LOL官网英雄资料:https://lol.qq.com/data/info-heros.shtml
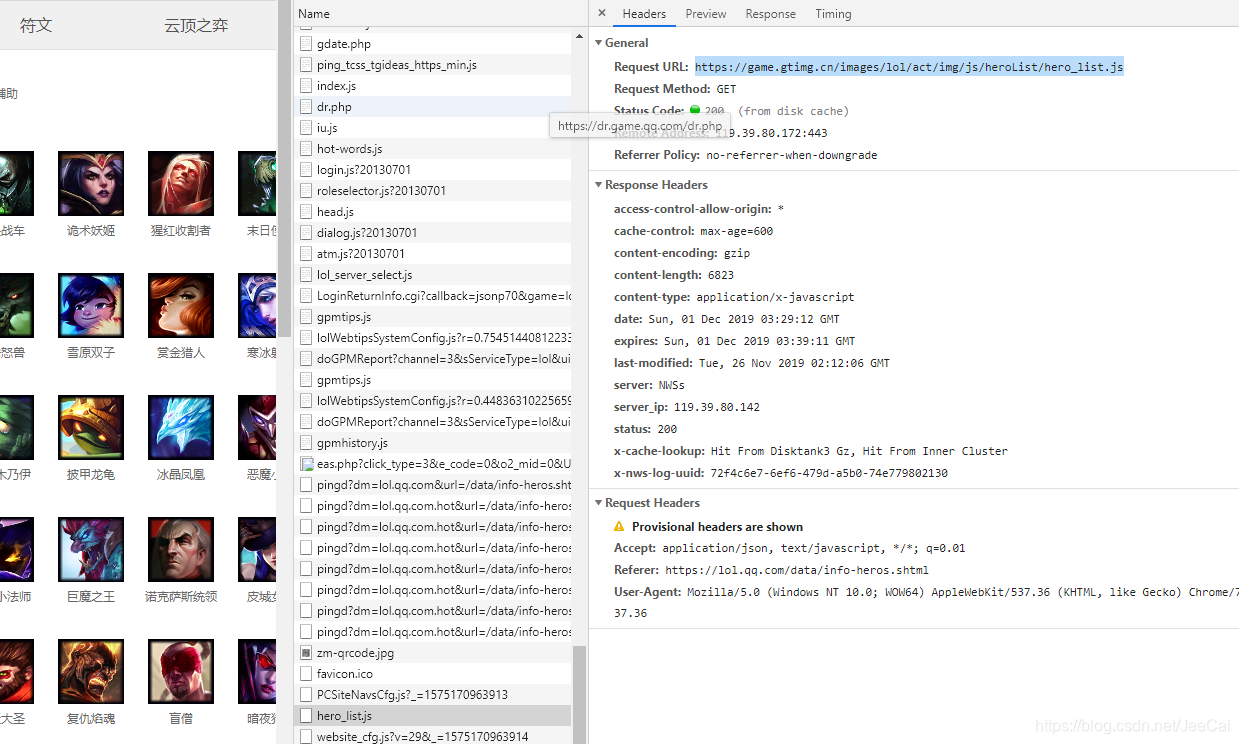
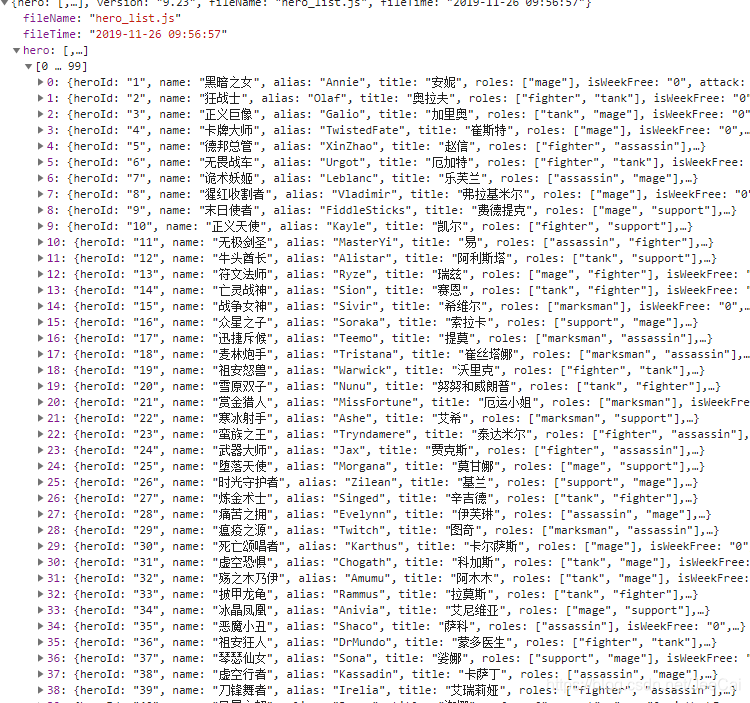
找到英雄列表的json文件(hero_list.js),对应的url(重要)。点击preview预览窗体,看到里面是json的格式,对应有hero_Id,name。
获取英雄和id
def get_hero():
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
res = requests.get(url=url).json()
for hero in res['hero']:
hero_id = hero['heroId']
# skin_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/'+hero_id+'.js'
skin_url = f'https://game.gtimg.cn/images/lol/act/img/js/hero/{hero_id}.js'
获取皮肤图片并以英雄名字保存
def get_link(url):
res = requests.get(url=url).json()
for skin in res['skins']:
info = skin.get('mainImg')
if not info:
# 如果不是皮肤,则跳过当前循环
continue
item = {}
item['heroName'] = skin['heroName']
# 名字中有 / 替换成 _
item['skinName'] = skin['name'].replace('/', '_')
item['link'] = skin['mainImg']
# 英雄名字的文件夹
hero_path = './imgxx/' + item['heroName'] + '/'
if not os.path.exists(hero_path):
# 如果文件夹不存在,则创建
os.makedirs(hero_path)
res = requests.get(url=item['link'])
# 以皮肤名命名图片
with open(hero_path + item['skinName'] + '.jpg', 'wb') as f:
f.write(res.content)
层层调用,if name == ‘main’: 是以本文件名为主函数,调用本地的函数
if __name__ == '__main__':
get_hero()