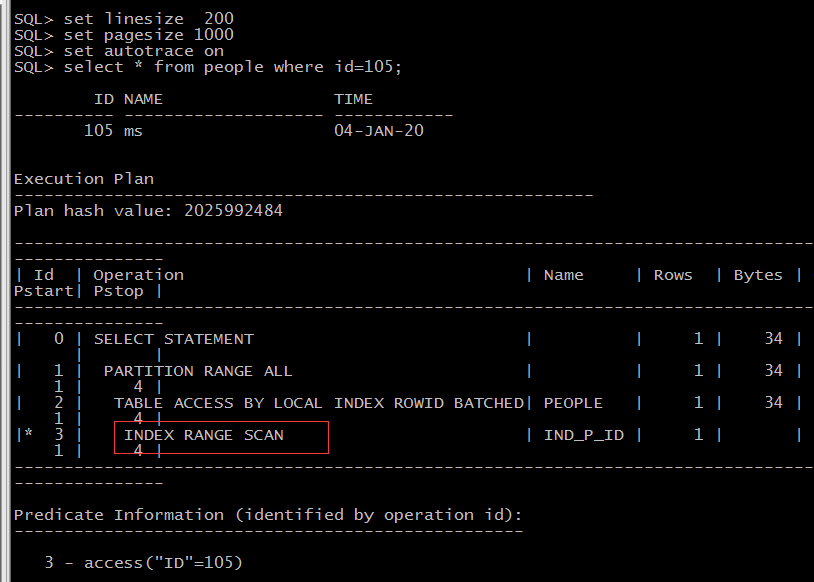
set linesize 200 set pagesize 1000 set autotrace on select * from people where id=23;
6、创建一张临时表并创建索引、插入数据
create table people_tmp ( id number, name varchar2(20), time date ) --创建索引 create index ind_ptmp_id on people_tmp(id) ; --插入数据 declare i number; begin for i in 101..150 loop insert into people_tmp values(i,'ms',to_date('20200104 12:00:00','yyyymmdd hh24:mi:ss')); end loop; end; --查看临时表数据 select * from people_tmp
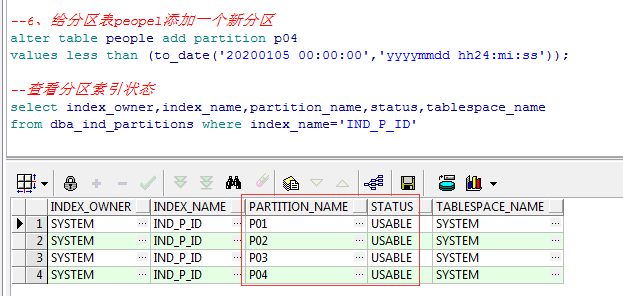
7、给分区表peopel添加一个新分区(后面要把临时表的数据插入到该新分区)
--添加新分区p04 alter table people add partition p04 values less than (to_date('20200105 00:00:00','yyyymmdd hh24:mi:ss')); --查看分区索引状态 select index_owner,index_name,partition_name,status,tablespace_name from dba_ind_partitions where index_name='IND_P_ID'
8、分区转换(使用including indexes的方式把临时表的数据转换到分区表的新分区)
--分区转换 alter table people exchange partition p04 with table people_tmp including indexes; --查看分区索引状态 select index_owner,index_name,partition_name,status,tablespace_name from dba_ind_partitions where index_name='IND_P_ID'
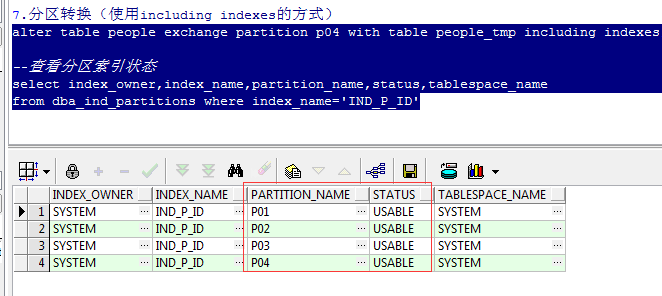
注:可以看到装换前后,分区索引都是有效的
9、查看新分区的数据
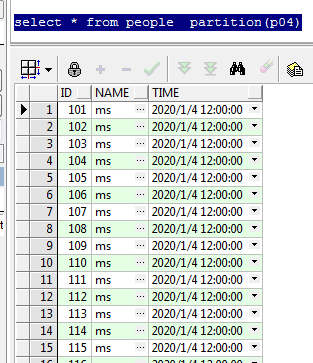
10、查询新分区的数据,看执行计划是否走索引
set linesize 200 set pagesize 1000 set autotrace on select * from people where id=105;